阅读使人充实,讨论使人敏捷,写作使人精确。
>>> 业务需求描述
要求每个事务逻辑延迟1秒以内,业务初期读写3000的QPS,后续有明星大咖空降活动,要求QPS能力可横向扩展。
注:这里说的读写3000的QPS,其实水有点坑。(详见后文)>>> 系统架构环境
1.前端应用部署55台客户端设备,单台client机型配置8核心14G内存,程序使用golang+lib/pq实现编码。
2.DB侧使用pg分布式,单分片一主二从架构,可进行读写分离(后续有时间再补充独立分离的情况):
1)写平面配置2个cn,机型8核14G虚拟机;
2)同城只读平面、异地只读平面各配置1个cn,8核14G虚拟机。
3)主备dn节点一主二从均为32核64G的物理机,SSD存储。
3.架构简图如下:
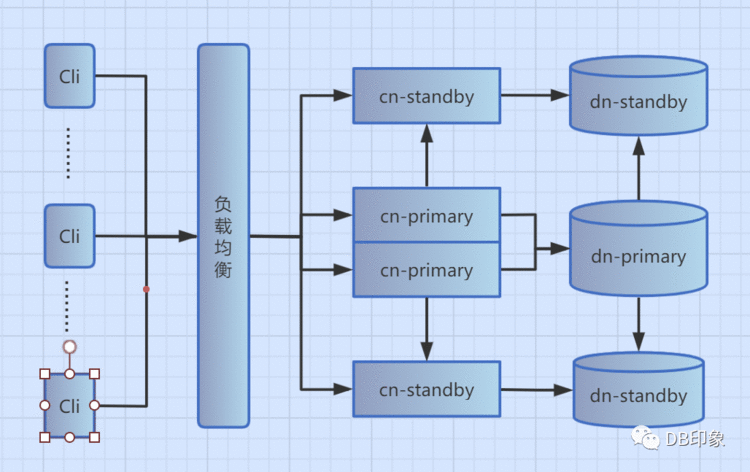
本次压测最终使用的链路如下:1台client-->负载均衡-->1个cn-primary节点-->1个dn-primary节点>>> 压测优化过程
业务层面设置每个tps为1秒强制超时,当tps达到500时业务出现大量超时报错,吐槽pg能力太差:
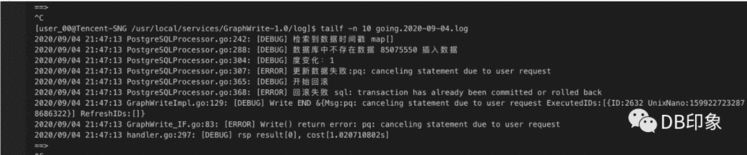
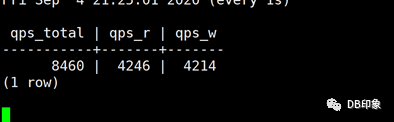
本次压测的SQL单次执行性能都在15ms以内,500并发请求业务层面就开始出现大量超时异常,打死也不能认了。根本原因是前端应用使用的无上限短连接导致DB侧接入节点cn负载过高导致。首先,暂且先保持这个无上限的短连接,将写平面2个cn节点替换成1台32核64G的物理机,使写平面变成1cn->1dn的关系,再看看QPS能去到多少。再次压测,当DB侧QPS达到8400左右的时候,业务侧开始出现超时,DB侧cn节点CPU使用率接近100%:

接下来我们得拿短连接下刀,排查应用代码发现开发同学在程序里调用动态库时未配置SetMaxOpenConns()参数,该参数缺省为0,即短连接无上限。将client连接数上限控制在32个,重新压测,DB侧QPS提升到1.2w左右,CPU使用率还有大半空余,但此时业务侧开始出现同样的超时报错::

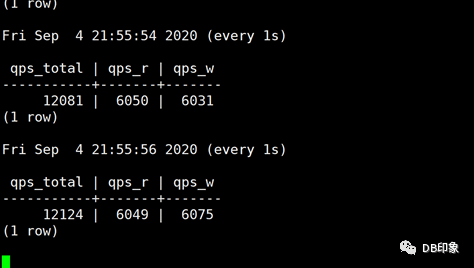
cn资源负载:
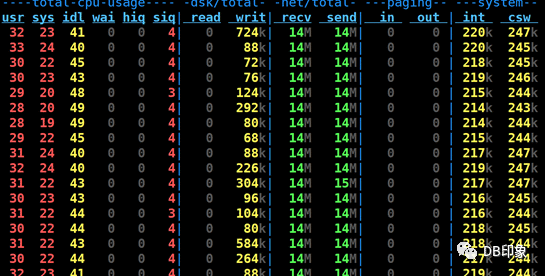
dn资源负载:
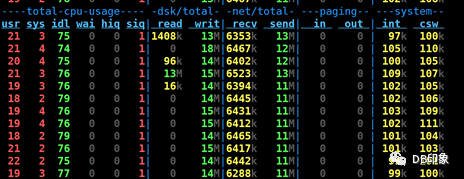
从上面的信息可以看出,DB侧未出现任何瓶颈,那么原因很可能来源于client配置及业务逻辑的实现方面。
1.client配置上,连接数上限为32个,从db侧观察到32个连接已经全部用完。(剩余的324个连接为压测程序外的应用空闲连接):
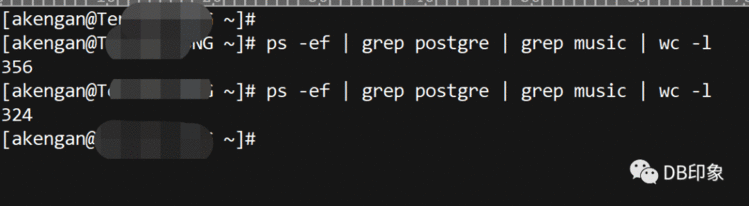
2.从QPS信息看,压测程序业务请求属于读写混合型,读写比例各一半,业务事务处理逻辑如下:
// WritePeer 在事务内,写一端的数据func (pg *PostgreSQLProcessor) WritePeer(ctx context.Context, req *graph.WriteReq, rsp *graph.WriteRsp) (int32, error) { pg.log.Debug("写tdsql一端数据:%+v", req) vertexConfig := pg.GetVertexConfig(&req.GraphBasic) if vertexConfig.IsStoreOfflineEdges == false { // 本端不用写 return 0, nil } targetsIDs := make([]string, 0) for _, v := range req.TargetsIDs { targetsIDs = append(targetsIDs, v.ID) } tablename := pg.GetTableName(req.GraphBasic.NodeType) pg.log.Debug("tablename is %v", tablename) degreeChange := 0 // 首先检索数据存在 // args := make([]interface{}, 0) // args = append(args, req.SourceID) // for _, id := range targetsIDs { // args = append(args, id) // } rows, sqlerr := pg.tx.QueryContext(ctx, fmt.Sprintf("select id,target,unixnano,status from %s where id = $1 and target = ANY($2) for update", tablename), req.SourceID, pq.Array(targetsIDs)) if sqlerr != nil { pg.log.Error("检索已有数据失败:%s", sqlerr) return -7700, sqlerr } defer rows.Close() edgeRows := make([]EdgeRow, 0) for rows.Next() { e := EdgeRow{} err := rows.Scan(&e.ID, &e.Target, &e.Unixnano, &e.Status) if err != nil { return -7800, err } edgeRows = append(edgeRows, e) } pg.log.Debug("检索到数据 %+v", edgeRows) // 记下数据库时间戳 timeMap := make(map[string]*EdgeRow) for _, r := range edgeRows { timeMap[r.Target] = &r } pg.log.Debug("检索到数据时间戳 %+v", timeMap) // 根据情况写入数据 for _, target := range req.TargetsIDs { dbrow, ok := timeMap[target.ID] if ok { if dbrow.Unixnano >= target.UnixNano { // 数据库中的时间大 不处理 pg.log.Debug("数据库中的时间大 不处理") } if dbrow.Unixnano 0 { // 判断覆盖方式对度的影响 if req.Operation == graph.ESet { degreeChange++ } else if req.Operation == graph.EUnset { degreeChange-- } } pg.log.Debug("更新了时间 %v", target.UnixNano) } } else { // 数据库中不存在数据 插入数据 pg.log.Debug("数据库中不存在数据 %v 插入数据", target.ID) rsp.ExecutedIDs = append(rsp.ExecutedIDs, target) // 判断覆盖方式对度的影响 if req.Operation == graph.ESet { degreeChange++ } // 如果不存在数据时,插入了取消边操作,则度不变化 _, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("INSERT INTO %s (id, target, unixnano, status) VALUES ($1, $2, $3, $4)", tablename), req.SourceID, target.ID, target.UnixNano, req.Operation) if sqlerr != nil { pg.log.Error("更新数据失败:%s", sqlerr) return -7903, sqlerr } } } if degreeChange != 0 { pg.log.Debug("度变化:%v", degreeChange) _, sqlerr = pg.tx.ExecContext(ctx, fmt.Sprintf("INSERT INTO %s (id, degree) VALUES ($1, $2) on conflict(id) do UPDATE set degree = %s.degree + $2", tablename+degreeSuffix, tablename+degreeSuffix), req.SourceID, degreeChange) if sqlerr != nil { pg.log.Error("更新数据失败:%s", sqlerr) return -7904, sqlerr } } return 0, nil}
将代码中的SQL抽象出来的具体如下:
read:select target, unixnano from %s where id &#61; $1 and status &#61; 0 order by unixnano desc limit $2select target, unixnano from %s where id &#61; $1 and unixnano <$2 and status &#61; 0 order by unixnano desc limit $3select target, unixnano from %s where id &#61; $1 and target &#61; ANY($2) and status &#61; 0select degree from %s where id &#61; $1write:select id,target,unixnano,status from %s where id &#61; $1 and target &#61; ANY($2) for updateupdate %s set unixnano &#61; $1 where id &#61; $2 and target &#61; $3update %s set unixnano &#61; $1 , status &#61; $2 where id &#61; $3 and target &#61; $4INSERT INTO %s (id, target, unixnano, status) VALUES ($1, $2, $3, $4)INSERT INTO %s (id, degree) VALUES ($1, $2) on conflict(id) do UPDATE set degree &#61; %s.degree &#43; $2select target, unixnano from %s where id &#61; $1 and status &#61; 0 order by unixnano desc limit $2
意思是每次事务处理之前都会先读取4次&#xff0c;写请求中第一句是事务起始读&#xff0c;根据返回结果执行如下三句中的一句&#xff0c;最后统一执行最后一句&#xff0c;执行完成后还要再查询一次。
每次业务从应用app界面请求的操作伴随两次相同的事务&#xff0c;即如果外网请求量为3000 qps&#xff0c;那么DB侧的写请求会达到 3000*2*5&#61;3w tps &#xff0c;读请求达到3000*2*5&#61;3w qps&#xff0c;即业务说的的3000请求&#xff0c;事实上需要db侧能够支撑6w的QPS。
这个逻辑看起来感觉很别扭&#xff0c;经和开发同学沟通&#xff0c;其根本目的是根据id和target字段的唯一性来判断目标表中的记录是否已存在&#xff0c;无则插入&#xff0c;有则更新unixnano和status字段的值。
