作者:2d15064efa_556 | 来源:互联网 | 2023-09-24 15:07
Alertmanager prometheus-server触发一条告警的过程: prometheus---触发阈值---超出持续时间---alertmanage
Alertmanager
prometheus-server 触发一条告警的过程:
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--->邮件|钉钉|微信等。

分组(group): 将类似性质的警报合并为单个通知,比如网络通知、主机通知、服务通知。
静默(silences): 是一种简单的特定时间静音的机制,例如:服务器要升级维护可以先设置这个时间段告警静默。
抑制(inhibition): 当警报发出后,停止重复发送由此警报引发的其他警报即合并一个故障引起的多个报警事件,可以消除冗余告警
安装 alertermanager:
prometheus官网:https://prometheus.io/download/#alertmanager
Github地址:https://github.com/prometheus/alertmanager
root@haproxyB:/usr/local# tar xf alertmanager-0.24.0.linux-amd64.tar.gz
root@haproxyB:/usr/local# ln -s alertmanager-0.24.0.linux-amd64 alertmanager
创建service启动文件
root@haproxyB:/usr/local/alertmanager\# vim /etc/systemd/system/alertmanager.service
[Unit]
Description=Prometheus alertmanager
After=network.target
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file="/usr/local/alertmanager/alertmanager.yml"
[Install]
WantedBy=multi-user.target
启动alertmanager
systemctl daemon-reload && systemctl enable alertmanager.service && systemctl start alertmanager.service
alertermanager.yaml 配置文件解析:
global:
smtp_from: #发件人邮箱地址
smtp_smarthost: #邮箱 smtp 地址。
smtp_auth_username: #发件人的登陆用户名,默认和发件人地址一致。
smtp_auth_password: #发件人的登陆密码,有时候是授权码。
smtp_require_tls: #是否需要 tls 协议。默认是 true。
wechart_api_url: #企业微信 API 地址。
wechart_api_secret: #企业微信 API secret
wechat_api_corp_id: #企业微信 corp id 信息。
