word2vec由google在2013年推出,其中获取词向量的方法CBOW和Skip-gram模型在《Efficient Estimation of Word Representations in Vector Space》中进行了阐述和介绍,高效训练模型的策略Hierarchical Softmax和Negative Sampling则在《Distributed Representations of Words and Phrases and their Compositionality》做了陈述。由于Mikolov发表的的这两篇论文不是很好理解,所以可以参考Xin Rong的《word2vec parameter learning explained》,也可以直接看peghoty在博客园的发表的文章《word2vec中的数学原理详解》。网上有大量关于word2vec的文章,但主要还是和其数学原理相关的内容,本文主要是阅读和解析Mikolov在github上开源的源码,其中也参考了别人的博客以及py版本(如果对py比较熟的建议看这个,感觉更清晰一些)的实现,这部分会在文末进行列举。word2vec的源码里涉及到大量的文件读取,构建词表和hash表的操作以及对应的查询、比较、排序等辅助函数,这部分本文暂不做详细分析,本文会专注于其中的Hierarchical Softmax,Negative Sampling,Skip-gram以及CBOW的实现中。一般我读源码主要从main函数开始,因为这块包含了整个代码的运行流程,从main函数入手,再对每一步骤涉及的类和方法进行阅读。word2vec中涉及训练的代码在TrainModel中,这部分的重点我认为是:网络初始化参数模块和训练模块,前者包括InitNet、CreateBinaryTree、InitUnigramTable,后者则是对应代码里的TrainModelThread,主要为CBOW和Skip-gram,下面我将对这两块分别进行解析。
01
网络初始化参数
这一块内容主要涉及Huffman树和UnigramTable的的构建,分别为后续的Hierarchical Softmax和Negative Sampling的前置基础工作。
1、InitNet
该部分主要初始化一个projection layer的网络结构,其中vocab_size为词表长度,layer1_size为输出的词向量长度,如果使用Hierarchical Softmax,即hs=1,则会初始化一个vocab_size*layer1_size全0的辅助向量syn1,用来存储构建好的Haffman树中的非叶子节点。若使用Negative Sampling,则会初始化一个vocab_size*layer1_size全0的辅助向量syn1neg。syn0则为我们最后需要的词向量,初始化为[-0.5/layer1_size, 0.5/layer1_size]区间内vocab_size*layer1_size长度的随机向量。具体的代码如下:
void InitNet() { long long a, b; unsigned long long next_random = 1; a = posix_memalign((void **)&syn0, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn0 == NULL) {printf("Memory allocation failed\n"); exit(1);} if (hs) { a = posix_memalign((void **)&syn1, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn1 == NULL) {printf("Memory allocation failed\n"); exit(1);} for (a = 0; a 0) { a = posix_memalign((void **)&syn1neg, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn1neg == NULL) {printf("Memory allocation failed\n"); exit(1);} for (a = 0; a 2、CreateBinaryTree
该部分就是创建Haffman二叉树,主要是为Hierarchical Softmax方法的实现提供相对应的数据结构基础。Haffman树建立的伪代码如下:输入:权值为(?1,?2,...??)的?个节点输出:对应的Haffman树1)将(?1,?2,...??)看做是有?棵树的森林,每个树仅有一个节点。;2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和;3) 将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林;4)重复步骤2)和3)直到森林里只有一棵树为止。根据Haffman树的特性,权值越高的词其二叉树上的路径越短,即二进制编码越短,且更靠近根节点,这也符合我们的业务认知,即越常用的词拥有更短的编码,word2vec里创建Haffman树的代码如下。