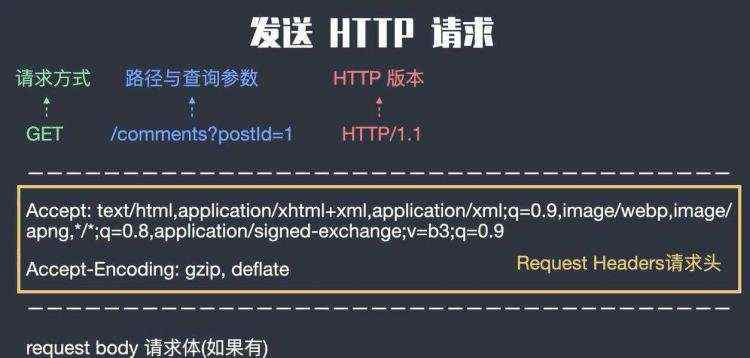
前面已经介绍过,运用表单填写帐号,用户名的方式模拟登录知乎。若登录成功,则之后就可以利用COOKIE登入,无需重复之前步骤。
importrequestsimporthttp.COOKIEjarfrom bs4 importBeautifulSoup
session=requests.Session()
session.COOKIEs= http.COOKIEjar.LWPCOOKIEJar("COOKIE")
agent= ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36‘headers={"Host": "www.zhihu.com","Origin":"https://www.zhihu.com/","Referer":"http://www.zhihu.com/",‘User-Agent‘:agent
}
postdata={‘password‘: ‘*******‘, #填写密码
‘account‘: ‘********‘, #填写帐号
}
response= session.get("https://www.zhihu.com", headers=headers)
soup= BeautifulSoup(response.content, "html.parser")
xsrf= soup.find(‘input‘, attrs={"name": "_xsrf"}).get("value")
postdata[‘_xsrf‘] =xsrf
result= session.post(‘http://www.zhihu.com/login/email‘, data=postdata, headers=headers)
session.COOKIEs.save(ignore_discard=True, ignore_expires=True)
运行后,在代码所在文件夹中出现COOKIE文件。
现在加载COOKIE登录:
importrequestsimporthttp.COOKIEjar as COOKIElib
session=requests.session()
session.COOKIEs= COOKIElib.LWPCOOKIEJar(filename=‘COOKIE‘)try:
session.COOKIEs.load(ignore_discard=True)except:print("COOKIE 未能加载")defisLogin():
url= "https://www.zhihu.com/"login_code= session.get(url, headers=headers, allow_redirects=False).status_codeif login_code == 200:returnTrueelse:returnFalseif __name__ == ‘__main__‘:
agent= ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36‘headers={"Host": "www.zhihu.com","Origin": "https://www.zhihu.com/","Referer": "http://www.zhihu.com/",‘User-Agent‘: agent
}ifisLogin():print(‘您已经登录‘)
运行后显示:您已经登录。
COOKIElib模块的主要作用是提供可存储COOKIE的对象,以便于requests模块配合使用来访问Internet资源。COOKIElib模块非常强大,我们可以利用本模块的COOKIEJar类的对象来捕获COOKIE并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有COOKIEJar、FileCOOKIEJar、MozillaCOOKIEJar、LWPCOOKIEJar。
它们的关系:COOKIEJar —-派生—->FileCOOKIEJar —-派生—–>MozillaCOOKIEJar和LWPCOOKIEJar
默认的是FileCOOKIEJar没有实现save函数。
而MozillaCOOKIEJar或LWPCOOKIEJar都已经实现了。
所以可以用MozillaCOOKIEJar或LWPCOOKIEJar,去自动实现COOKIE的save。
COOKIEJar
/
FileCOOKIEJar
/ \
MozillaCOOKIEJar LWPCOOKIEJar







 京公网安备 11010802041100号
京公网安备 11010802041100号