resolve_timeout: 60s #当一个告警在 Alertmanager 持续多长时间未接收到新告警后就标记告警状态为resolved(已解决/已恢复)。
具体配置详解:
vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '1015693563@qq.com'
smtp_auth_username: '1015693563@qq.com'
smtp_auth_password: 'ptiizujqboiydejf'
smtp_hello: '@qq.com'
smtp_require_tls: false
route:
group_by: [alertname] #通过 alertname 的值对告警进行分类,- alert: 物理节点 cpu 使用率
group_wait: 10s #一组告警第一次发送之前等待的延迟时间,即产生告警后延迟 10 秒钟将组内新产生的消息一起合并发送(一般设置为 0 秒 ~ 几分钟)。
group_interval: 2m #一组已发送过初始通知的告警接收到新告警后,下次发送通知前等待的延迟时间(一般设置为 5 分钟或更多)。
repeat_interval: 2m #一条成功发送的告警,在最终发送通知之前等待的时间(通常设置为 3 小时或更长时间)。
#间隔示例:
#group_wait: 10s #第一次产生告警,等待 10s,组内有告警就一起发出,没有其它告警就单独发出。
#group_interval: 2m #第二次产生告警,先等待 2 分钟,2 分钟后还没有恢复就进入 repeat_interval。
#repeat_interval: 5m #在最终发送消息前再等待 5 分钟,5 分钟后还没有恢复就发送第二次告警。
receiver: default-receiver #其它的告警发送给 default-receiver
routes: #将 critical 的报警发送给 myalertname
- receiver: myalertname
group_wait: 10s
match_re:
severity: critical
receivers: #定义多接收者
- name: 'default-receiver'
email_configs:
- to: 'rooroot@aliyun.com'
send_resolved: true #通知已经恢复的告警
- name: myalertname
webhook_configs:
- url: 'http://172.30.7.101:8060/dingtalk/alertname/send'
send_resolved: true #通知已经恢复的告警
配置 prometheus-server 报警规则
说明:
“description: 容器 {{ $labels.name }} CPU 资源利用率大于 10% , (current value is {{ $value }})”,中$labels.name指的是promql查询结果的label标签名称key,$value为promql查询结果的value
root@prometheus:~# cd /usr/local/prometheus
