Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。下面就进入正式的学习阶段。
一、环境安装激活虚拟环境
activate nlptorch
通过pip安装
pip install selenium
针对不同的浏览器,需要安装不同的驱动。
下面以安装 Chrome 驱动作为演示。
点击chrome浏览器最右侧的“三个点”图标,然后点击弹出的“帮助”中的“关于Google Chrome”,查看自己的版本信息。这里我的版本是94,这样在下载对应版本的 Chrome 驱动即可。
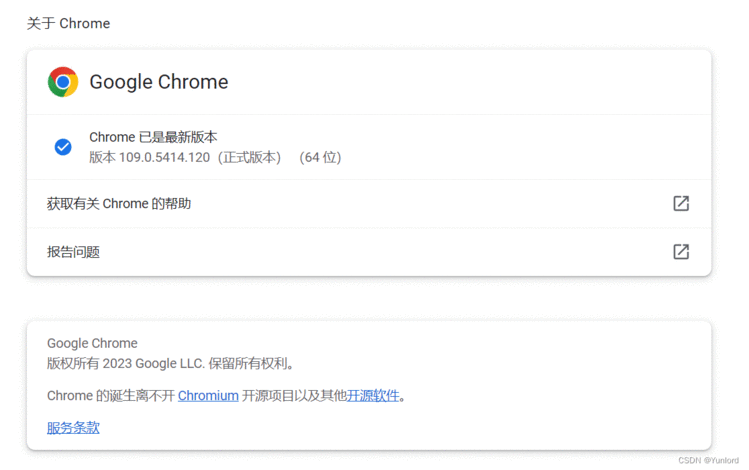
打开 下载Chrome驱动网页。单击对应的版本。

根据自己的操作系统,选择下载。
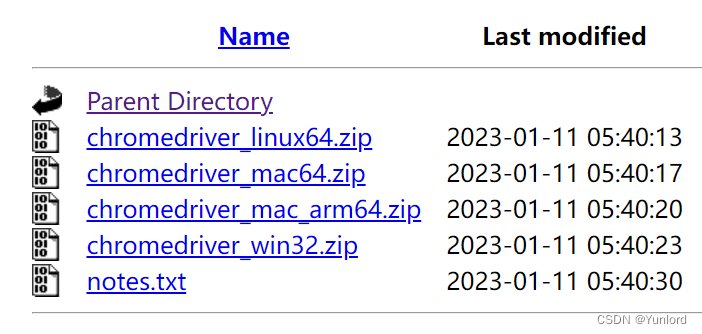
下载完成后,压缩包内只有一个 exe 文件。
将 chromedriver.exe 保存到任意位置,并把当前路径保存到环境变量。(建议将其保存到anaconda的安装目录下,这样不需要再添加环境变量了)
添加成功后使用下面代码进行测试。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
如果能弹出Chrome浏览器,则说明安装成功。
二、基础用法前期我们将Chrome驱动添加到环境变量了,所以我们可以直接初始化界面。(或者也可以通过指定绝对路径的方式)
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式(可选)
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
进行页面访问使用的是get方法,传入参数为待访问页面的URL地址即可。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
set_window_size()方法可以用来设置浏览器大小(就是分辨率),而maximize_window则是设置浏览器为全屏。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get('https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 关闭浏览器
browser.close()
前进后退也是我们在使用浏览器时非常常见的操作,这里forward()方法可以用来实现前进,back()可以用来实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get('https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get('https://www.bilibili.com/')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
当我们用selenium打开某个页面,有一些基础属性如网页标题、网址、浏览器名称、页面源码等信息
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)

使用 selenium 定位页面元素的前提是你已经了解基本的页面布局及各种标签含义,当然如果之前没有接触过,现在我也可以带你简单的了解一下。
以我们熟知的 百度为例,我们进入首页,按 【F12】 进入开发者工具。红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素。
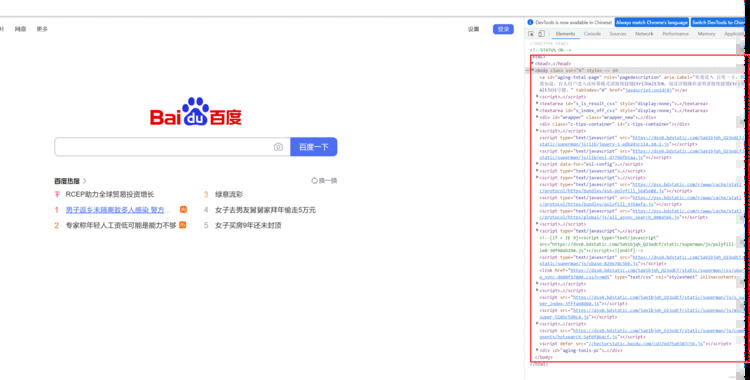
我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此,Selenium提供了一系列的方法来方便我们实现以上操作。通过webdriver对象的 find_element(by=“属性名”, value=“属性值”),主要包括以下这八种。
| 属性 | 函数 |
|---|---|
| CLASS | find_element(by=By.CLASS_NAME, value=‘’) |
| XPATH | find_element(by=By.XPATH, value=‘’) |
| LINK_TEXT | find_element(by=By.LINK_TEXT, value=‘’) |
| PARTIAL_LINK_TEXT | find_element(by=By.PARTIAL_LINK_TEXT, value=‘’) |
| TAG | find_element(by=By.TAG_NAME, value=‘’) |
| CSS | find_element(by=By.CSS_SELECTOR, value=‘’) |
| ID | find_element(by=By.ID, value=‘’) |
还是以百度举例子

可以看到这个对应的class,name以及id分别是这些,通过以下语句都可以定位到这个元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
element=browser.find_element(by=By.CLASS_NAME,value='s_ipt')
