作者:lovely夏的宠儿 | 来源:互联网 | 2023-10-13 09:58
第一篇简单地介绍了一下如何用python打开一个浏览器,但没有详细说到安装的方法,这里简单补充一下。
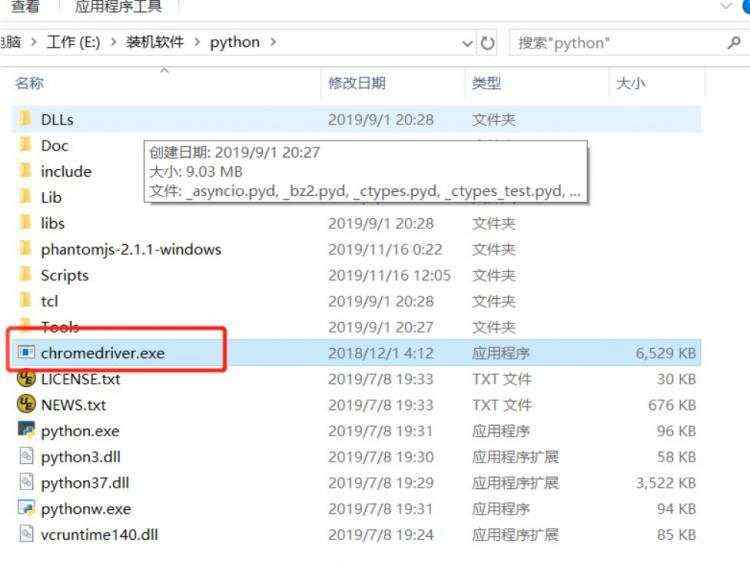
1)Google浏览器,我们只需安装后把Google浏览器的驱动放到python安装目录下即可如下图
2)对于无界面PhantomJs浏览器,我们只需找一个目录把它解压后,找到它的bin目录然后把路径复制配到系统的环境变量即可。
bin目录
 环境变量:
环境变量:

进入正题前想向做测试的朋友安利一波一款脚本语言----perl。如果有打算做后台测试或者涉及后台开发的朋友可以了解一下,在linux写一些关于连数据库的脚本,做一些数据对比或修复我觉得perl比python更方便。
前面介绍了如何驱动浏览器,今天就来实操几个我认为还比较重要的函数。一开始对这些函数有点印象就可以,以后用多了就自然背下来了。
页面请求操作
1.driver.get(url) 请求某个url对应的响应
2.refresh() 刷新页面操作
3.back() 回退到之前的页面
4.forward() 前进到之后的页面
获取断言信息的操作
1.current_url 获取当前访问页面url
2.title 获取当前浏览器标题
3.get_screenshot_as_png() 保存图片 比较少用,在selenium2中它返回一个二进制的数据需要用写文件的操作保存
4.get_screenshot_as_file(file) 直接保存 #常用测试完成后截图保存记录
5.page_source 网页源码 #常用于爬虫
元素的定位
1.直接调用型(推荐方式)
driver.find_element_by_xxx(value)
2.使用By类型(需要导入By)
from selenium.webdriver.common.by import By
driver.find_element(By.xxx,value)
元素定位有8种,但我觉得只需要熟悉使用xpath或是css其中的一种就可以解决百分之90的问题(可能我遇到太低端了)。其它了解一下就可以,当然大神都是精通8种的.
driver.find_element_by_id(value) #id属性值定位
driver.find_element_by_name(value) #name属性值定位
driver.find_element_by_class_name(value)#class属性值定位
driver.find_element_by_tag_name(value) #标签名属性值定位
driver.find_element_by_link_text(value) #链接的文本
driver.find_element_by_partial_link_text(value)#模糊匹配链接的文本
driver.find_element_by_xpath(value) #xpath路径
driver.find_element_by_css_selector(value)#css选择器定位
具体用法就不一一列举了,我提供的视频学习资料有详解.这里的介绍只是把视频中的一些重点指出并写成笔记方便日后查阅。
元素的操作
1)点击和输入
点击操作
element.click()
清空/输入操作(只能操作可以输入文本的元素)
element.clear() 清空输入框
element.send_keys(data) 输入数据
2)提交操作
element.submit()
3)获取元素信息
获取文本内容(既开闭标签之间的内容)
element.text
获取属性值(获取element元素的value属性的值)
element.get_attribute(value)
获取元素尺寸(了解)
element.size
获取元素是否可见(了解)
element.is_dispalyed()
点击和输入数据必须掌握,其余用到地方不多。下一节会把这些函数运用起来做一个简单的自动填写汉堡王客户调查领礼物的小程序.以后吃汉堡王就可以快速免费加薯条了 !
!




![[论文笔记] Crowdsourcing Translation: Professional Quality from Non-Professionals (ACL, 2011)](https://img1.php1.cn/3cd4a/24cea/882/e4b637de1cdddf51.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号