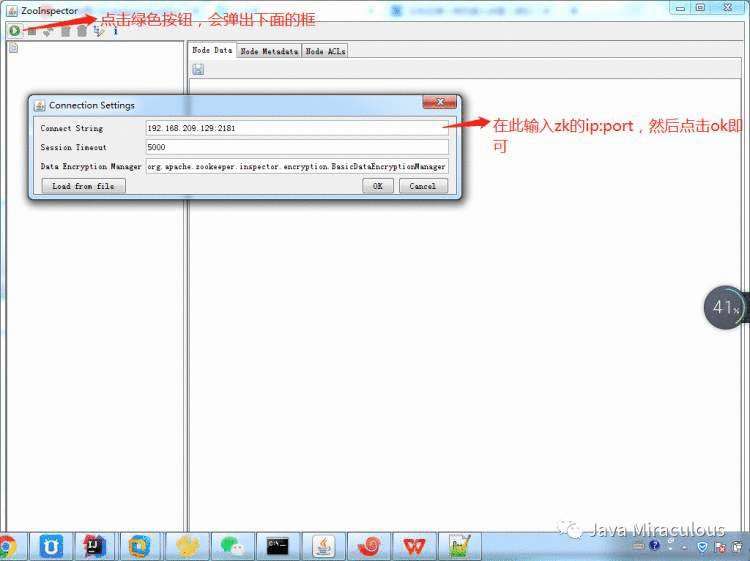
一、ZooInspector
二、通过java客户端操作zk
2.1、基于zk的原生客户端进行操作
org.apache.zookeeper zookeeper 3.5.5
org.apache.zookeeper
zookeeper
3.5.5
package com.ayo.zk;import org.apache.zookeeper.KeeperException;import org.apache.zookeeper.WatchedEvent;import org.apache.zookeeper.Watcher;import org.apache.zookeeper.ZooKeeper;import org.junit.Before;import org.junit.Test;import java.io.IOException;import java.util.List;public class ZkTest { ZooKeeper zooKeeper = null; ** * 初始化方法,构造zk客户端 */ @Before public void init() throws IOException { zk的地址,多个用,隔开 String cOnnectString= "192.168.209.129:2181"; ** * 会话超时时间,单位毫秒 */ int sessiOnTimeout= 60000; 全局监听,缺点,如果多个节点同时发生变化,就不太好处理了 zooKeeper = new ZooKeeper(connectString, sessionTimeout, watchedEvent -> System.out.println("全局监听: " + watchedEvent.getPath())); } ** * 运行前看下linux中的防火墙是否开启,开启的话需要关闭,或者在防火墙中打开2181端口也可以 * * 测试不添加监听 * @throws KeeperException * @throws InterruptedException */ @Test public void testGet() throws KeeperException, InterruptedException { ** * watch:是否监听,true:是,false:否 * 注意,从zk中取出来的数据都是字节数组,需要自己转换为想要的格式 */ byte[] data = zooKeeper.getData("/ayo", false, null); String s = new String(data); System.out.println(s); } ** * 测试添加监听 * @throws KeeperException * @throws InterruptedException */ @Test public void testGet2() throws KeeperException, InterruptedException { ** * watch:是否监听,true:是,false:否,这里触发的是全局监听 * 注意,从zk中取出来的数据都是字节数组,需要自己转换为想要的格式 */ byte[] data = zooKeeper.getData("/ayo", true, null); String s = new String(data); System.out.println(s); 休眠一分钟,为了观察监听器打印 Thread.sleep(60000); } ** * 测试添加自定义的监听 * @throws KeeperException * @throws InterruptedException */ @Test public void testGet3() throws KeeperException, InterruptedException { ** * watch:直接new Watcher() */ byte[] data = zooKeeper.getData("/ayo", new Watcher() { public void process(WatchedEvent watchedEvent) { try { 因为监听一次就失效,所以需要重新添加监听,类似递归 zooKeeper.getData(watchedEvent.getPath(), this, null); } catch (KeeperException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("自定义的监听: " + watchedEvent.getPath()); } }, null); String s = new String(data); System.out.println(s); 休眠一分钟,为了观察监听器打印 Thread.sleep(60000); } ** * 获取子节点,无监听 * @throws KeeperException * @throws InterruptedException */ @Test public void testGet4() throws KeeperException, InterruptedException { List children = zooKeeper.getChildren("/ayo", false); children.stream().forEach(System.out::println); } ** * 获取子节点, 同时监听子节点的变化 * @throws KeeperException * @throws InterruptedException */ @Test public void testGet5() throws KeeperException, InterruptedException { List children = zooKeeper.getChildren("/ayo", watchedEvent -> System.out.println(watchedEvent.getPath())); children.stream().forEach(System.out::println); }}
package com.ayo.zk;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
public class ZkTest {
ZooKeeper zooKeeper = null;
**
* 初始化方法,构造zk客户端
*/
@Before
public void init() throws IOException {
zk的地址,多个用,隔开
String cOnnectString= "192.168.209.129:2181";
* 会话超时时间,单位毫秒
int sessiOnTimeout= 60000;
全局监听,缺点,如果多个节点同时发生变化,就不太好处理了
zooKeeper = new ZooKeeper(connectString, sessionTimeout, watchedEvent -> System.out.println("全局监听: " + watchedEvent.getPath()));
}
