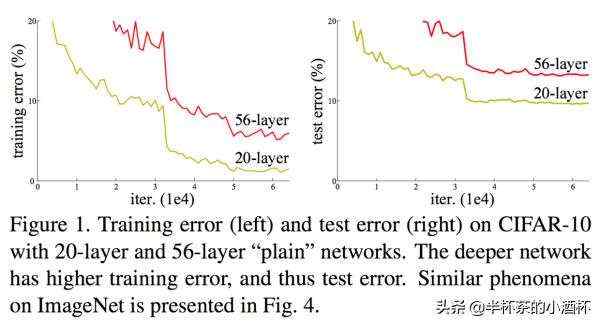
本文结合50层深度残差网络的实现学习何博士的大作-Deep Residual Learning for Image Recognition。理论上,深层网络结构包含了浅层网络结构所有可能的解空间,但是实际网络训练中,随着网络深度的增加,网络的准确度出现饱和,甚至下降的现象,这个现象可以在下图直观看出来:56层的网络比20层网络效果还要差。但是这种退化并不是因为过拟合导致的,因为56层的神经网络的训练误差同样高。
这就是神经网络的退化现象。何博士提出的残差学习的方法解决了解决了神经网络的退化问题,在深度学习领域取得了巨大的成功。
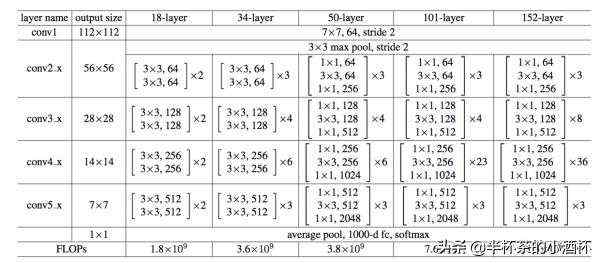
1.Residual Networks各个深度的神经网络的结构如下:
50层网络的结构实际上是把34层网络的2个3x3的卷积层替换成3个卷积层:1x1、3x3、1x1,可以看到50层的网络相对于34层的网络,效果上有不小的提升。
代码实现
ResNet 50代码实现的网络结构与上图50层的网络架构完全一致。对于深度较深的神经网络,BN必不可少,关于BN的介绍和实现可以参考以前的文章。
class ResNet50(object):
def __init__(self, inputs, num_classes=1000, is_training=True,
scope="resnet50"):
self.inputs =inputs
self.is_training = is_training
self.num_classes = num_classes
with tf.variable_scope(scope):
# construct the model
net = conv2d(inputs, 64, 7, 2, scope="conv1") # -> [batch, 112, 112, 64]
net = tf.nn.relu(batch_norm(net, is_training=self.is_training, scope="bn1"))
net = max_pool(net, 3, 2, scope="maxpool1") # -> [batch, 56, 56, 64]
net = self._block(net, 256, 3, init_stride=1, is_training=self.is_training,
scope="block2") # -> [batch, 56, 56, 256]
net = self._block(net, 512, 4, is_training=self.is_training, scope="block3")
# -> [batch, 28, 28, 512]
net = self._block(net, 1024, 6, is_training=self.is_training, scope="block4")
# -> [batch, 14, 14, 1024]
net = self._block(net, 2048, 3, is_training=self.is_training, scope="block5")
# -> [batch, 7, 7, 2048]
net = avg_pool(net, 7, scope="avgpool5") # -> [batch, 1, 1, 2048]
net = tf.squeeze(net, [1, 2], name="SpatialSqueeze") # -> [batch, 2048]
self.logits = fc(net, self.num_classes, "fc6") # -> [batch, num_classes]
self.predictions = tf.nn.softmax(self.logits)
2.Building Block每个Block中往往包含多个子Block,每个子Block又有多个卷积层组成。每个Block的第一个子Block的第一个卷积层的stride=2,完成Feature Map的下采样的工作。
代码实现
def _block(self, x, n_out, n, init_stride=2, is_training=True, scope="block"):
with tf.variable_scope(scope):
h_out = n_out // 4
out = self._bottleneck(x, h_out, n_out, stride=init_stride,
is_training=is_training, scope="bottlencek1")
for i in range(1, n):
out = self._bottleneck(out, h_out, n_out, is_training=is_training,
scope=("bottlencek%s" % (i + 1)))
return out
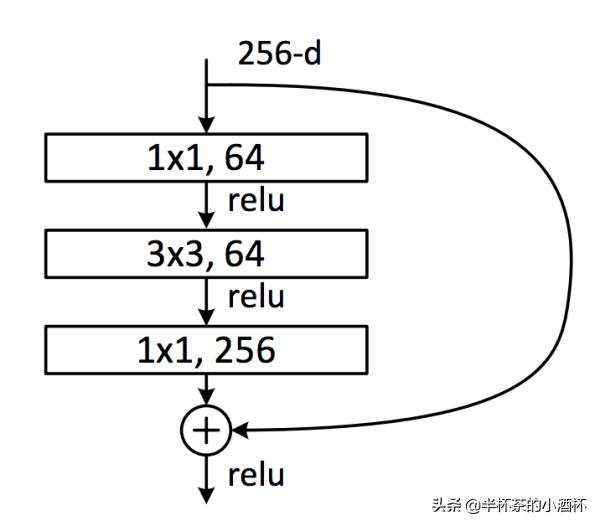