root@prometheus:/usr/local/prometheus# mkdir rules
root@prometheus:/usr/local/prometheus# vim rules/rule1.yaml
groups:
- name: alertmanager_pod.rules
rules:
- alert: Pod_all_cpu_usage
expr: (sum by(container_label_io_kubernetes_pod_name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10
for: 2m
labels:
severity: critical
service: pods
annotations:
description: 容器 {{ $labels.container_label_io_kubernetes_pod_name }} CPU 资源利用率大于 10% , (current value is {{ $value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
#expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 10
#内存大于 10%
expr: sort_desc(avg by(name)(irate(node_memory_MemFree_bytes {name!=""}[5m]))) > 2*1024*1024*1024 #内存大于 2G
for: 2m
labels:
severity: critical
annotations:
description: 容 器 {{ $labels.name }} Memory 资 源 利 用 率 大 于 2G , (current value is {{ $value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 50*1024*1024
for: 2m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} network_receive 资源利用率大于 50M , (current value is {{ $value }})
- alert: pod 内存可用大小
expr: node_memory_MemFree_bytes > 1 #故意写错的
#expr: node_memory_MemFree_bytes <512*1024*1024 (512 *1024兆*1024字节) 小于500兆
for: 2m
labels:
severity: critical
annotations:
description: 容器可用内存小于 100k
prometheus-server配置添加告警规则配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.100.21:9093 #填写alertmanager服务地址
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/rules/rule1.yaml" #填写告警规则文件
