2019独角兽企业重金招聘Python工程师标准>>> 
本篇参考自 伯乐在线 :http://python.jobbole.com/81344/
前面讲解了怎么使用浏览器的工具找到COOKIEs,以及怎么直接使用COOKIEs登陆网站等等,我们这一小节来讲解一下COOKIEs的其他操作
python 中对于COOKIEs的操作使用的是COOKIElib 这个库函数,或者说,模块
查看这个模块的详细信息,还是使用 help
import COOKIElib
help (COOKIElib)
我们可以看到输出如下
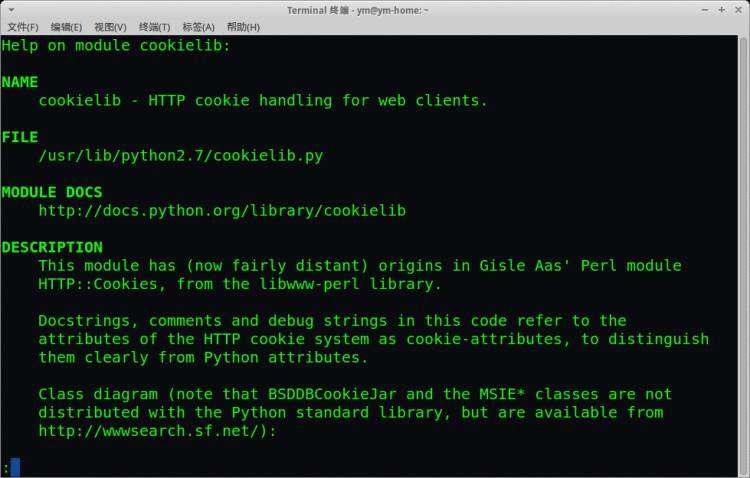
还可以进入图中显示的网址查看:https://docs.python.org/2/library/COOKIElib.html
这里面有很多的东西我们不必深究,我觉得我们现在只要知道三件事情就可以了
如何获取 COOKIEs
如何将 COOKIEs 保存到文件以便以后使用
如何从文件里面取出COOKIEs
要完成这三件事情只需要这么模块里面的几个类:COOKIEJar,FileCOOKIEJar,MozillaCOOKIEJar,LWPCOOKIEJar
它们之间的关系是这样的:COOKIEJar —-派生—->FileCOOKIEJar —-派生—–>MozillaCOOKIEJar和LWPCOOKIEJar
COOKIEJar :获取COOKIEs并保存到变量中
import urllib2
import COOKIElib
#声明一个COOKIEJar对象实例来保存COOKIE
COOKIE = COOKIElib.COOKIEJar()
#利用urllib2库的HTTPCOOKIEProcessor对象来创建COOKIE处理器
handler=urllib2.HTTPCOOKIEProcessor(COOKIE)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in COOKIE:print 'Name = '+item.nameprint 'Value = '+item.value
2. 将COOKIEs保存到文件中
FileCOOKIEJar(filename)
创建FileCOOKIEJar实例,检索COOKIE信息并将信息存储到文件中,filename是文件名
MozillaCOOKIEJar(filename)
创建与Mozilla COOKIEs.txt文件兼容的FileCOOKIEJar实例
LWPCOOKIEJar(filename)
创建与libwww-perl Set-COOKIE3文件兼容的FileCOOKIEJar实例
至于Mozilla和libwww是什么,这里给了一个链接:http://blog.csdn.net/heiyeshuwu/article/details/1691904
简单的说就是两种不同的网页存取API
import COOKIElib
import urllib2#设置保存COOKIE的文件,同级目录下的COOKIE.txt
filename = 'COOKIE.txt'
#声明一个MozillaCOOKIEJar对象实例来保存COOKIE,之后写入文件
COOKIE = COOKIElib.MozillaCOOKIEJar(filename)
#利用urllib2库的HTTPCOOKIEProcessor对象来创建COOKIE处理器
handler = urllib2.HTTPCOOKIEProcessor(COOKIE)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存COOKIE到文件
COOKIE.save(ignore_discard=True, ignore_expires=True)
关于最后save方法的两个参数在此说明一下:
官方解释如下:
ignore_discard: save even COOKIEs set to be discarded.ignore_expires: save even COOKIEs that have expiredThe file is overwritten if it already exists
由此可见,ignore_discard的意思是即使COOKIEs将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中 COOKIEs已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True
3. 从文件中读取COOKIEs
import COOKIElib
import urllib2#创建MozillaCOOKIEJar实例对象
COOKIE = COOKIElib.MozillaCOOKIEJar()
#从文件中读取COOKIE内容到变量
COOKIE.load('COOKIE.txt', ignore_discard=True, ignore_expires=True)
#创建请求的request
req = urllib2.Request("http://www.baidu.com")
#利用urllib2的build_opener方法创建一个opener
opener = urllib2.build_opener(urllib2.HTTPCOOKIEProcessor(COOKIE))
response = opener.open(req)
print response.read()






 京公网安备 11010802041100号
京公网安备 11010802041100号