作者:手机用户2602890925 | 来源:互联网 | 2023-08-15 18:10
一、内存回收机制redis并不总是将空闲内存立即归还给操作系统例如:当前内存10G,删除里1G的key后,你会发现内存并没有变化因为操作系统是以页为单位回收内存的,这个页上只要有一
一、内存回收机制
redis并不总是将空闲内存立即归还给操作系统
例如:当前内存10G,删除里1G的key后,你会发现内存并没有变化
因为操作系统是以页为单位回收内存的,这个页上只要有一个key在使用,那么他就不能被回收。
如果执行flushdb,再去观察内存,会发现内存确实被回收了,因为所有的key被干掉了,内存被回收了
通过第三方库进行管理内存:jemalloc
二、过期策略
概述:redis所有的数据结构都可以设置过期时间,时间一到,就会自动删除。
1.问题:同一时间,过多key过期,占用线程处理时间,导致线程读写卡顿,redis如何处理这个问题的?
设置了过期时间的key,单独放入一个字典中。
定时策略 + 惰性策略
(1).定时扫描策略(集中处理)
redis默认每秒扫描10次(每次约100ms),过期扫描,不会扫描全部过期的key,而是采用贪心策略:
- 从过期字典中,随机挑选20个key
- 删除这20个key中已经过期的key
- 如果过期的key超过25%,那就重复步骤1
(2).惰性删除(零散处理)
在客户端访问这个key时,redis对key的过期时间进行检查,如果过期了就立即删除。
2.问题:如果所有的key在同一时间过期,会有怎样的结果?
导致读写请求出现卡顿。
原因:一、过期扫描时,出现循环过度,导致卡顿;
二、频繁回收内存页,产生cpu消耗
3.怎么做?
过期时间随机化。在过期时间设置一个范围,不能同一时间过期。
4.从节点的过期策略
从节点不会进行定时扫描,从节点的处理是被动的
主节点在key到期时,在AOF中会增加一条del指令,同步到所有从节点,从节点通过执行指令来删除过期key
5.惰性删除
删除指令,del会直接释放对象的内存,这个指令非常快,没有明显的延迟。
如果被删除的key是一个非常大的对象,比如包含了上千万个元素的hash,就不能通过del指令了,否则会造成卡顿
解决:4.0版本,引入了unlink指令,它能对删除操作进行懒处理,丢给后台进程来异步回收内存。
三、LRU
Redis配置中和LRU有关的有三个:
- maxmemory: 配置Redis存储数据时指定限制的内存大小,比如100m。当缓存消耗的内存超过这个数值时, 将触发数据淘汰。该数据配置为0时,表示缓存的数据量没有限制, 即LRU功能不生效。64位的系统默认值为0,32位的系统默认内存限制为3GB
- maxmemory_policy: 触发数据淘汰后的淘汰策略
- maxmemory_samples: 随机采样的精度,也就是随即取出key的数目。该数值配置越大, 越接近于真实的LRU算法,但是数值越大,相应消耗也变高,对性能有一定影响,样本值默认为5。
可选策略
- noeviction:如果缓存数据超过了maxmemory限定值,并且客户端正在执行的命令(大部分的写入指令,但DEL和几个指令例外)会导致内存分配,则向客户端返回错误响应
- allkeys-lru: 对所有的键都采取LRU淘汰
- volatile-lru: 仅对设置了过期时间的键采取LRU淘汰
- allkeys-random: 随机回收所有的键
- volatile-random: 随机回收设置过期时间的键
- volatile-ttl: 仅淘汰设置了过期时间的键---淘汰生存时间TTL(Time To Live)更小的键
volatile-lru, volatile-random和volatile-ttl这三个淘汰策略使用的不是全量数据,有可能无法淘汰出足够的内存空间。在没有过期键或者没有设置超时属性的键的情况下,这三种策略和noeviction差不多。
一般的经验规则:
- 使用allkeys-lru策略:当预期请求符合一个幂次分布(二八法则等),比如一部分的子集元素比其它其它元素被访问的更多时,可以选择这个策略。
- 使用allkeys-random:循环连续的访问所有的键时,或者预期请求分布平均(所有元素被访问的概率都差不多)
- 使用volatile-ttl:要采取这个策略,缓存对象的TTL值最好有差异
LRU算法
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
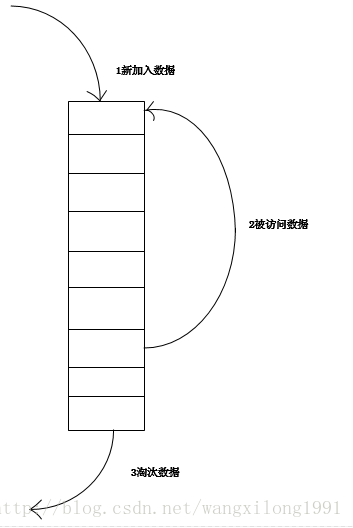
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
近似LRU算法
随机获取5个key,淘汰掉最旧的key,判断内存是否超出maxmemory,若超出,则继续循环
redis3.0以后,新增了淘汰池(一个数组)
每一次淘汰循环中,新的随机得出的key列表会和淘汰池的key列表进行融合,淘汰掉最旧的一个key,保留剩余的数据存在淘汰池中,等待下一次循环淘汰





 京公网安备 11010802041100号
京公网安备 11010802041100号