访问prometheus-server告警界面

邮箱接受告警邮件
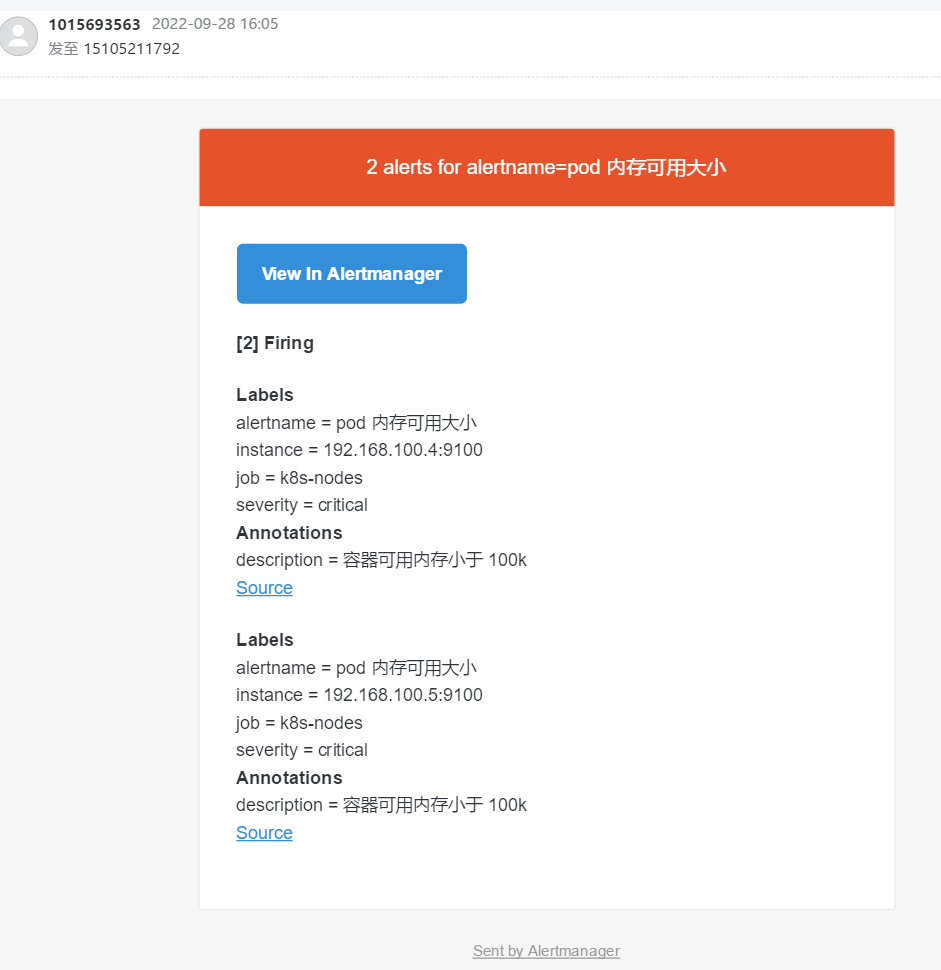
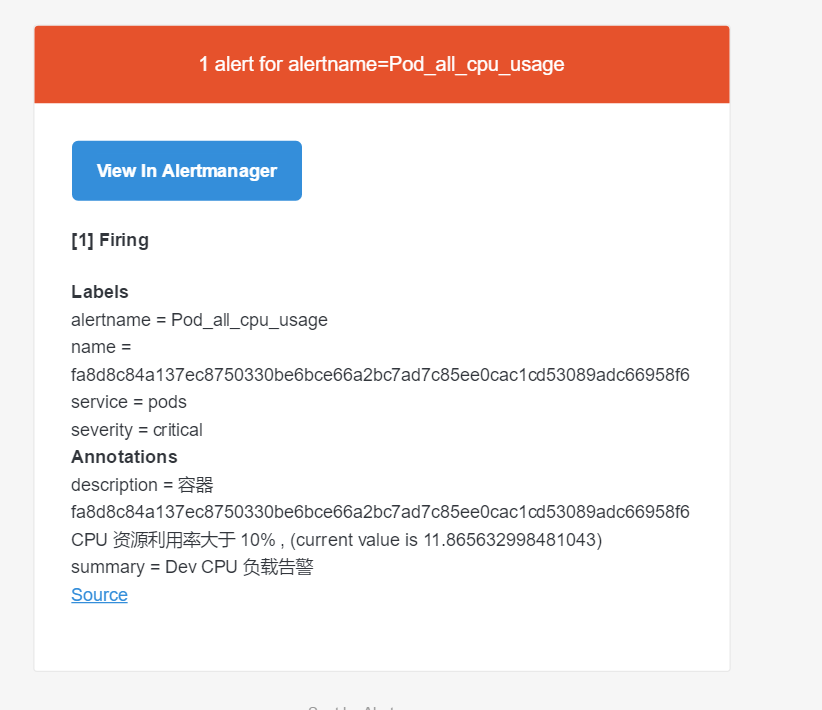
邮件通知
官方配置文档:https://prometheus.io/docs/alerting/configuration/
配置并重启alertmanager
root@haproxyB:/usr/local/alertmanager# cat alertmanager.yml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '1015693563@qq.com'
smtp_auth_username: '1015693563@qq.com'
smtp_auth_password: 'yytlspogrrutbbdj'
smtp_hello: '@qq.com'
smtp_require_tls: false
route: #route 用来设置报警的分发策略
group_by: [alertname] #通过 alertname 的值对告警进行分类,- alert: 物理节点 cpu 使用率
group_wait: 10s #一组告警第一次发送之前等待的延迟时间,即产生告警后延迟 10 秒钟将组内新产生的消息一起合并发送(一般设置为 0 秒 ~ 几分钟)。
group_interval: 2m #一组已发送过初始通知的告警接收到新告警后,下次发送通知前等待的延迟时间(一般设置为 5 分钟或更多)。
repeat_interval: 2m #一条成功发送的告警,在最终发送通知之前等待的时间(通常设置为 3 小时或更长时间)。
receiver: "qqmail" #设置接收人
receivers: #定义接收者
- name: 'qqmail'
email_configs:
- to: '15105211792@163.com'
send_resolved: true #通知已经恢复的告警
inhibit_rules: #抑制的规则
- source_match: #源匹配级别,当匹配成功发出通知,但是其它'alertname', 'dev', 'instance'产生的warning 级别的告警通知将被抑制
severity: 'critical' #报警的事件级别
target_match:
severity: 'warning' #调用 source_match 的 severity 即如果已经有'critical' 级别的报警,那么将匹配目标为新产生的告警级别为'warning' 的将被抑制
equal: ['alertname', 'dev', 'instance'] #匹配哪些对象的告警
systemctl restart alertmanager
访问alertmanager dashboard
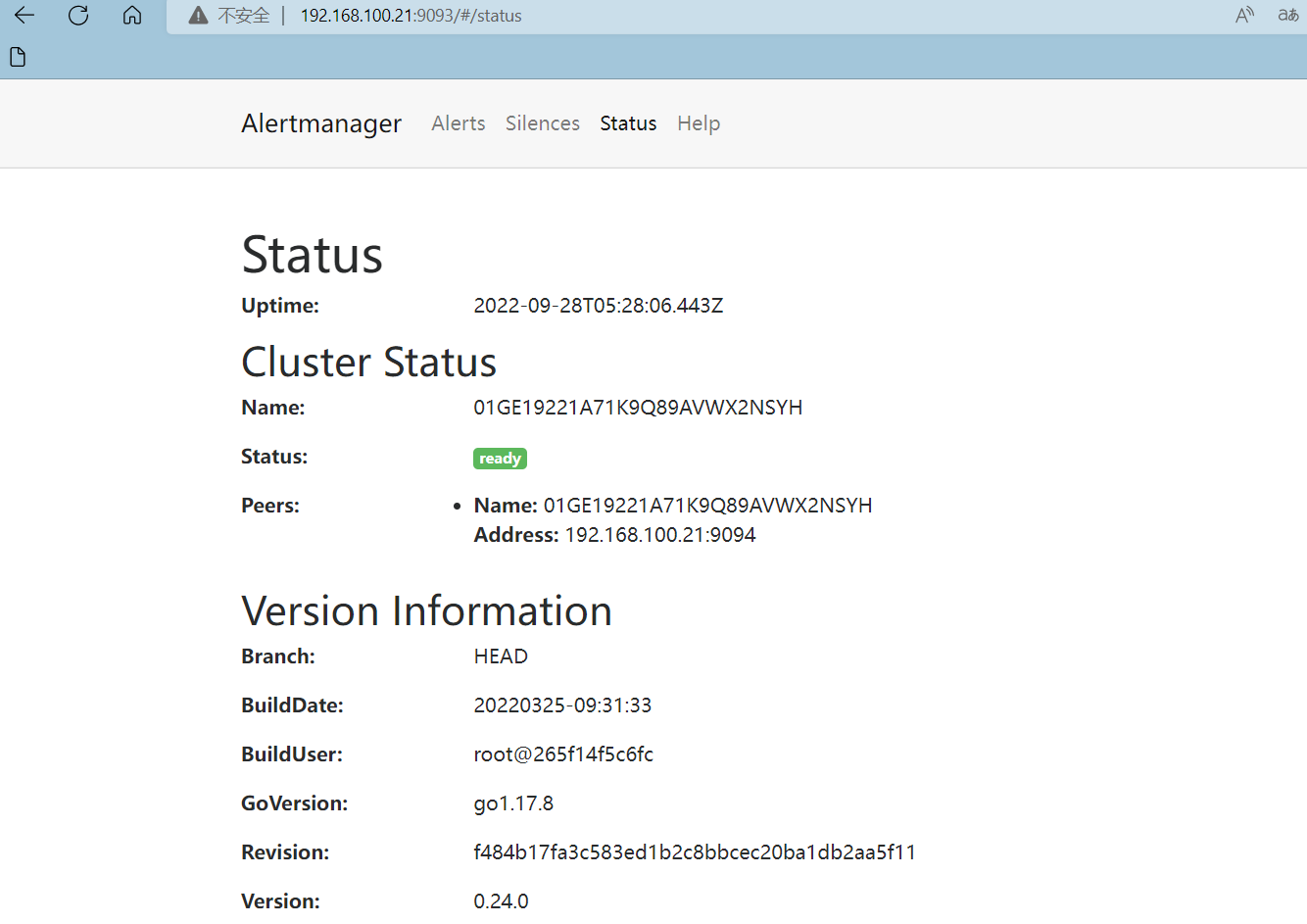
未完待续....
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/17035742.html




 京公网安备 11010802041100号
京公网安备 11010802041100号