作者:mobiledu2502886053 | 来源:互联网 | 2023-08-21 13:05
在日常服务器运维工作中,备份数据库是必不可少的,刚工作那会看到公司都是用shell脚本循环备份数据库,到现在自己学习python语言后,利用多进程多线程相关技术来实现并行备份数据库
目录
- 一、为什么要用线程池
- 二、线程池练习
- 演示例子1:使用submit方法
- 演示例子2:使用map方法
- 三、线上数据库测试
- 总结:
一、为什么要用线程池
1.多线程比单线程运行要快很多,比如在我工作中,每台服务器至少8个库以上,用单线程备份太慢了。
2.不是越多线程就会越好,而是根据服务器的资源来合理定义worker线程,否则会造成服务器严重负载,影响到线上业务。
3.备份数据库都是消耗IO操作,用多线程比多进程稍微会更有优势。
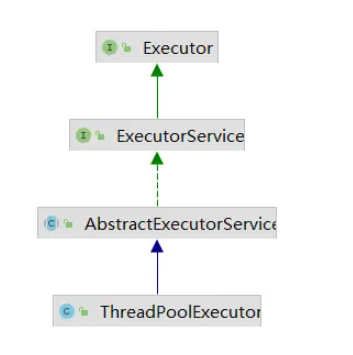
从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类。
相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
二、线程池练习
演示例子1:使用submit方法
from concurrent.futures import ThreadPoolExecutor
import time
def test_thread(sec):
time.sleep(sec)
print(f"sleep {sec} done")
return sec
with ThreadPoolExecutor(max_workers=4) as t: # 创建一个最大容纳数量为4的线程池
task1 = t.submit(test_thread, 1)
task2 = t.submit(test_thread, 2) # 通过submit提交执行的函数到线程池中
task3 = t.submit(test_thread, 3)
print(f"task1: {task1.done()}") # 通过done来判断线程是否完成
print(f"task2: {task2.done()}")
print(f"task3: {task3.done()}")
time.sleep(2.5)
print(f"task1: {task1.done()}")
print(f"task2: {task2.done()}")
print(f"task3: {task3.done()}")
print(task1.result()) # 通过result来获取返回值
结果输出:
task1: False
task2: False
task3: False
sleep 1 done
sleep 2 done
task1: True
task2: True
task3: False
1
sleep 3 done
使用 with 语句 ,通过 ThreadPoolExecutor 构造实例,同时传入 max_workers 参数来设置线程池中最多能同时运行的线程数目。
使用 submit 函数来提交线程需要执行的任务到线程池中,并返回该任务的句柄(类似于文件、画图),注意 submit() 不是阻塞的,而是立即返回。
通过使用 done() 方法判断该任务是否结束。上面的例子可以看出,提交任务后立即判断任务状态,显示3个任务都未完成。在延时2.5后,task1 和 task2 执行完毕,task3 仍在执行中。
演示例子2:使用map方法
import time
from concurrent.futures import ThreadPoolExecutor
def spider(page):
time.sleep(page)
return page
start = time.time()
executor = ThreadPoolExecutor(max_workers=4)
i = 1
for result in executor.map(spider, [2, 3, 1, 4]):
print("task{}:{}".format(i, result))
i += 1
结果输出:
task1:2
task2:3
task3:1
task4:4
from concurrent.futures import ThreadPoolExecutor有两种方式,一种是submit()函数,另一种是map()函数,两者的主要区别在于:
1.map可以保证输出的顺序, submit输出的顺序是乱的
2.如果你要提交的任务的函数是一样的,就可以简化成map。但是假如提交的任务函数是不一样的,或者执行的过程之可能出现异常(使用map执行过程中发现问题会直接抛出错误)就要用到submit()
3.submit和map的参数是不同的,submit每次都需要提交一个目标函数和对应的参数,map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
三、线上数据库测试
环境:centos6,数据库版本5.7,数据备份2个1.7G、一个800M、一个200M
第一种:shell脚本for的方式备份4个数据库
#!/bin/bash
backup_path="/data/backup/"
myuser="root"
mypwd="123456"
db_name="test_1000"
current_time=$(date +%Y%m%d%H%M%S)
for i in $(seq 4);do
/usr/local/mysql/bin/mysqldump -u${myuser} -p${mypwd} --single-transaction --master-data=2 --set-gtid-purged=off "${db_name}${i}" | gzip > ${backup_path}/"${db_name}${i}"_${current_t
ime}.sql.gz
done
查看执行时间
mysqldump: [Warning] Using a password on the command line interface can be insecure.
mysqldump: [Warning] Using a password on the command line interface can be insecure.
mysqldump: [Warning] Using a password on the command line interface can be insecure.
mysqldump: [Warning] Using a password on the command line interface can be insecure.
real 4m28.421s
user 3m50.360s
sys 0m5.962s
第二种方式:多线程备份

可以明显看到优势
总结:
在服务器上有需要备份多个数据库时,使用python多线程的方式比传统的shell脚本循环备份会更有优势,可以充分利用服务器上的资源,有效提升效率。











 京公网安备 11010802041100号
京公网安备 11010802041100号