void CreateBinaryTree() { long long a, b, i, min1i, min2i, pos1, pos2, point[MAX_CODE_LENGTH]; char code[MAX_CODE_LENGTH]; long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); for (a = 0; a = 0) { if (count[pos1] = 0) { if (count[pos1] 首先我们需要定义point和code,其中point用来存储一个词到根节点的Haffman树路径,code用来存储一个词的Haffman编码。代码里同时也定义了count数组、binary数组以及parent_node数组,长度均为vocab_size*2+1, 其中count数组前vocab_size为Haffman树的叶子节点,初始化为词表中全部单词的词频,它后vocab_size为Haffman树中即将生成的非叶子节点的词频,通过合并子节点的权值得到,初始化为1e15。binary数组记录的是各个节点相对于其父节点的二进制编码,parent_node则记录了每个节点的父节点。接着就是构建Haffman树,注意下这里的输入的count数组的前vocab_size已经按照词频做了降序排序,初始的pos1,pos2分别为词表中词频最低词和第一个1e15的索引,后面通过对比当前的pos1和pos2对应单词的词频大小,来更新作为当前词频(包括合并后)最小和次小节点的索引min1i、min2i。这边以原始序列{'u': 7, 'v': 8, 'w': 9, 'x': 10, 'y': 19}为例,对应的初始化词频为[19, 10, 9, 8, 7],对应的count数组为[19, 10, 9, 8, 7, 1e15, 1e15, 1e15, 1e15, 1e15]。第一轮迭代,a为0,pos1为4,pos2为5,count[pos1]为7,count[pos2]为1e15,此时count[pos1]
第二轮迭代,a为1,pos1为2,pos2为5,count[pos1]为9,count[pos2]为15,此时count[pos1]
第三轮迭代,a为2,pos1为0,pos2为5,count[pos1]为19,count[pos2]为15,此时count[pos1] > count[pos2],min1i为5,pos2递增为6,count[pos1]为19,count[pos2]为19,count[pos1] = count[pos2],min2i=6, pos2递增为7,count[5+2]被赋值为count[5]+count[6]=34。
第四轮迭代,a为3,pos1为0,pos2为7,count[pos1]为19,count[pos2]为34,此时count[pos1]
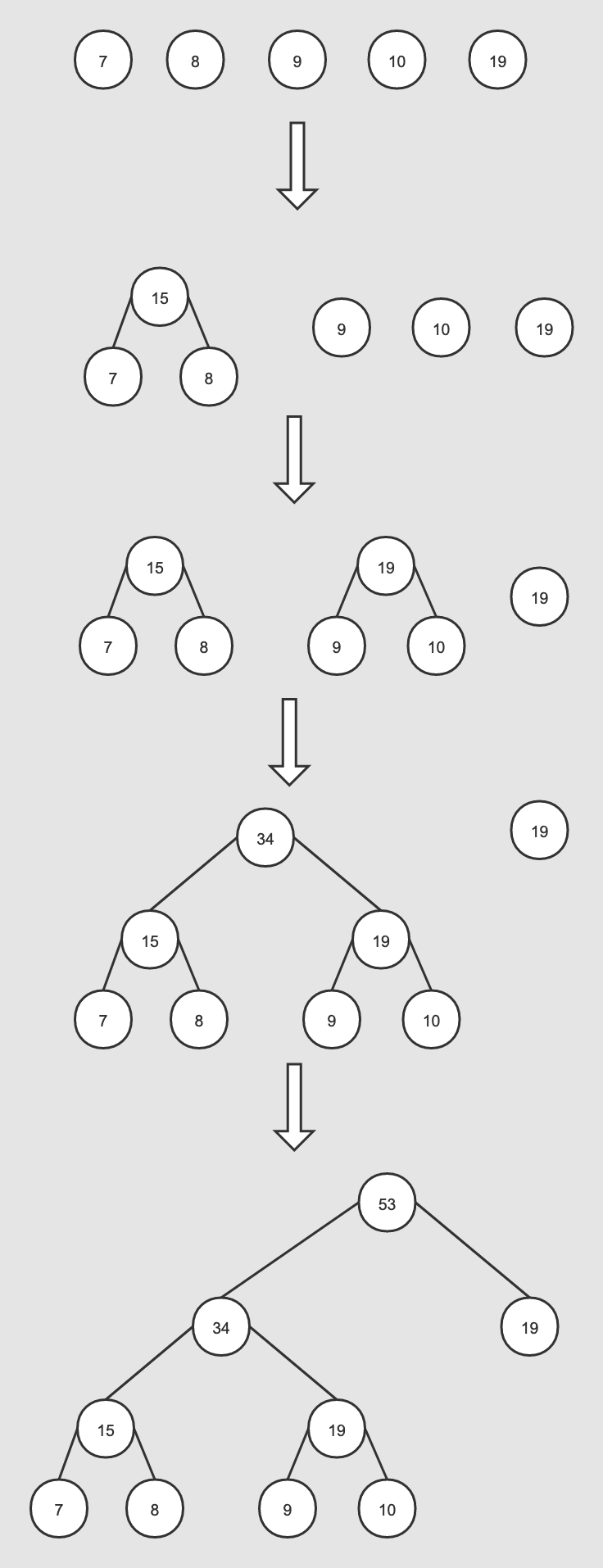
由于是构建Huffman树,所以最多只需进行vocab_size-1次循环操作。整个迭代的过程就是获取最小count[min1i]和次小count[min2i],并合并(求和),然后重复这一步骤直至迭代结束。在每轮迭代中binary数组中索引为min2i会置为1,即词频较低的为1,较高的为0。parent_node里则会将每次迭代中索引为min1i和min2i的元素置为a+vocab_size。接着就是遍历词表里的所有单词,并为每个词分配其在Haffman树中的路径和编码。需要注意的有:设立临时变量b,主要是获取当前词在parent_node里的路径,该路径也直接对应了binary里的索引;
由于Haffman树一共有vocab_size*2-1个节点,所以vocab_size*2-2为根节点,代码里以此为循环的终止条件,即路径走到了根节点;
由于Haffman编码和路径是从根节点到叶子结点的,因此需要对之前得到的code和point进行reverse操作, 路径那边也要减去vocab_size。
以上述的序列中的'w'为例,对应的词频为9,对应的索引为2,即a=2,之前的binary序列为[0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0],parent_node为[8, 6, 6, 5, 5, 7, 7, 8, 0, 0, 0],对应得出的w的code为[0, 1, 1],point=[2, 6, 7],由于Haffman路径中存储的中间节点编号要在现在得到的基础上减去vocab_size,即不算叶子结点,仅取单纯在中间节点中的编号,所以此时的根节点的编号为(vocab_size*2-2) - vocab_size = vocab_size - 2,具体在此例为3,逆序后vocab[2].code为[1, 1, 0], vocab[2].point为[3, 2, 1, -3]。至此每个词对应的Haffman编码和路径均已计算完毕。3、InitUnigramTable
