Gradient Descent - 梯度下降梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
以上是维基百科对梯度下降的解释。
下面我们来一步一步的学习一遍:
什么是 梯度下降?
为了方便,我们准备一些数据,并通过Python绘制出图像。
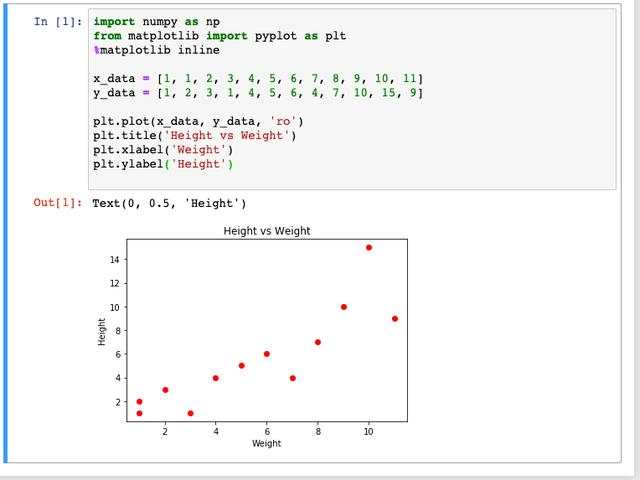
图1:数据准备和图像
如图1所示,我们准备了一组数据,x轴为体重(Weight)数据,y轴是身高(Height)数据,通过Python中 matplotlib 包,将数据图像话。
此时,图像中的点似乎呈现出线性的关系。
问题来了,我们怎么样去找到最匹配的直线关系式呢?
有的同学会直接上手 线性回归。自然没错,但是今天的主角是 梯度下降。
那么,我们一起来用梯度下降的方式来解决这个问题吧!
第一步:假设函数关系 h(x)既然上述图像可以被看成是线性关系,我们就可以假设一个线性的函数关系式:h(x);
Predicted Height = Intercept + Slope * Weight
身高的预测值 = y轴截距 + 斜率 * 体重
找到最优化线性关系的问题就转化成了:找到最优的 y轴截距 和 斜率的问题。
用数学的方法来表示如下:

图2:数学公式
在数据中,真实存在的 y值 和 预测值 h是存在误差的。这个误差可以用残留误差(Residual Error)来表示。

图3

图4:残留误差(Residual Error)
在图4中,数据点(红球)的y值与直线给出的预测值之间的误差显示为蓝色的虚线。
- 在统计中,我们将所有误差的平方和称为Sum of the Squared Residuals 残值平方和;
- 在机器学习中,所有误差的平方和称为 损失函数 Loss Function ~ J;
为什么损失函数里要用距离的平方而不是距离的绝对值?
大家有想过这个问题吗?误差是| 预测值_i - 实际值_i | ,那我取误差绝对值的和的最小值不也可以称为一个损失函数嘛。
千万不要以为这个平方是随随便便来的。背后是有道理的。
误差 = 预测值_i - 实际值_i
这个误差是符合一定概率分布的。看过我之前的文章介绍海量数据的中心极限定理的朋友,应该知道这个误差 可以被假定为:
平均值 u = 0,方差为σ 的正态分布。

图5:正态分布
那么在已知正太分布的情况下,每一个数据点都会对应一个误差,而误差出现的概率,准确的说是Likelihood是可以通过 正态分布的函数求得的。

图6:likelihood(概率)

所有数据点 误差概率相加
当我们对上述函数取对数可得:

取对数
最大似然分析,不懂得看我之前的文章。我们要保证 L 最大,只要保证上式 右边值最大。
式子右边 第一项和第二项是定值,只要保证第三项最小就可以使 L最大。
由于 u = 0,只要 sum((误差值_i)^2) 最小就可以啦!
这就是为什么 损失函数 J要采用平方的数学解释啦!
目标:找到β0 和 β1使得 损失函数 J 最小!!!
图7:给出y和x的定义
在Python中,我们首先给β0 和 β1赋值为0,当然可以赋值成任何值。

图8:梯度下降
为什么叫梯度下降?
在图8中,如果我们将每一个β0 和 β1 对应的的 残值平方和 作图表示出来,就能发现局部最低点,也就是残值平方和最小的点。图8是只考虑斜率的情况下。如果同时考虑β0 和 β1,则是三维图像,如图9.

图9
第二步:将
β0 和 β1 插入相关函数和导数中;
介绍了这么多梯度下降,接着我们就进入如何使用梯度下降 找到β0 和 β1 吧!
小范围的极小值点,我们会想到 函数的一阶导数 = 0 对应的 x 值。

图10:一阶导数
接下来,我们要定义一个重要的概念 学习效率(Learning Rate): a:梯度下降对于 Learning Rate的选择非常敏感。

图11:梯度下降
当我们在当前的β0 和 β1 下无法使得 损失函数对于β0 和 β1 的偏微分为0。
损失函数对于β0 和 β1 的偏微分可以理解成β0 和 β1 变化的梯度方向(如图11)。那么,我们在这个梯度下降的方向上给β0 和 β1 做一个微小的移动。

图12
通过对β0 和 β1 最终找到是的损失函数 J 最小的β0 和 β1。
Python实现梯度下降
图13
先从β0 和 β1 都为0开始,图13中蓝线。
我们运行1000次,并且将直线的演变过程画出来:
为了有些同学想自己试试,我把代码复制如下:
import numpy as npfrom matplotlib import pyplot as plt%matplotlib inlinex_data = [1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]y_data = [1, 2, 3, 1, 4, 5, 6, 4, 7, 10, 15, 9]plt.plot(x_data, y_data, 'ro')plt.title('Height vs Weight')plt.xlabel('Weight')plt.ylabel('Height')# y = β0 + β1 * xβ0 = 0β1 = 0y = lambda x : β0 + β1 * xdef plot_line(y, data_points): x_values = [i for i in range(int(min(data_points)) - 1, int(max(data_points)) + 2)] y_values = [y(x) for x in x_values] plt.plot(x_values, y_values, 'b') plot_line(y, x_data)learning_rate = 0.001def summation(y, x_data, y_data): slope_β0 = 0 slope_β1 = 0 for i in range(1, len(x_data)): slope_β0 += y(x_data[i]) - y_data[i] slope_β1 += (y(x_data[i]) - y_data[i]) * x_data[i] return slope_β0 / len(x_data), slope_β1 / len(x_data)for i in range(1000): slope_β0, slope_β1 = summation(y, x_data, y_data) β0 = β0 - learning_rate * slope_β0 β1 = β1 - learning_rate * slope_β1 plot_line(y, x_data) plt.plot(x_data, y_data, 'ro')总结
以上就是梯度下降的过程,以及如何通过python来实现梯度下降。
最后,我们可以得到我们想要的线性关系函数了。
y = 0.058 + 1 * x
希望大家喜欢我的文章。
“逃学博士”:理工科直男一枚,在冰天雪地的加拿大攻读工程博士。闲暇之余分享点科学知识和学习干货。








 京公网安备 11010802041100号
京公网安备 11010802041100号