一、什么是NLTK?
NLTK 的全称是 Natural Language Toolkit,是 Python 中进行自然语言处理(Natural Language Processing)的包,可以方便快捷地对文本进行分词(tokenize)、词性标注(pos-tag)、词形还原(lemmatize)等操作。同时 NLTK 也内置了各种语言(英语、中文、俄语等)的停用词(stop word),以便进行语料分析。
下面是一些 NLTK 的使用例子:
# 分词(tokenize)
>>> from nltk import word_tokenize
>>> token_list = word_tokenize('Zhihu is the best place to study')
>>> token_list
>>> ['Zhihu', 'is', 'the', 'best', 'place', 'to', 'study']p# 词性标注(pos-tag)
>>> from nltk import pos_tag
>>> tag_result = pos_tag(token_list)
>>> [('Zhihu', 'NNP'), ('is', 'VBZ'), ('the', 'DT'),('best', 'JJS'), ('place', 'NN'), ('to', 'TO'), ('study', 'VB')]
二、什么是Stanford CoreNLP?
斯坦福大学(Stanford University)的自然语言处理团队是该领域的佼佼者,其开发的许多开源自然语言处理算法精确度高、使用便利,为研究者们提供了极大的方便。CoreNLP是该团队开发的自然语言处理软件,与NLTK类似,也提供了诸如文本分词、词性标注、词形还原等功能,使用者可以直接通过GUI界面进行操作,也可以在程序中调用其API服务。
三、既然有了NLTK,为什么还需要CoreNLP?
尽管NLTK可以帮助我们完成许多工作,但是在一些自然语言处理领域NLTK确实无法胜任,例如解析句子成分(parsing)、情感分析(sentiment)等等,因此当我们的研究有这方面的需求之后,就需要借助于CoreNLP。可喜的是,由于NLTK“自知”无法胜任之前提到的这些工作,便为我们提供了调用CoreNLP的API服务的接口,下面我们就一起来看看具体如何在NLTK中调用CoreNLP的API服务。
四、在NLTK中调用CoreNLP的API服务
首先要注意,不同版本的NLTK有着不一样的CoreNLP接口,因此大家在操作时请务必检查自己NLTK的版本,本文在写作时使用的是NLTK的3.4.5版,CoreNLP的3.9.2版。CoreNLP功能众多,在NLTK中也有许多接口,这里我们以解析句子成分(parsing)为例。
1. 下载NLTK与CoreNLP软件
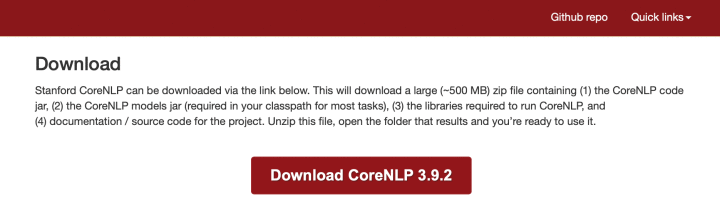
首先我们需要进入CoreNLP官网的下载页点击Download CoreNLP 3.9.2来下载CoreNLP软件。
CoreNLP官网的下载页下载完成后会得到一个名为stanford-corenlp-full-2018-10-05的文件夹,为了防止软件丢失,我们需要将其放置在一个安全的位置。本科毕业论文我进行的是NLP相关研究,因此我把它放在了这里:
~/Desktop/毕业论文/stanford-corenlp-full-2018-10-05
2. 开启CoreNLP的API服务
完成下载后,打开Mac下的“终端”(或者windows下的CMD)输入下面的命令,并敲击回车,将工作路径更改为CoreNLP软件文件夹所在的路径:
cd ~/Desktop/毕业论文/stanford-corenlp-full-2018-10-05
然后继续输入以下命令后,敲击回车,从而开启CoreNLP的API服务。
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer
-preload tokenize,ssplit,pos,lemma,ner,parse,depparse
-status_port 9000 -port 9000 -timeout 15000 &
这时,如果你在浏览器中输入如下地址http://localhost:9000 后看到了以下内容,便说明CoreNLP的API服务已经成功开启!
CoreNLP的API服务成功开启后的http://localhost:90003. 使用NLTK解析句子成分
成功开启CoreNLP的API服务之后,就可以愉快地在python中解析句子成分(parsing)了!
示例代码如下:
>>> from nltk.parse import CoreNLPParser# 初始化一个Parser
>>> parser = CoreNLPParser(url='http://localhost:9000')# 解析句子成分
>>> list(parser.parse('What is the airspeed of an unladen swallow ?'.split()))
[Tree('ROOT', [Tree('SBARQ', [Tree('WHNP', [Tree('WP', ['What'])]),
Tree('SQ', [Tree('VBZ', ['is']), Tree('NP', [Tree('NP', [Tree('DT', ['the']),
Tree('NN', ['airspeed'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('DT', ['an']), Tree('JJ', ['unladen'])])]),
Tree('S', [Tree('VP', [Tree('VB', ['swallow'])])])])]), Tree('.', ['?'])])])]












 京公网安备 11010802041100号
京公网安备 11010802041100号