最近本人参加了一场NLP文本分类比赛,参赛本意是想将自己掌握的理论知识加以实践,这篇文章就是想对这次参赛经验做一次总结,分享出来与大家交流,起到一个利他的作用。
比赛源码由github链接给出,尽可能给出了源码以及一些讲解-(训练好的模型文件并没有上传, 一些文件直接跑或许会有对应的信息的报错)
最近笔者还更新了huggingface/Transformers的Bert Tutorial哦,Pytorch和Tensorflow的都有~
Transformers Tutorial/tianchi competitiongithub.com
比赛官网:
零基础入门NLP - 新闻文本分类-天池大赛-阿里云天池tianchi.aliyun.com
目录:
- 比赛描述
- Tricks和模型介绍
- 模型融合
- 总结
1. 比赛描述
该比赛面向零基础小白,比赛赛题是匿名数据的文本分类比赛,所谓匿名数据也就是脱敏数据,文字是用数字来表示的,所以该比赛一个重点就是如今比较火的预训练模型: Bert系列可能没办法拿来直接使用,以及Word2Vec和GloVe等词向量也必须选手重新自己训练,所以如果是对整个流程不是很清楚的选手,很建议参加该比赛或者复盘比赛来进一步深入地学习。
1.1 简单数据统计
数据包含3个数据文件
1) 线下用的训练数据train_set.csv;
2) A榜的测试数据test_a.csv;
3) B榜的测试数据test_b.csv;
经过统计,train_set.csv和test_a/b.csv分别包含20w和5w数据,包含将近7000个不同的word,以及每篇文本平均长度为900个字,可以看出文本非常长,这也是本次比赛数据集最关键的特点。
1.2 数据预处理
这里对于竞赛小白还是很重要的,我们首先用9:1的比例划分线下训练集和线下验证集。然后对应TextCNN等等预训练模型之前表现很好的模型,必须将文本进行一个截断,我直接采用了尾部截断的策略,对应那几个模型将每句话截断至2400 (这里的策略是要求这个长度起码覆盖90%/95%的数据)-这里直接用的是tf2.0+的Keras。
对于Bert-small而言,我则是选择了首尾截断,对于每个文本都截断/填充到512的文本长度。然后对于预训练所需要的数据我则是结合了train-set与A榜的测试数据,利用句号 感叹号和问号来对文本进行相应的分割,获取了多个句子。关于标点符号的统计,一般来说,这种统计每个词出现的次数,逗号出现的一般是最多的,其次是句号,剩余的几个出现次数很多的可以先保留记录成字符集合A,因为也有可能是一些真实的文字,然后再对文本的最后一个字符进行统计,基于之前的字符集合A,出现的最多的可能就是问号和感叹号等等。
1.3 词向量预训练
因为本次比赛的数据经过脱敏,因此无法使用外部已经实现好的词向量,需要我们自己训练,比如Word2Vec, GloVe, Fasttext, Bert等等。
Word2Vec我采用的gensim的word2vec进行了相应的训练,fasttext用的facebook的开源的包进行了训练,GloVe我用stanford的开源的脚本修改了sh文件,提取了对应的GloVe vector。(最后关于meta embedding,我选择将200dim的word2vec(skip-gram和CBow没什么特别大的区别啦,我就直接用的CBoW)+200dim的GloVe进行concat作为最后的表达,我并没有选择Fasttext,因为Fasttext和Word2Vec可能相关性会高一些,会弱化word2vec的表达)
-关于Meta Embedding的介绍可见:
https://arxiv.org/pdf/1804.07983.pdfarxiv.org
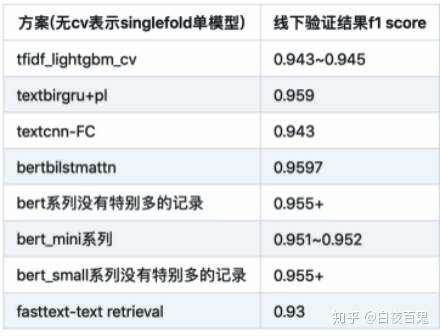
Bert我则是自己利用pytorch-pretrained-bert这个包写了对应的预训练代码,当然之前也尝试过tianchi的Bert-mini, 不过结果一般,可能单模型singlefold也只有0.95这里。鉴于本人GPU资源有限,我就训练了一个Bert-small,具体的Bert版本(small/medium/base/large)可以见这里。
lsh1803544/bertgithub.com
我个人觉得Bert系列的模型如果采用medium和base预训练了的话,可能效果就会超过我,达到比赛的top3。
2. Tricks和模型介绍
首先介绍几个通用且好玩的Trick:
- 对抗验证,我们可以从训练数据中抽取一部分以及从测试数据中抽取一部分提取特征然后用一个简单快捷的模型进行训练,将训练数据对应的label设置为1,将测试数据对应的label设置为0,如果模型分类效果很好,那么可能本次比赛不是很好入手,因为训练集和测试集的分布都不是那么接近了。-具体的代码实现可以见我的github。
- 由于本次比赛是一个文本分类任务,我们还可以通过文本匹配的方式来做,本人尝试了用fasttext提取的测试集的sentence vector对应训练集的sentence vector做了个相似度计算,选择了最接近的训练数据的标签作为对应测试数据的标签,个人觉得这个策略很有意思。