3. Bottleneck Architectures在更深层(esNet-50/101/152)的神经网络中为了节省计算耗时, 作者对神经网络的架构进行了改造,将原有的两层3x3卷积层改造为三层卷积层:1x1,3x3,1x1。
The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring)dimensions, leaving the 3×3 layer a bottleneck with smaller input/output dimensions。
代码实现:
x: 是输入数据,格式为[BatchSize, ImageHeight,ImageWidth, ChannelNum];
h_out: 卷积核个数;
n_out: Block的输出的卷积核个数;
stride: 卷积步长;
is_training: 用于Batch Normalization;
def _bottleneck(self, x, h_out, n_out, stride=None, is_training=True, scope="bottleneck"):
""" A residual bottleneck unit"""
n_in = x.get_shape()[-1]
if stride is None:
stride = 1 if n_in == n_out else 2
with tf.variable_scope(scope):
h = conv2d(x, h_out, 1, stride=stride, scope="conv_1")
h = batch_norm(h, is_training=is_training, scope="bn_1")
h = tf.nn.relu(h)
h = conv2d(h, h_out, 3, stride=1, scope="conv_2")
h = batch_norm(h, is_training=is_training, scope="bn_2")
h = tf.nn.relu(h)
h = conv2d(h, n_out, 1, stride=1, scope="conv_3")
h = batch_norm(h, is_training=is_training, scope="bn_3")
if n_in != n_out:
shortcut = conv2d(x, n_out, 1, stride=stride, scope="conv_4")
shortcut = batch_norm(shortcut, is_training=is_training, scope="bn_4")
else:
shortcut = x
return tf.nn.relu(shortcut + h)
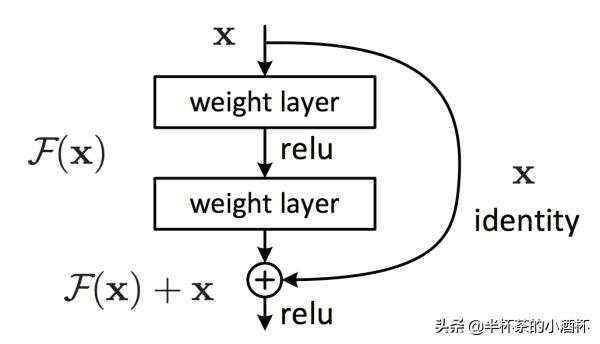
4. ShortcutsIdentity Mapping是深度残差网络的一个核心思想,深度残差网络中Building Block表达公式如下:
x是Layer Input, y是未经过Relu激活函数的Layer Output, 是待学习的残差映射。
上式仅仅能处理F(x, wi)和x维度相同的情况,当二者维度不同的情况下应该怎么处理呢?
作者提出了两种处理方式: zero padding shortcut和 projection shortcut。并在实验中构造三种shortcut的方式:
A) 当数据维度增加时,采用zero padding进行数据填充;
B) 当数据维度增加时,采用projection的方式;数据维度不变化时,直接使用恒等映射;
C) 数据维度增加与否都采用projection的方式;
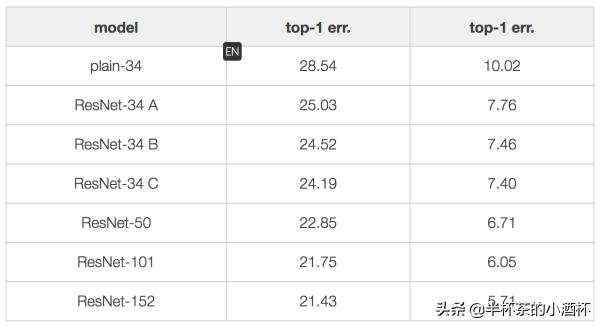
三种方式的对比效果如下:
可以看到效果排序如下: A
5.其它辅助函数的实现
5.1 变量初始化
fc_initializer = tf.contrib.layers.xavier_initializer
conv2d_initializer = tf.contrib.layers.xavier_initializer_conv2d
5.2 创建变量的辅助函数
# create weight variable
def create_var(name, shape, initializer, trainable=True):
return tf.get_variable(name, shape=shape, dtype=tf.float32,
initializer=initializer, trainable=trainable)
5.3 卷积辅助函数
# conv2d layer
def conv2d(x, num_outputs, kernel_size, stride=1, scope="conv2d"):
num_inputs = x.get_shape()[-1]
with tf.variable_scope(scope):
kernel = create_var("kernel
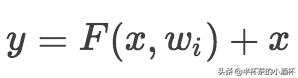









 京公网安备 11010802041100号
京公网安备 11010802041100号