作者:唐耿铠1_747 | 来源:互联网 | 2023-05-19 12:09
1、ElasticSearch基础1.1、简介Elasticsearch是一个高度可伸缩的开源全文搜索引擎。Elasticsearch让你可以快速、实时地存储、搜索和分析大量数据,
1、ElasticSearch 基础
1.1、简介
Elasticsearch是一个高度可伸缩的开源全文搜索引擎。Elasticsearch让你可以快速、实时地存储、搜索和分析大量数据,它通常作为互联网应用的内部搜索引擎,为需要复杂搜索功能的应用提供支持。ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
1.2、应用场景
- 电商搜索引擎,使用Elasticsearch存储商品与品类信息,提供搜索和搜索建议功能(全文检索)。
- 日志系统,收集、分析日志数据,可以使用Logstash (Elasticsearch/Logstash/Kibana栈的一部分)来收集,然后将这些数据提供给Elasticsearch,通过搜索和聚合计算挖掘有价值的信息,最后通过Kibana进行可视化展示。
- 价格提醒平台,在价格变动时,让用户可以收到通知。抓取供应商的价格,推入Elasticsearch,并使用其反向搜索(Percolator)功能来匹配用户的价格通知设置,找到匹配后将提醒推送给用户。
- BI(商业智能),分析业务大数据,挖掘有价值的商务信息。可以使用Elasticsearch来存储数据,然后使用Kibana (Elasticsearch/Logstash/Kibana堆栈的一部分)构建自定义仪表板,该仪表板可以可视化显示数据。此外,还可以使用Elasticsearch聚合功能对数据执行复杂的业务智能分析。
1.3、ES与其他数据存储进行比较
|
redis
|
mysql
|
elasticsearch
|
hbase
|
hadoop/hive
|
容量/容量扩展
|
低
|
中
|
较大
|
海量
|
海量
|
查询时效性
|
极高
|
中等
|
较高
|
中等
|
低
|
查询灵活性
|
较差 k-v模式
|
非常好,支持sql
|
较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、排序、聚合等各种操作
|
较差,主要靠rowkey, scan的话性能不行,或者建立二级索引
|
非常好,支持sql
|
写入速度
|
极快
|
中等
|
较快
|
较快
|
慢
|
一致性、事务
|
弱
|
强
|
弱
|
弱
|
弱
|
1.4、ES 特点
1.4.1、天然集群、天然分片
ES把数据分成多个shard,下图中的P0-P2,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中。随着数据的不断增加,集群可以增加多个分片,把多个分片放到多个机子上,已达到负载均衡,横向扩展。

在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行Reduces得到最终结果向客户端返回。

这种集群分片的机制造就了elasticsearch强大的数据容量及运算扩展性。
1.4.2、天然索引
ES 所有数据都是默认进行索引的,这点和MySQL正好相反,MySQL是默认不加索引,要加索引必须特别说明,ES只有不加索引才需要说明。而ES使用的是倒排索引和MySQL的B+Tree索引不同。
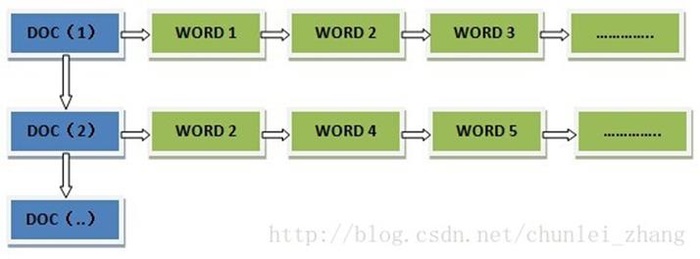
全文搜索引擎目前主流的索引技术就是倒排索引的方式。传统的保存数据的方式都是:记录→单词

而倒排索引的保存数据的方式是:单词→记录, 基于分词技术构建倒排索引,每个记录保存数据时,都不会直接存入数据库。系统先会对数据进行分词,然后以倒排索引结构保存。如下:

搜索“红海行动”,那么搜索引擎是如何能将两者匹配上的呢?等到用户搜索的时候,会把搜索的关键词也进行分词,会把“红海行动”分词分成:红海和行动两个词。这样的话,先用红海进行匹配,得到id=1和id=2的记录编号,再用行动匹配可以迅速定位id为1,3的记录。那么全文索引通常,还会根据匹配程度进行打分,显然1号记录能匹配的次数更多。所以显示的时候以评分进行排序的话,1号记录会排到最前面。而2、3号记录也可以匹配到。倒排索引结构:

可以看到 Lucene为倒排索引(Term Dictionary)部分又增加一层Term Index结构,用于快速定位,而这Term Index是缓存在内存中的,但MySQL的B+tree不在内存中,所以整体来看ES速度更快,但同时也更消耗资源(内存、磁盘)
2、ElasticSearch 安装
本次项目使用 elasticsearch6.6 版本,官网
https://www.elastic.co/products/elasticsearch
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-6-0
2.1、安装文件解压
[hui@hadoop201 bin]$ tar zxvf /opt/software/elasticsearch-6.6.0.tar.gz -C /opt/module/
[hui@hadoop201 module]$ mv elasticsearch6.6.0 elasticsearch
目录结构
[hui@hadoop201 elasticsearch]$ ll
total 436
drwxr-xr-x. 3 hui hui 4096 Apr 25 14:29 bin
drwxr-xr-x. 2 hui hui 178 Apr 25 14:47 config
drwxrwxr-x. 3 hui hui 19 Apr 25 14:47 data
drwxr-xr-x. 3 hui hui 4096 Jan 24 2019 lib
-rw-r--r--. 1 hui hui 13675 Jan 24 2019 LICENSE.txt
drwxr-xr-x. 2 hui hui 237 Apr 25 14:47 logs
drwxr-xr-x. 29 hui hui 4096 Jan 24 2019 modules
-rw-r--r--. 1 hui hui 403816 Jan 24 2019 NOTICE.txt
drwxr-xr-x. 2 hui hui 6 Jan 24 2019 plugins
-rw-r--r--. 1 hui hui 8519 Jan 24 2019 README.textile
2.2、 ES 配置
注意:es 配置文件 elasticsearch.yml 是 yml 格式,每行必须顶格,不能有空格“:”后面必须有一个空格
es 做一下配置修改
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#cluster.name es 集群名
cluster.name: my-es_spark
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#node.name es 当前节点名称
node.name: node-1
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#这两项测试环境可以设置成 false:意思是关闭自检程序
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#network.host 当前节点主机名称
network.host: hadoop201
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# es 集群节点集合
discovery.zen.ping.unicast.hosts: ["hadoop201", "hadoop202","hadoop203"]
注意:在测试环境中,有内存资源有限,所以对jvm 内存做一下限制,如果在生产环境可以根据资源情况做适当修改,其默认值是1G。
[hui@hadoop201 config]$ less /opt/module/elasticsearch/config/jvm.options
-Xms512m
-Xmx512m
#默认1G,生产环境可以根据具体情况做适当优化,此处为了解决资源修改为512m
2.3、ES 分发&其他节点修改
[hui@hadoop201 module]$ sxync.sh elasticsearch/
分发后记得修改另外两台节点的配置
#hadoop202 修改
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#node.name es 当前节点名称
node.name: node-2
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#network.host 当前节点主机名称
network.host: hadoop202
#hadoop203 修改
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#node.name es 当前节点名称
node.name: node-3
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#network.host 当前节点主机名称
network.host: hadoop203
2.4、ES 群起
es 单节点启动遇到的问题
问题1:max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
原因
系统允许 Elasticsearch 打开的最大文件数需要修改成65536
解决
sudo vim /etc/security/limits.conf
添加内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
注意:“*” 不要省略掉
分发文件
sudo /home/hui/bin/xsync.sh /etc/security/limits.conf
问题2:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因
一个进程可以拥有的虚拟内存区域的数量。
解决
sudo vim /etc/sysctl.conf
在文件最后添加一行
vm.max_map_count=262144
即可永久修改
分发文件
sudo /home/hui/bin/xsync.sh /etc/sysctl.conf
问题3:max number of threads [1024] for user [judy2] likely too low, increase to at least [4096] (CentOS7.x 不用改)
原因
允许最大线程数修该成4096
解决
sudo vim /etc/security/limits.d/20-nproc.conf
修改如下内容
* soft nproc 1024
修改为
* soft nproc 4096
分发文件
sudo /home/hui/bin/xsync.sh /etc/security/limits.d/20-nproc.conf
做以上修改后需要重启主机
单节点启动
[hui@hadoop201 bin]$ pwd
/opt/module/elasticsearch/bin
[hui@hadoop201 bin]$ ./elasticsearch
http://hadoop201:9200/_cat/nodes?v 查看单节点效果

3、安装 kibana
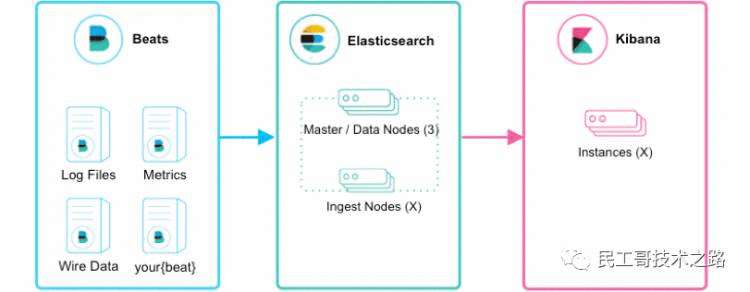
Elasticsearch提供了一套全面和强大的REST API,我们可以通过这套API与ES集群进行交互。例如:我们可以通过 API: GET /_cat/nodes?v获取ES集群节点情况,要想访问这个API,我们需要使用curl命令工具来访问Elasticsearch服务curl http://hadoop201:9200/_cat/nodes?v 也可以使用任何其他HTTP/REST调试工具,例如POSTMAN。Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
3.1、安装&配置
[hui@hadoop201 software]$ tar -zxvf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/
[hui@hadoop201 software]$ mv /opt/module/kibana-6.6.0-linux-x86_64/ /opt/module/kibana
[hui@hadoop201 config]$ pwd
/opt/module/kibana/config
[hui@hadoop201 config]$ vim kibana.yml
# To allow connections from remote users, set this parameter to a non-loopback address.
#配置可以远程访问
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
#es 地址
elasticsearch.hosts: ["http://hadoop201:9200","http://hadoop202:9200","http://hadoop203:9200"]
3.2、启动 kibana
[hui@hadoop201 kibana]$ bin/kibana
群起脚本
[hui@hadoop201 bin]$ vim es.sh
#!/bin/bash
es_home=/opt/module/elasticsearch
kibana_home=/opt/module/kibana
case $1 in
"start") {
for i in hadoop201 hadoop202 hadoop203
do
echo "==============$i上ES启动=============="
ssh $i "source /etc/profile;${es_home}/bin/elasticsearch >/dev/null 2>&1 &"
done
nohup ${kibana_home}/bin/kibana >${kibana_home}/logs/kibana.log 2>&1 &
};;
"stop") {
ps -ef|grep ${kibana_home} |grep -v grep|awk '{print $2}'|xargs kill
for i in hadoop201 hadoop202 hadoop203
do
echo "==============$i上ES停止=============="
ssh $i "ps -ef|grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac







 京公网安备 11010802041100号
京公网安备 11010802041100号