作者:潇潇沐林风_921 | 来源:互联网 | 2023-05-18 03:51
本人在Zuora工作的时候,几乎所有的异步业务逻辑都使用ActiveMQ,对AMQ也算颇为熟悉。现如今每天和Kafka打交道,对kafka也算驾驭的不错。现在基于这两者做个小比较。首先,Active
本人在Zuora工作的时候,几乎所有的异步业务逻辑都使用ActiveMQ,对AMQ也算颇为熟悉。现如今每天和Kafka打交道,对kafka也算驾驭的不错。现在基于这两者做个小比较。
首先,Active MQ与Kafka的相同点只有一个,就是都是消息中间件。其他没有任何相同点。
- 关于consume
Active mq是完全遵循JMS标准的。amq无论在standalone还是分布式的情况下,都会使用mysql作为存储,多一个consumer线程去消费多个queue, 消费完的message会在mysql中被清理掉。作为AMQ的consume clinet的多个consumer线程去消费queue,AMQ Broker会接收到这些consume线程,阻塞在这里,有message来了就会进行消费,没有消息就会阻塞在这里。具体消费的逻辑也就是处理这些consumer线程都是AMQ Broker那面处理。其实就是queue的message存在mysql,多个线程监听这个queue,
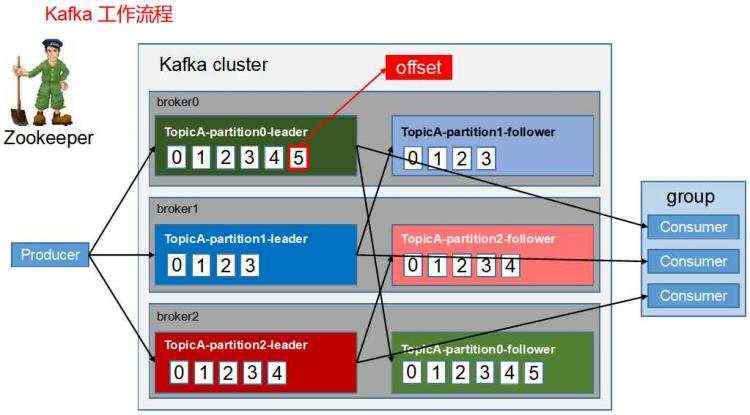
Kafka有consumer group的概念。一个consumer group下有多个consumer,每个consumer都是一个线程,consumer group是一个线程组。每个线程组consumer group之间互相独立。同一个partition中的一个message只能被一个consumer group下的一个consumer线程消费,因为消费完了这个consumer group下的这个consumer对应的这个partition的offset就+1了,这个consumer group下的其他consumer还是这个consumer都不能在消费了。 但是另外一个consumer group是完全独立的,可以设置一个from的offset位置,重新消费这个partition。
kafka是message都存在partition下的segment文件里面,有offsite偏移量去记录那条消费了,哪条没消费。某个consumer group下consumer线程消费完就会,这个consumer group 下的这个consumer对应这个partition的offset+1,kafka并不会删除这条已经被消费的message。其他的consumer group也可以再次消费这个message。在high level api中offset会自动或手动的提交到zookeeper上(如果是自动提交就有可能处理失败或还没处理完就提交offset+1了,容易出现下次再启动consumer group的时候这条message就被漏了),也可以使用low level api,那么就是consumer程序中自己维护offset+1的逻辑。
kafka中的message会定期删除。
- 关于存储结构
ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB
Kafka是文件存储,每个topic有多个partition,每个partition有多个replica副本(每个partition和replica都是均匀分配在不同的kafka broker上的)。每个partition由多个segment文件组成。这些文件是顺序存储的。因此读取和写入都是顺序的,因此,速度很快,省去了磁盘寻址的时间。
很多系统、组件为了提升效率一般恨不得把所有数据都扔到内存里,然后定期flush到磁盘上;而Kafka决定直接使用页面缓存;但是随机写入的效率很慢,为了维护彼此的关系顺序还需要额外的操作和存储,而线性的顺序写入可以避免磁盘寻址时间,实际上,线性写入(linear write)的速度大约是300MB/秒,但随即写入却只有50k/秒,其中的差别接近10000倍。这样,Kafka以页面缓存为中间的设计在保证效率的同时还提供了消息的持久化,每个consumer自己维护当前读取数据的offset(也可委托给zookeeper),以此可同时支持在线和离线的消费。