为词表中的每个词构建一个幂律分布(power law distribution)表,用于后续的负采样,这边对词频取0.75次幂实际上属于一种平滑策略,缩小词与词之间的词频差距,具体代码如下。void InitUnigramTable() { int a, i; double train_words_pow = 0; double d1, power = 0.75; table = (int *)malloc(table_size * sizeof(int)); for (a = 0; a d1) { i++; d1 += pow(vocab[i].cn, power) / train_words_pow; } if (i >= vocab_size) i = vocab_size - 1; }}初始化的table_size为1e8,然后遍历词表, train_words_pow为每个词对应的词频cn^0.75的累加。接着计算单个词对于train_words_pow的比率d1,如果a/table_size一直不超过当前词的d1的话,i就不会递增,这就意味着当前词会一直占据a+n-a个位置, 否则会累加更新d1的值,累加的原因是不需要从头开始比较,a位置一直往后,对应的d1应该也在之前的基础上累加,保持相对位置不变,绝对位置的更新。这样每个词都会对应一段区间,在同一个区间的词都是一样的,所以在采样的时候,只需指定neg个索引位置,必然会取到neg个词。 如果词表的长度比UnigramTable小的话,即UnigramTable未能填满,则将未填满的部分用词表中的最后一个词来进行填充。
如果词表的长度比UnigramTable小的话,即UnigramTable未能填满,则将未填满的部分用词表中的最后一个词来进行填充。
02
训练模块
无论是CBOW还是Skip-gram在代码里都使用了下面几个变量,在此先对他们做个介绍:neu1:输入的词向量【在CBOW是窗口中各个词的向量和,在skip-gram是中心词的词向量】,长度为layer1_size,初始化为0,用于更新syn1;
neu1e:长度为layer1_size,初始化为0,用于更新syn0;
alpha:学习率;
last_word:记录当前扫描到的上下文单词索引。

1、CBOW
CBOW需要我们根据上下文的窗口词来预测中心词,这里先计算窗口词向量的和并求均值,cw为窗口长度,建立起中心词和窗口词的关联。for (c = 0; c 1.1 使用Hierarchical Softmax进行训练
根据前文构建的Haffman树,遍历从根节点到当前词的叶子节点路径中所有经过的中间节点,l2为当前遍历到的中间节点的向量在syn1中的位置, f为syn1在l2处对应的neu1在layer1_size范围内的累加,其实本质就是neu1和中间节点向量的内积。这边的codelen即为树深度,循环的时候可以直接过滤掉上述例子'w'对应的point中的-3。接着就是对f做Sigmoid变换处理,这里是维护了一个expTable数组,我们可以根据索引直接查表得知变换的结果。然后再对f和之前得到的每个词的Haffman编码计算误差并进行梯度更新,需要注意的是这里编码为1的节点会被定义成负类,0为正类,即真实label为1-vocab[word].code[d],最后就是更新neu1e和syn1对应位置的向量,其中每一次迭代即为一次逻辑回归,整体其实就是一个利用随机梯度提升来最大化对数似然函数的过程。for (d = 0; d = MAX_EXP) continue; else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; g = (1 - vocab[word].code[d] - f) * alpha; for (c = 0; c 1.2 使用Negative Sampling进行训练
其中negative为负样本的数量&#xff0c;当d为0即获取的是目标词&#xff0c;指定其为正样本&#xff0c;否则就从UnigramTable中随机抽取negative个负样本(不能和当前正样本一样)。这边的l2为syn1neg中目标单词的位置&#xff0c;后面的基本和Hierarchical Softmax一致&#xff0c;不再多做赘述。for (d &#61; 0; d > 16) % table_size]; if (target &#61;&#61; 0) target &#61; next_random % (vocab_size - 1) &#43; 1; if (target &#61;&#61; word) continue; label &#61; 0; } l2 &#61; target * layer1_size; f &#61; 0; for (c &#61; 0; c MAX_EXP) g &#61; (label - 1) * alpha; else if (f <-MAX_EXP) g &#61; (label - 0) * alpha; else g &#61; (label - expTable[(int)((f &#43; MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha; for (c &#61; 0; c 最后我们再根据得到的neu1e来即时地更新syn0&#xff0c;从而获取最终训练得出的vocab_size*layer1_size的词向量。for (a &#61; b; a &#61; sentence_length) continue; last_word &#61; sen[c]; if (last_word &#61;&#61; -1) continue; for (c &#61; 0; c 2、Skip-gram