用意已明&#xff0c;纷纷扰扰这么复杂&#xff0c;其实该逻辑需求在pg里面可以合并起来用1个SQL就可以达到相同的目的&#xff1a;
INSERT INTO %s (id, target, unixnano, status) VALUES (123, 456, 789, 0) on conflict(id, target) do UPDATE set unixnano &#61; $1, status &#61; $2;
业务逻辑优化之后&#xff0c;整改代码就变成了下面这个样子&#xff1a;

代入具有代表性的变量值&#xff0c;验证一下单次SQL的性能&#xff0c;耗时在8.134ms&#xff1a;
moment_fav_test&#61;# explain analyze INSERT INTO vertexa (id, target, unixnano, status) VALUES (123, 456, 789, 0) on conflict(id, target) do UPDATE set unixnano &#61; 789, status &#61; 0; QUERY PLAN --------------------------------------------------------------------------------------------------------- Remote Fast Query Execution (cost&#61;0.00..0.00 rows&#61;0 width&#61;0) (actual time&#61;8.105..8.105 rows&#61;0 loops&#61;1) Node expr: 123 Planning time: 0.087 ms Execution time: 8.134 ms(4 rows)
最后将client连接数上限配置为160&#xff0c;保持client数量为1台8核14G的虚拟机&#xff0c;QPS保持在5W左右可以稳定运行&#xff0c;业务请求成功率100%&#xff0c;dn节点CPU空闲70%以上&#xff0c;cn的CPU空闲87%以上&#xff1a;
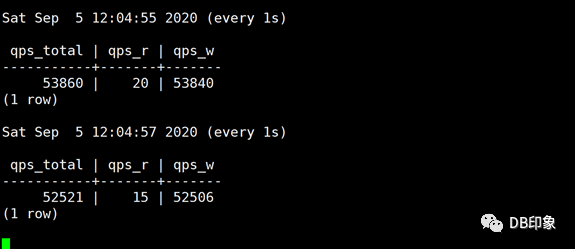
cn负载&#xff1a;
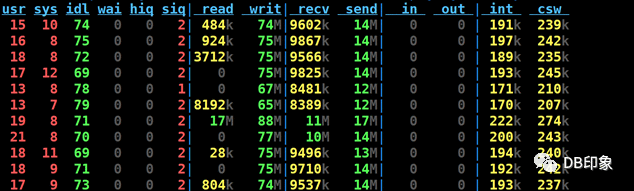
dn负载&#xff1a;
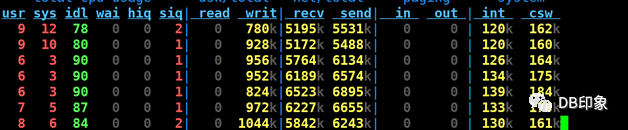
client负载&#xff1a;

client负载接近瓶颈&#xff0c;如果继续将client连接数上限上调&#xff0c;dn和cn负载基本保持不变&#xff0c;业务侧间隙性出现超时现象&#xff0c;瓶颈在client&#xff0c;在当前机型配置和SQL性能下&#xff0c;保持160个连接上限是一个稳定值。如果需要更大的连接资源及QPS能力&#xff0c;则需要横向扩展client设备数量加压。>>> 总结1.按上面的DB负载和QPS能力表现&#xff0c;单个primary节点的QPS理论极限能力应该远在5w的水平上。2.如果说为了满足业务3000的QPS能力&#xff0c;使用1台client和pg的单主已经足够&#xff0c;何况这里还没有将该分片的一主二备的读写分离利用起来&#xff0c;而且后面随着业务增长&#xff0c;我们还可以继续横向扩展。3.建议前端应用每个客户端设置32个长连接上限&#xff0c;只需5台同等配置的设备即共160个连接需求可满足业务1w的写需求(理论可支撑3W)&#xff0c;可直接为业务节省50台的设备成本。
往期推荐
1.PostgreSQL数据库OLAP测试TPCH安装部署详解
2.从Oracle到PG系列-PostgreSQL多版本控制MVCC简介
——让学习成为一种习惯-Aken

感谢阅读



 京公网安备 11010802041100号
京公网安备 11010802041100号