作者:幸运幸福一家人1314_332_887 | 来源:互联网 | 2023-06-26 18:14
Justforfun,写了一个demo,valrddsc.parallelize(Seq((1,a),(2,c),(3,b),(2,c)))valsortedrdd.sortByK
Just for fun,写了一个demo,
val rdd = sc.parallelize(Seq((1, "a"), (2, "c"), (3, "b"), (2, "c")))
val sorted = rdd.sortByKey()
sorted.foreach(println)
val c = sorted.count()
1.job
打开Spark UI,如图:

sortByKey,一个transform算子。为什么transform算子会引发一个job呢?
翻看源码,
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
有一个RangePartitioner,点进去,
class RangePartitioner[K : Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner {
// We allow partitiOns= 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")
private var ordering = implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
if (partitions <= 1) {
Array.empty
} else {
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and over-sample a little bit.
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.length).toInt
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
有一个sketch方法,点进去,
def sketch[K : ClassTag](
rdd: RDD[K],
sampleSizePerPartition: Int): (Long, Array[(Int, Long, Array[K])]) = {
val shift = rdd.id
// val classTagK = classTag[K] // to avoid serializing the entire partitioner object
val sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>
val seed = byteswap32(idx ^ (shift <<16))
val (sample, n) = SamplingUtils.reservoirSampleAndCount(
iter, sampleSizePerPartition, seed)
Iterator((idx, n, sample))
}.collect()
val numItems = sketched.map(_._2).sum
(numItems, sketched)
}
有个collect,这个collect就是rdd的action算子。所以触发了一个job。但是它仍然是一个transform算子。点开佛reach算子触发的job,如图,经过了sortByKey

这段RangePartitioner里的代码是干嘛呢?就是根据key划分各分区的边界,以决定后续shuffle重新分区的数据去向。
2.shuffle
点开count触发的job,
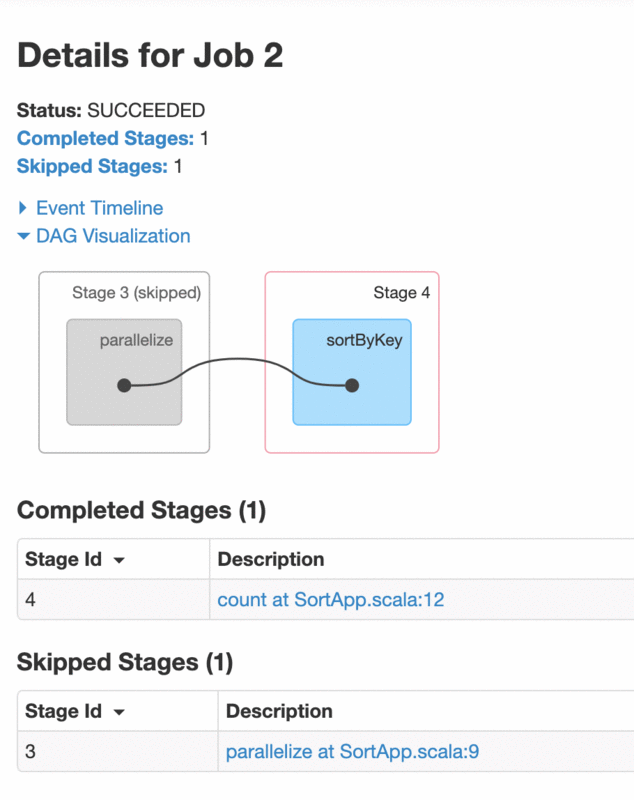
stage3被skip掉了。代码并没有缓存却能跳过一个stage。
这是因为sortByKey是个宽依赖算子,发生shuffle,shuffle的过程是上游stage把rdd的数据写出到临时文件里,再由下游stage去读取。sparkContext的生命周期里,这些临时文件(中间结果)一直存在,所以在下一个job触发的时候,根据rdd的依赖会找到这些临时文件,从而起到了“缓存”的作用。
于是,我在sortByKey后加了cache。UI图没变(这里不贴了,下面有讲)。意味着sortByKey似乎又执行了一次。cache没用还是UI显示方式就这样?
3.cache
为了验证这个问题,我把代码改了
val rddA = sc.parallelize(Seq((1, "a"), (2, "c"), (3, "b"), (2, "c")))
.filter(x => x._1 > 1).aggregateByKey(0)((x, y) => {
println("agg: " + y); 0
}, (x1, x2) => 0).cache() // 缓存agg后的rdd
val c = rddA.count()
println("总数:" + c)
rddA.foreach(println)
看UI,

如上,似乎aggregateByKey又执行了一遍!我代码中在aggregateByKey里打印了。

可以看到,只打印了一次,说明aggregateByKey只执行了一次,但是在UI中只能整个stage为灰色或蓝色。
并且这个stage3不会去读取shuffle生成的临时文件,而是直接从cache中读取ShuffledRDD。有图为证,

Shuffle Read没有数据。
PS:的字体确实比win的好看!Ayuthaya或Manaco都比Console好看~








 京公网安备 11010802041100号
京公网安备 11010802041100号