element=browser.find_element(by=By.ID,value='kw')
既然是模拟浏览器操作,自然也就需要能模拟鼠标的一些操作了,这里需要导入ActionChains 类。
from selenium.webdriver.common.action_chains import ActionChains
这个其实就是页面交互操作中的点击click()操作。
| 操作 | 函数 |
|---|---|
| 右击 | context_click() |
| 双击 | double_click() |
| 拖拽 | double_and_drop() |
| 悬停 | move_to_element() |
| 执行 | perform() |
引入Keys类
from selenium.webdriver.common.keys import Keys
| 操作 | 函数 |
|---|---|
| 删除键 | send_keys(Keys.BACK_SPACE) |
| 空格键 | send_keys(Keys.SPACE) |
| 制表键 | send_keys(Keys.TAB) |
| 回退键 | send_keys(Keys.ESCAPE) |
| 回车 | send_keys(Keys.ENTER) |
| 全选 | send_keys(Keys.CONTRL,‘a’) |
| 复制 | send_keys(Keys.CONTRL,‘c’) |
| 剪切 | send_keys(Keys.CONTRL,‘x’) |
| 粘贴 | send_keys(Keys.CONTRL,‘x’) |
| 键盘F1 | send_keys(Keys.F1) |
如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候尝试在get方法执行完成时获取网页源代码可能并非浏览器完全加载完成的页面。所以,这种情况下需要设置延时等待一定时间,确保全部节点都加载出来。
三种方式:强制等待、隐式等待和显式等待
就很简单了,直接time.sleep(n)强制等待n秒,在执行get方法之后执行。
implicitly_wait()设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
WebDriverWait的参数说明:WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver: 浏览器驱动
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency: 每次检测的间隔时间,默认是0.5秒
ignored_exceptions:超时后的异常信息,默认情况下抛出NoSuchElementException异常
until(method,message=‘’)
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not(method,message=‘’): 与until相反,until是当某元素出现或什么条件成立则继续执行,until_not是当某元素消失或什么条件不成立则继续执行,参数也相同。
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
首先我们先看看下面的代码。
上面代码在点击跳转后,使用 switch_to 切换窗口,window_handles 返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。下面先写一个包含 iframe 的页面做测试用。
COOKIEs 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 COOKIE持久化,即先用 selenium 模拟登陆获取 COOKIE ,再通过 requests 携带 COOKIE 进行请求。
webdriver 提供 COOKIEs 的几种操作:读取、添加删除。
get_COOKIEs:以字典的形式返回当前会话中可见的 COOKIE 信息。
get_COOKIE(name):返回 COOKIE 字典中
key == name 的 COOKIE 信息
add_COOKIE(COOKIE_dict):将 COOKIE 添加到当前会话中
delete_COOKIE(name):删除指定名称的单个 COOKIE
delete_all_COOKIEs():删除会话范围内的所有COOKIE
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取COOKIE
print(f'COOKIEs的值:{browser.get_COOKIEs()}')
# 添加COOKIE
browser.add_COOKIE({'name':'才哥', 'value':'帅哥'})
print(f'添加后COOKIEs的值:{browser.get_COOKIEs()}')
# 删除COOKIE
browser.delete_all_COOKIEs()
print(f'删除后COOKIEs的值:{browser.get_COOKIEs()}')
# 总结
三、高级用法
比如下拉进度条,模拟Javascript,使用execute_script方法来实现。
def is_element_exist(browser,xpath):
try:
element=browser.find_element(by=By.XPATH,value=xpath)
flag=True
except:
flag=False
return flag
temp_height=0
x=1000
y=1000
while True:
js="var q=document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop={}".format(x)
browser.excute_script(js)
time.sleep(0.5)
x+=y
check_height=browser.excute_script("return document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop;")
if check_height=temp_height:
break
temp_height=check_height
将上面两者结合,就可以实现。
temp_height=0
x=1000
y=1000
while True:
js="var q=document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop={}".format(x)
browser.excute_script(js)
time.sleep(0.5)
x+=y
check_height=browser.excute_script("return document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop;")
if check_height=temp_height:
break
temp_height=check_height
当我们需要定位的元素是动态元素,或者我们不确定它在哪时,可以先找到这个元素然后再使用JS操作
target = driver.find_element_by_id('id')
driver.execute_script("arguments[0].scrollIntoView();", target)
XPath是一门在XML文档中查找信息的语言,被用于在XML文档中通过元素和属性进行导航。有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
XPath路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点(div) |
| / | 从根节点选取 |
| // | 选择任意位置的某个节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
XPath语法通配符
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
使用text()元素的text内容 如://button[text()=“登录”]
使用contains() 包含函数 如://button[contains(text(),“登录”)]、//button[contains(@class,“btn”)]
匹配以xx结尾的属性值 如://input[starts-with(@id,“login-”)]、//input[ends-with(@id,“ogin-email”)]
使用逻辑运算符 – and、or;如://input[@name=“phone” and @datatype=“m”] 可以根据一个元素的多个属性进行定位,确保唯一性
轴定位是根据父节点,兄弟节点等节点来定位本节点,使用语法: 轴名称 :: 节点名称,使用较多场景:页面显示为一个表格样式的数据列
| 描述 | 表达式 |
|---|---|
| 定位当前节点后的所有节点 | //标签名[@属性=属性值]/follow::标签名[@属性=属性值] |
| 定位同一节点后的所有同级节点 | //标签名[@属性=属性值]/follow-sibling::标签名[@属性=属性值] |
| 定位当前节点的所有子节点 | //标签名[@属性=属性值]/child::标签名[@属性=属性值] |
| 定位当前节点前的所有节点 | //标签名[@属性=属性值]/preceding::标签名[@属性=属性值] |
| 定位同一个几点前的所有同级节点 | //标签名[@属性=属性值]/preceding-sibling::标签名[@属性=属性值] |
| 定位当前节点的所有父节点 | //标签名[@属性=属性值]/parent::标签名[@属性=属性值] |
| 定位当前节点的所有祖父节点 | //标签名[@属性=属性值]/ancestor::标签名[@属性=属性值] |
xpath='//span[text()=''/ancestor::div[3]/check-box]'
element=browser.find_element(by=By.XPATH,value=xpath)
总结
selenium的基础用法已经介绍完了,让我们实际操作起来吧,有什么问题欢迎在评论区留言,希望大家能够点赞收藏!!!
selenium用法详解【从入门到实战】
selenium的基本操作——入门级(快速上手)
2 万字带你了解 Selenium 全攻略







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 