- 关于使用场景与吞吐量
ActiveMQ用于企业消息中间件,使得业务逻辑和前端处理逻辑解耦。AMQ的吞吐量不大,zuora的AMQ就是用作jms来使用。AMQ吞吐量不够,并且持久化message数据通过jdbc存在mysql,写入和读取message性能太低。
Kafka的吞吐量非常大
TalkingData的kafka吞吐量非常大,并且会堆积message数据, kafka更多的作为存储来用,可以淤积数据。
- 关于消息传递模型
传统的消息队列最少提供两种消息模型,一种P2P,一种PUB/SUB
Kafka并没有这么做,它提供了一个消费者组的概念,一个消息可以被多个消费者组消费,但是只能被一个消费者组里的一个消费者消费,这样当只有一个消费者组时就等同与P2P模型,当存在多个消费者组时就是PUB/SUB模型
- push/pull 模型
对于消费者而言有两种方式从消息中间件获取消息:
①Push方式:由消息中间件主动地将消息推送给消费者,采用Push方式,可以尽可能快地将消息发送给消费者;②Pull方式:由消费者主动向消息中间件拉取消息,会增加消息的延迟,即消息到达消费者的时间有点长
但是,Push方式会有一个坏处:如果消费者的处理消息的能力很弱(一条消息需要很长的时间处理),而消息中间件不断地向消费者Push消息,消费者的缓冲区可能会溢出。
ActiveMQ使用PUSH模型, 对于PUSH,broker很难控制数据发送给不同消费者的速度。AMQ Broker将message推送给对应的BET consumer。ActiveMQ用prefetch limit 规定了一次可以向消费者Push(推送)多少条消息。当推送消息的数量到达了perfetch limit规定的数值时,消费者还没有向消息中间件返回ACK,消息中间件将不再继续向消费者推送消息。
ActiveMQ prefetch limit 设置成0意味着什么?意味着此时,消费者去轮询消息中间件获取消息。不再是Push方式了,而是Pull方式了。即消费者主动去消息中间件拉取消息。
那么,ActiveMQ中如何采用Push方式或者Pull方式呢?
从是否阻塞来看,消费者有两种方式获取消息。同步方式和异步方式。
同步方式使用的是ActiveMQMessageConsumer的receive()方法。而异步方式则是采用消费者实现MessageListener接口,监听消息。使用同步方式receive()方法获取消息时,prefetch limit即可以设置为0,也可以设置为大于0
prefetch limit为零 意味着:“receive()方法将会首先发送一个PULL指令并阻塞,直到broker端返回消息为止,这也意味着消息只能逐个获取(类似于Request<->Response)”
prefetch limit 大于零 意味着:“broker端将会批量push给client 一定数量的消息(<= prefetch),client端会把这些消息(unconsumedMessage)放入到本地的队列中,只要此队列有消息,那么receive方法将会立即返回,当一定量的消息ACK之后,broker端会继续批量push消息给client端。”当使用MessageListener异步获取消息时,prefetch limit必须大于零了。因为,prefetch limit 等于零 意味着消息中间件不会主动给消费者Push消息,而此时消费者又用MessageListener被动获取消息(不会主动去轮询消息)。这二者是矛盾的。
Kafka使用PULL模型,PULL可以由消费者自己控制,但是PULL模型可能造成消费者在没有消息的情况下盲等,这种情况下可以通过long polling机制缓解,而对于几乎每时每刻都有消息传递的流式系统,这种影响可以忽略。
Kafka 的 consumer 是以pull的形式获取消息数据的。 pruducer push消息到kafka cluster ,consumer从集群中pull消息。









 京公网安备 11010802041100号
京公网安备 11010802041100号