作者:lashley谢 | 来源:互联网 | 2024-11-12 08:06
现象:
在使用Spark的map或flatMap算子将一个数据集(DataSet[A])转换为另一个数据集(DataSet[B])时,发现输出的Schema变成了Binary类型。具体代码如下:
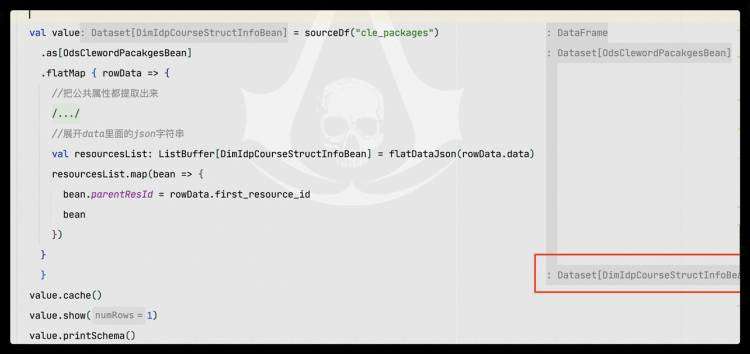
执行上述代码后,打印出来的结果如下所示:

原因:
问题的根本原因在于序列化过程中出现了错误。具体来说,我在代码中使用的Encoder是:
implicit val odsClewordPacakgesBeanEncoder = org.apache.spark.sql.Encoders.kryo[DimIdpCourseStructInfoBean]
这里的DimIdpCourseStructInfoBean是一个自定义的样例类。Kryo编码器在处理复杂对象时可能会出现问题,导致Schema被错误地解析为Binary类型。
解决方法:
为了解决这个问题,需要更换Encoder。可以尝试使用JavaSerializer或ProductEncoder来替代Kryo编码器。具体代码如下:
implicit val odsClewordPacakgesBeanEncoder = org.apache.spark.sql.Encoders.product[DimIdpCourseStructInfoBean]
需要注意的是,即使将参数改为classOf[DimIdpCourseStructInfoBean],问题仍然无法解决。具体原因尚不明确,但可能与Kryo编码器的内部实现有关。










 京公网安备 11010802041100号
京公网安备 11010802041100号