作者:天才愤青2_735 | 来源:互联网 | 2023-08-22 17:11
一、nosql概述
1.1 nosql的演变
1.1.1 单机MySQL的美好时代
在90年代,一个网站的访问量一版都不大,用单个受苦可以完全应对。
在那个时候,更多是静态网页,动态交互类型的网站不多。
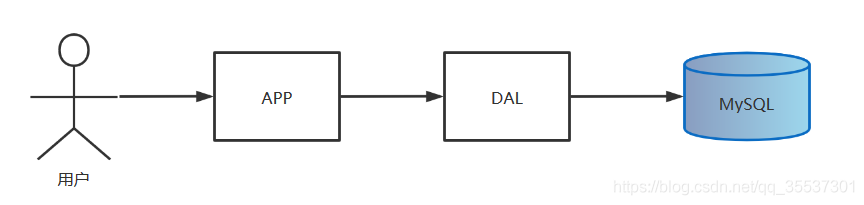
上述架构下,数据存储的瓶颈是:
1、数据总量的总大小,一个机器放不下时
2、数据的索引(B+Tree),一个机器放不下时
3、访问量(访问量)一个实力不能承受
1.1.2 Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上开始出现了性能问题,web程序不再仅仅专注在功能上,同是也在追求性能。
程序员们开始大量的使用缓存技术缓解数据库的压力,优化数据库的结构和索引。
开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带来了比较高的IO压力。
在这个时候,Memcached就自然成为一个非常时尚的技术产品。

1.1.3MySQL主从读写分离
由于数据库的写入压力增加,Memcached只能给你缓解数据库的读取压力。
读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制的技术来达到读写分离,以提高读写性能和读库的可扩展性。
MySQL的master-slave模式成为这个时候的网站标配了。

1.1 为什么要使用nosql
用户的个人信息,社交网络、地理位置,用户自己产生的数据,用户日志等等爆发式增长!
1.2 什么是nosql?
nosql = not only SQL(不仅仅是SQL)
泛指非关系型数据库,随着web2.0互联网诞生!传统的关系型数据库很难对付web2.0时代,尤其是超大规模的高并发的社区
用户的个人信息,社交网络、地理位置,这些数据类型的存储不需要一个固定的格式,不需要多余的操作就可以横向扩展
1.3 nosql的特点
方便扩展(数据之间没有关系,很好扩展)
大数据量高性能(redis每秒写8万,读取11万,nosql的缓存记录即,是一种细粒度的缓存,性能会比较高)
数据类型书多样性的(不需要事先设计数据库!随取随用,如果数据量十分大的表,很多人就无法设计了)
1.4 传统RDBMS和nosql
1.4.1 传统RDBMS
结构化组织
SQL
数据和关系都存在单独的表中
数据操作语音,数据定义语言
严格的一致性
基础的事务
...
1.4.2 nosql
不仅仅是数据
没有固定的查询语言
键值对存储,列存储,文档存储,入刑数据库
最终一致性
CAP定理和BASE(异地多活!)
高性能,高可用,高可扩
二、使用场景
三、jredis使用
3.1 下载地址
redis下载
3.2 单例连接
@Test
public void testJedisSingle(){//1 设置ip地址和端口Jedis jedis = new Jedis("192.168.137.128", 6379);//2 设置数据jedis.set("name", "itheima");//3 获得数据String name = jedis.get("name");System.out.println(name);//4 释放资源jedis.close();
}
3.3 连接池连接
@Test
public void testJedisPool(){//1 获得连接池配置对象,设置配置项JedisPoolConfig cOnfig= new JedisPoolConfig();// 1.1 最大连接数config.setMaxTotal(30);// 1.2 最大空闲连接数config.setMaxIdle(10);//2 获得连接池JedisPool jedisPool = new JedisPool(config, "192.168.137.128", 6379);//3 获得核心对象Jedis jedis = null;try {jedis = jedisPool.getResource();//4 设置数据jedis.set("name", "itcast");//5 获得数据String name = jedis.get("name");System.out.println(name);} catch (Exception e) {e.printStackTrace();} finally{if(jedis != null){jedis.close();}// 虚拟机关闭时,释放pool资源if(jedisPool != null){jedisPool.close();}}
}









 京公网安备 11010802041100号
京公网安备 11010802041100号