作者:小菜刀丶 | 来源:互联网 | 2023-09-04 16:49
篇首语:本文由编程笔记#小编为大家整理,主要介绍了CVPROralTensorFlow实现StarGAN代码全部开源,1天训练完相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了CVPR OralTensorFlow实现StarGAN代码全部开源,1天训练完相关的知识,希望对你有一定的参考价值。

新智元编译
来源:github
【新智元导读】StarGAN 是去年 11 月由香港科技大学、新泽西大学和韩国大学等机构的研究人员提出的一个图像风格迁移模型,是一种可以在同一个模型中进行多个图像领域之间的风格转换的对抗生成方法。近日,有研究人员将 StarGAN 在 TensorFlow 上实现的全部代码开源,相关论文获 CVPR 2018 Oral。

StarGAN 是去年 11 月由香港科技大学、新泽西大学和韩国大学等机构的研究人员提出的一个图像风格迁移模型,是一种可以在同一个模型中进行多个图像领域之间的风格转换的对抗生成方法。近日,有研究人员将 StarGAN 在 TensorFlow 上实现的全部代码开源,相关论文获 CVPR 2018 Oral。
看代码之前,我们先来回顾一下 StarGAN 的原始论文。
图像到图像转换(image-to-image translation)这个任务是指改变给定图像的某一方面,例如,将人的面部表情从微笑改变为皱眉。在引入生成对抗网络(GAN)之后,这项任务有了显着的改进,包括可以改变头发颜色,改变风景图像的季节等等。
给定来自两个不同领域的训练数据,这些模型将学习如何将图像从一个域转换到另一个域。我们将属性(attribute)定义为图像中固有的有意义的特征,例如头发颜色,性别或年龄等,并且将属性值(attribute value)表示为属性的一个特定值,例如头发颜色的属性值可以是黑色 / 金色 / 棕色,性别的属性值是男性 / 女性。我们进一步将域(domain)表示为共享相同属性值的一组图像。例如,女性的图像可以代表一个 domain,男性的图像代表另一个 domain。
一些图像数据集带有多个标签属性。例如,CelebA 数据集包含 40 个与头发颜色、性别和年龄等面部特征相关的标签,RaFD 数据集有 8 个面部表情标签,如 “高兴”、“愤怒”、“悲伤” 等。这些设置使我们能够执行更有趣的任务,即多域图像到图像转换(multi-domain image-to-image translation),即根据来自多个域的属性改变图像。