Skip-gram需要我们根据输入的中心词来预测该单词上下文窗口词&#xff0c;代码里的last_word为当前待预测的上下文单词&#xff0c;l1为当前单词的词向量在syn0的位置&#xff0c;初始化neu1e为0。训练这部分大体和前面一致&#xff0c;区别就在于前面是用neu1[c]来和中间节点向量的内积&#xff0c;而这边直接用syn0[c &#43; l1]替换neu1[c], syn0[c &#43; l1]在这里为单个词的词向量&#xff0c;而neu1[c]则为窗口词向量的平均。另外需要注意的是Skip-gram虽然是给定中心词来预测上下文&#xff0c;但真正在训练的时候仍是用上下文预测中心词。for (a &#61; b; a &#61; sentence_length) continue; last_word &#61; sen[c]; if (last_word &#61;&#61; -1) continue; l1 &#61; last_word * layer1_size; for (c &#61; 0; c &#61; MAX_EXP) continue; else f &#61; expTable[(int)((f &#43; MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; g &#61; (1 - vocab[word].code[d] - f) * alpha; for (c &#61; 0; c 0) for (d &#61; 0; d > 16) % table_size]; if (target &#61;&#61; 0) target &#61; next_random % (vocab_size - 1) &#43; 1; if (target &#61;&#61; word) continue; label &#61; 0; } l2 &#61; target * layer1_size; f &#61; 0; for (c &#61; 0; c MAX_EXP) g &#61; (label - 1) * alpha; else if (f <-MAX_EXP) g &#61; (label - 0) * alpha; else g &#61; (label - expTable[(int)((f &#43; MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha; for (c &#61; 0; c 
代码里的其他一些tricks:读取文件时&#xff0c;每行末尾加入了一个""&#xff0c;便于训练。
如果词表大小超过上限&#xff0c;则做一次词表删减操作,将当前词频小于min_reduce(初始为1)的进行删除&#xff0c;该删除操作在一个while(1)循环里&#xff0c;min_reduce一次循环累加1&#xff0c;保证最大的单词数量不超过vocab_hash_size * 0.7&#xff0c;代码设定的vocab_hash_size &#61; 30000000&#xff0c;即词表最多只能有2100万个词&#xff0c;否则就会一直删除低频词&#xff0c;直至满足这个条件为止, 而expTable的大小为1e8, 还是远超过2100万的&#xff0c;所以不必担心Negative Sampling无法训练的问题。
在初始学习率的基础上&#xff0c;随着实际训练词数的上升&#xff0c;逐步降低当前学习率(自适应调整学习率)&#xff0c;并保证学习率不低于starting_alpha * 0.0001。
对高频词进行随机下采样&#xff0c;丢弃掉一些高频词&#xff0c;类似平滑处理&#xff0c;这样也可以加快训练速度。
句子长度超过MAX_SENTENCE_LENGTH&#xff0c;则做截断处理。
行文至此&#xff0c;word2vec代码里的核心部分基本分析完毕&#xff0c;如对文章有异议&#xff0c;可私信互相探讨&#xff0c;技术之路道阻且长&#xff0c;愿各位仍能保持初心&#xff0c;不断进步&#xff0c;谢谢。参考链接&#xff1a;https://github.com/tmikolov/word2vec/blob/master/word2vec.c
https://github.com/deborausujono/word2vecpy
https://blog.csdn.net/EnochX/article/details/52847696
https://blog.csdn.net/EnochX/article/details/52852271
http://www.hankcs.com/nlp/word2vec.html
https://www.cnblogs.com/pinard/p/7160330.html







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 