2.1 baseline构建
首先我用tfidf+lightgbm做了一个baseline,当时提交的结果就有0.945这儿了。一般来说比赛都要先搭建一个baseline进行迭代优化。
2.2 本次比赛我使用基于深度学习的模型介绍
首先是基于深度学习的文本分类的模型介绍:史博:基于深度学习的文本分类
我这里就不进行详细的介绍了,如果有感兴趣的同学可以通过阅读各种专栏以及比赛分享进行查阅和理解。
我这里主要采用了
- tianchi: Bert-small + BiLSTM + Attention
- Bert-RNN
- Bert-Multisample Dropout
- Bert-RCNN
- Textcapsule
- TextBiGRU
我首先测试的是TextCNN这个模型,关于这里我也有一些小经验可以和大家分享,这里很推荐大家了解DPCNN这个模型 @夕小瑶 个人在小瑶的分享上学到了很多。
夕小瑶:从经典文本分类模型TextCNN到深度模型DPCNN
这篇文章很详细地讲解了对于文本分类到底是卷积层重要还是分类层重要,我通过这个改进了一下自己的TextCNN,加入了一层全连接层效果有1个点的improvement,虽然最后我并没有选择这个模型hhh。
然后关于Multi-sample Dropout这个是比赛的一个trick啦,经过我个人的实验,总之收敛速度还是很快的,泛化性能可能有少许提升。具体的介绍可以看这里:
https://arxiv.org/pdf/1905.09788.pdfarxiv.org
这些模型大体都是按照这个模式的:
2.3 本次比赛可以尝试的Tricks
- EasyDA: 可以通过随机删除等等做一个简单的数据增强,我看到比赛群分享里有人说这个trick可以提分,但是具体我没有尝试。
- 伪标签: 这个我个人有进行实验,具体的伪标签其实有很多种策略,我只尝试了最最最基础的策略,就是直接将目前表现最好的模型来对test数据集进行一个预测,然后将分类概率大于0.95的样本重新加入到训练样本,进行一个微调的训练,在TextBiGRU等等上面都是有不错的分数提升的,bert好像不明显...(我挺后悔没有早点尝试这个trick的,应该我还可以提分)
- Bert等预训练词向量的对抗训练: 我看了很多比赛有人介绍了这个策略,据说这个trick可以让分数提高1个点,但是鉴于本人才疏学浅,并没有进行后续的尝试。
- Embedding层后面可以加上SpatialDropout,这个我测试过我几个模型的泛化性能都有一定的提升,而且听说也是一个稳定涨分的策略。具体介绍可以查看:在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
- 可以自己尝试一下Test-time Augmentation, 好像也会有一丢丢提升,比如之前用首尾截断的bert,可以尝试融合截断首部 尾部 以及各种长度的输出概率进行blending。
- 我也尝试过要不要Focal Loss, 但是经过我的实验效果不咋地。。。。
2.4 单模型结果
本次比赛Bert效果也没有那么显著超过以前的textbigru等等模型,我想最主要的原因也在于Bert系列需要更多的数据或者更好的策略进行预训练,但我想如果用Bert-medium和base等等应该分数还会有提升,因为我的small我也仅仅预训练了几个epoch,优化的也没有那么好。
3. 模型融合
关于模型融合,一般来说结合几个偏差比较接近+有较大区别的模型集成效果很好,我这里做了一些尝试,拿tfidf的预测概率来做stacking也会有一点点的improvement,当然也可以直接将tfidf feature拿出来用做stacking的feature,说不定也会有改进。
我里面表现的最好的就是bertbilstm_attn+textbigru这两个模型,光是simple average,结果就有0.969+。
后面用oof的stacking做了一些工作,分数最后在B榜有0.9702,但是我在线下验证集的结果有0.971,我想这很可能是训练集和测试集类别分布不一致的原因吧。
4. 总结
本次比赛很基础,很适合对NLP没有什么实践经验的同学入手,对个人的提升还是有不少的!欢迎各位朋友有机会和我一起参加各种比赛,提升自己的实践能力~
本人查看过比赛第一名的方案,其实他们的工作比我简单,他们只是单纯使用了bert-base+对抗训练embedding+bert版本的模型融合就达到了0.973的f1-performance。在这里给大家做这样的讲解希望大家都可以有更好的成长~
参考文献:
1.在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?
2.夕小瑶:从经典文本分类模型TextCNN到深度模型DPCNN
3.Multi-sample Dropout论文
4.史博:基于深度学习的文本分类
5.各种Bert版本-mini/small/medium/base/large
6.Meta Embedding论文












 京公网安备 11010802041100号
京公网安备 11010802041100号