* 运行前看下linux中的防火墙是否开启,开启的话需要关闭,或者在防火墙中打开2181端口也可以
*
* 测试不添加监听
* @throws KeeperException
* @throws InterruptedException
@Test
public void testGet() throws KeeperException, InterruptedException {
* watch:是否监听,true:是,false:否
* 注意,从zk中取出来的数据都是字节数组,需要自己转换为想要的格式
byte[] data = zooKeeper.getData("/ayo", false, null);
String s = new String(data);
System.out.println(s);
* 测试添加监听
public void testGet2() throws KeeperException, InterruptedException {
* watch:是否监听,true:是,false:否,这里触发的是全局监听
byte[] data = zooKeeper.getData("/ayo", true, null);
休眠一分钟,为了观察监听器打印
Thread.sleep(60000);
* 测试添加自定义的监听
public void testGet3() throws KeeperException, InterruptedException {
* watch:直接new Watcher()
byte[] data = zooKeeper.getData("/ayo", new Watcher() {
public void process(WatchedEvent watchedEvent) {
try {
因为监听一次就失效,所以需要重新添加监听,类似递归
zooKeeper.getData(watchedEvent.getPath(), this, null);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
System.out.println("自定义的监听: " + watchedEvent.getPath());
}, null);
* 获取子节点,无监听
public void testGet4() throws KeeperException, InterruptedException {
List children = zooKeeper.getChildren("/ayo", false);
children.stream().forEach(System.out::println);
* 获取子节点, 同时监听子节点的变化
public void testGet5() throws KeeperException, InterruptedException {
List children = zooKeeper.getChildren("/ayo", watchedEvent -> System.out.println(watchedEvent.getPath()));
2.2、Apache curator
2.2.1、初始化客户端
2.2.3、监听本节点的数据变化
2.2.4、监听子节点的数据变化
2.2.5、删除节点
2.2.6、附录完整代码
org.apache.curator curator-x-discovery 2.5.0
org.apache.curator
curator-x-discovery
2.5.0
package com.ayo.zk;import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.framework.recipes.cache.*;import org.apache.curator.retry.ExponentialBackoffRetry;import org.junit.Before;import org.junit.Test;/** * 测试Zookeeper CuratorFramework 框架 */public class CuratorFrameworkTest { CuratorFramework curator = null; /** * 初始化客户端 * * retryPolicy参数是指在连接ZK服务过程中重新连接测策略. * 在它的实现类ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries)中, * baseSleepTimeMs参数代表两次连接的等待时间,maxRetries参数表示最大的尝试连接次数 */ @Before public void init(){ RetryPolicy policy = new ExponentialBackoffRetry(1000, 10); /** * CuratorFramework示例创建完成,代表ZooKeeper已经连接成功 */ curator = CuratorFrameworkFactory.builder().connectString("192.168.209.129:2181") .sessionTimeoutMs(2000).retryPolicy(policy).build(); /** * 调用start()方法打开连接,在使用完毕后调用close()方法关闭连接 */ curator.start(); } /** * 创建节点并给节点写入数据 */ @Test public void createNode() throws Exception { curator.create().forPath("/zhubajie"); curator.setData().forPath("/zhubajie", "八戒老帅了".getBytes("GBK")); curator.create().forPath("/zhubajie/son"); curator.setData().forPath("/zhubajie/son", "所以它儿子也很帅啊".getBytes("GBK")); } /** * 删除节点 */ @Test public void deleteNode() throws Exception { curator.delete().forPath("/zhubajie"); } /** * 监听本节点的数据变化 */ @Test public void testWatch() throws Exception { final NodeCache nodeCache = new NodeCache(curator, "/zhubajie", false); nodeCache.getListenable().addListener(new NodeCacheListener() { public void nodeChanged() throws Exception { /** * 在这个地方实现你自己的逻辑,这里以打印节点信息为例 */ System.out.println("本节点的数据发生变化,路径为" + nodeCache.getCurrentData().getPath() + ",数据变为" + new String(nodeCache.getCurrentData().getData(), "GBK")); } }); nodeCache.start(); /** * 