图 1:通过从 RaFD 数据集学习迁移知识,应用到 CelebA 的多域图像到图像转换结果。第一列和第六列显示输入图像,其余列是产生的 StarGAN 图像。注意,图像是由一个单一模型网络生成的,面部表情标签如生气、高兴、恐惧是从 RaFD 学习的,而不是来自 CelebA。
在图 1 中,前 5 列显示了一个 CelebA 的图像是如何根据 4 个域(“金发”、“性别”、“年龄” 和 “白皮肤”)进行转换。我们可以进一步扩展到训练来自不同数据集的多个域,例如联合训练 CelebA 和 RaFD 图像,使用在 RaFD 上训练的特征来改变 CelebA 图像的面部表情,如图 1 最右边的列所示。
然而,现有模型在这种多域图像转换任务中既效率低,效果也不好。它们的低效性是因为在学习 k 个域之间的所有映射时,必须训练 k(k-1)个生成器。图 2 说明了如何训练 12 个不同的生成器网络以在 4 个不同的域中转换图像。
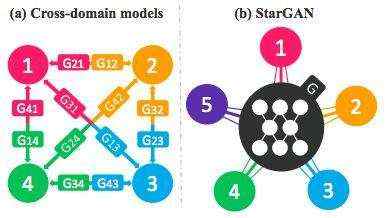
图 2: StarGAN 模型与其他跨域模型的比较。(a)为处理多个域,应该在每两个域之间都建立跨域模型。(b)StarGAN 用单个生成器学习多域之间的映射。该图表示连接多个域的拓扑图。
为了解决这类问题,我们提出了 StarGAN,这是一个能够学习多个域之间映射的生成对抗网络。如图 2(b) 所示,我们的模型接受多个域的训练数据,仅使用一个生成器就可以学习所有可用域之间的映射。
这个想法很简单。我们的模型不是学习固定的转换(例如,将黑头发变成金色头发),而是将图像和域信息作为输入,学习将输入的图像灵活地转换为相应的域。我们使用一个标签来表示域信息。在训练过程中,我们随机生成一个目标域标签,并训练模型将输入图像转换为目标域。这样,我们可以控制域标签并在测试阶段将图像转换为任何想要的域。
我们还介绍了一种简单但有效的方法,通过在域标签中添加一个掩码向量(mask vector)来实现不同数据集域之间的联合训练。我们提出的方法可以确保模型忽略未知的标签,并关注特定数据集提供的标签。这样,我模型就可以很好地完成任务,比如利用从 RaFD 中学到的特征合成 CelebA 图像的面部表情,如图 1 最右边的列所示。据我们所知,这是第一个在不同的数据集上成功地完成多域图像转换的工作。
总结而言,这个研究的贡献如下:
提出 StarGAN,这是一个新的生成对抗网络,只使用一个生成器和一个鉴别器来学习多个域之间的映射,能有效地利用所有域的图像进行训练。
演示了如何通过使用 mask vector 来学习多个数据集之间的多域图像转换,使 StarGAN 能够控制所有可用的域标签。
使用 StarGAN 在面部属性转换和面部表情合成任务提供了定性和定量的结果,优于 baseline 模型
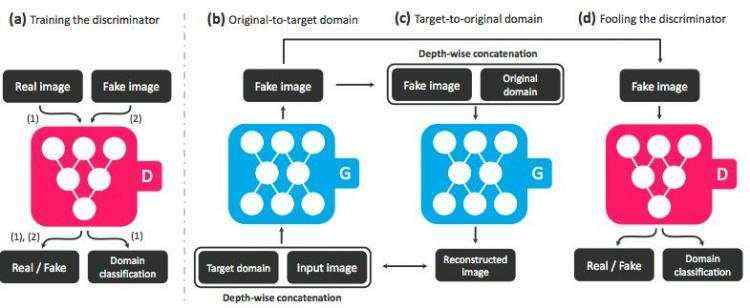
图 3:StarGAN 的概观,包含两个模块:一个鉴别器 D 和一个生成器 G。(a)D 学习区分真实图像和假图像,并将真实图像分类到相应的域。(b)G 接受图像和目标域标签作为输入并生成假图像。 (c)G 尝试在给定原始域标签的情况下,从假图像中重建原始图像。(d)G 尝试生成与真实图像非常像的假图像,并通过 D 将其分类为目标域。
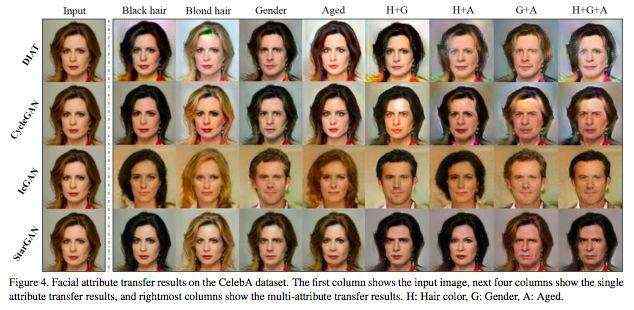
图4:CelebA 数据集上面部属性转换的结果对凯勒巴数据集。第1列显示输入图像,后4列显示单个属性转换的结果,最右边的列显示多个属性的转换结果。H:头发的颜色;G:性别;A:年龄

图5:RaFD 数据集上面部表情合成的结果

图6:StarGAN-SNG 和 StarGAN-JNT 在 CelebA 数据集上的面部表情合成结果。
要求:
Tensorflow 1.8
Python 3.6
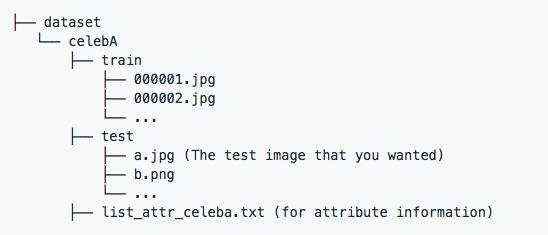
> python download.py celebA
下载数据集
> python download.py celebA
训练
测试
预训练模型
结果 (128x128, wgan-gp)
女性

男性
预训练权重:https://drive.google.com/open?id=1ezwtU1O_rxgNXgJaHcAynVX8KjMt0Ua-
训练时间:少于 1 天
硬件:GTX 1080Ti
阅读更多:
【加入社群】





 京公网安备 11010802041100号
京公网安备 11010802041100号