让程序休眠,观察打印情况 */ Thread.sleep(60000); } /** * 监听子节点的增加或者删除或者数据变化 */ @Test public void testWatchChild() throws Exception { PathChildrenCache pathChildrenCache = new PathChildrenCache(curator, "/zhubajie", true); pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { public void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent pathChildrenCacheEvent) throws Exception { /** * 在这个地方实现你自己的逻辑,这里以打印节点信息为例 */ System.out.println("子节点的数据发生变化,路径为" + pathChildrenCacheEvent.getData().getPath() + ",数据变为" + new String(pathChildrenCacheEvent.getData().getData(), "GBK")); } }); pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT); /** * 让程序休眠,观察打印情况 */ Thread.sleep(60000); }}
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.*;
import org.apache.curator.retry.ExponentialBackoffRetry;
/**
* 测试Zookeeper CuratorFramework 框架
public class CuratorFrameworkTest {
CuratorFramework curator = null;
* 初始化客户端
* retryPolicy参数是指在连接ZK服务过程中重新连接测策略.
* 在它的实现类ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries)中,
* baseSleepTimeMs参数代表两次连接的等待时间,maxRetries参数表示最大的尝试连接次数
public void init(){
RetryPolicy policy = new ExponentialBackoffRetry(1000, 10);
* CuratorFramework示例创建完成,代表ZooKeeper已经连接成功
curator = CuratorFrameworkFactory.builder().connectString("192.168.209.129:2181")
.sessionTimeoutMs(2000).retryPolicy(policy).build();
* 调用start()方法打开连接,在使用完毕后调用close()方法关闭连接
curator.start();
* 创建节点并给节点写入数据
public void createNode() throws Exception {
curator.create().forPath("/zhubajie");
curator.setData().forPath("/zhubajie", "八戒老帅了".getBytes("GBK"));
curator.create().forPath("/zhubajie/son");
curator.setData().forPath("/zhubajie/son", "所以它儿子也很帅啊".getBytes("GBK"));
* 删除节点
public void deleteNode() throws Exception {
curator.delete().forPath("/zhubajie");
* 监听本节点的数据变化
public void testWatch() throws Exception {
final NodeCache nodeCache = new NodeCache(curator, "/zhubajie", false);
nodeCache.getListenable().addListener(new NodeCacheListener() {
public void nodeChanged() throws Exception {
* 在这个地方实现你自己的逻辑,这里以打印节点信息为例
System.out.println("本节点的数据发生变化,路径为"
+ nodeCache.getCurrentData().getPath()
+ ",数据变为" + new String(nodeCache.getCurrentData().getData(), "GBK"));
});
nodeCache.start();
* 让程序休眠,观察打印情况
* 监听子节点的增加或者删除或者数据变化
public void testWatchChild() throws Exception {
PathChildrenCache pathChildrenCache = new PathChildrenCache(curator, "/zhubajie", true);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
public void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent pathChildrenCacheEvent) throws Exception {
System.out.println("子节点的数据发生变化,路径为"
+ pathChildrenCacheEvent.getData().getPath()
+ ",数据变为" + new String(pathChildrenCacheEvent.getData().getData(), "GBK"));
pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
三、zk集群
3.1、在另外两台机器上也安装下zk,步骤看上一篇文章即可,传送门:初识zookeeper。
3.2、配置文件修改
3.3、分别启动三个zk并查看状态
3.4、查看数据同步情况
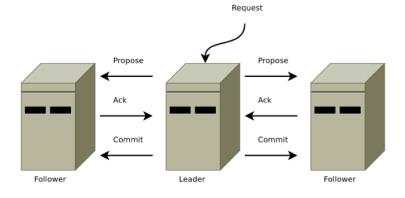
3.5、zk集群中的角色
角色
描述
leader
主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。
follower
子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并用拥有投票权。
observer
次级子节点,又名观察者。用于读取数据,与fllower区别在于没有投票权,不能选为主节点。并且在计算集群可用状态时不会将observer计算入内。
3.6、zk的选举时机和选举流程



























 京公网安备 11010802041100号
京公网安备 11010802041100号