| 姓名: |
XXXX |
| 学校: |
XXXXXX |
| 考试类别: |
英语四级 |
| 准考证号: |
120135151100101 |
| 考试时间: |
2015年06月 |
总分:403
听力: 132
阅读: 147
写作与翻译: 124 |
该代码显示了成绩,可以知道,该网站使用的是动态网页,用的Javascript或者Ajax.js还是其他的我就不知道了0.0。上面为需求。
前言:使用过BeautifulSoup爬取过,但是BeautifulSoup是爬取不了动态网页的,上各种论坛找各种资料,用了n种东西,scapy,pyqt等等,走了真心不少弯路,不是不行,应该是我不会用,最终用了selenium和phantomjs,这两个应该也是目前最流行的爬虫模块了吧。
一、导入selenium和phantomjs
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\phantomjs.exe')
driver.get(url)
driver.find_element_by_id('zkzh').send_keys(i)
driver.find_element_by_id('xm').send_keys(xm)
driver.find_elements_by_tag_name('form')[1].submit()
代码说明:
3.selenium可以加载很多驱动,比如Chrome、FireFox等,这里需要有这两个浏览器和驱动才行,折腾了一下,网上说Phantomjs是较好的了
5、6、7分别是准考证号,姓名和提交
二、字符处理
提交之后就可以直接查找了:
print driver.find_element_by_xpath("//tr[3]/td[1]").text
print driver.find_element_by_xpath("//tr[6]/td[1]").text
代码说明:
1.查看姓名
2.查看分数及其具体成绩
打印之后为:
姓名
听力
阅读
写作
之后要对分数进行字符串处理,选取各部分的数字,这里我们采用re模块:
import re
m = re.findall(r'(\w*[0-9]+)\w*', chuli2)
其中m是数组,输出的是["403","132","147","142"]
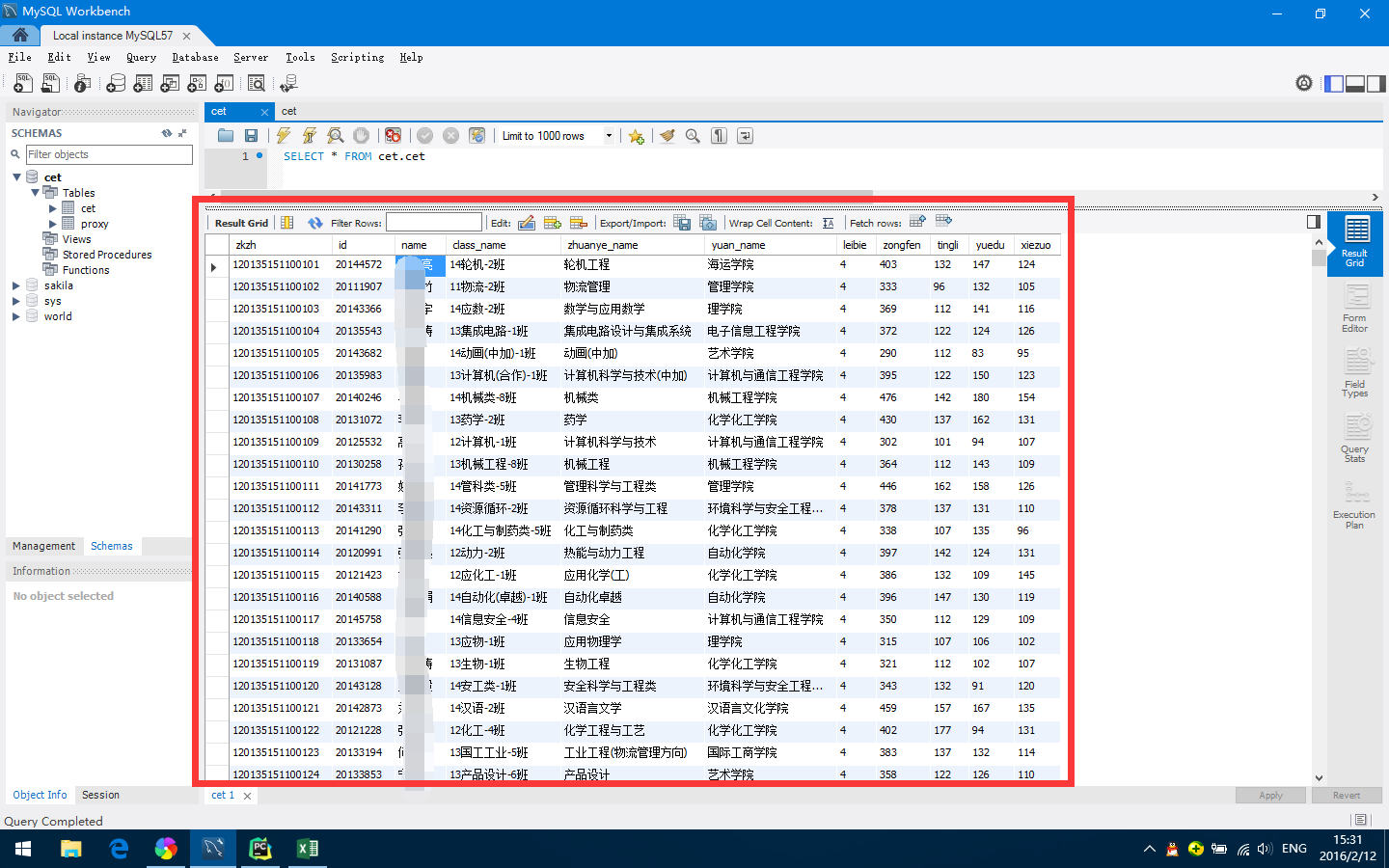
三、数据库
我们学校也不知说很渣还是人性化,反正公布了全校的四六级准考证号,当然,是excel的,需要导入mysql数据库,打开Excel之后,我发现微软大法和Oracle真是牛,Excel365居然有mysql workbench连接部分。
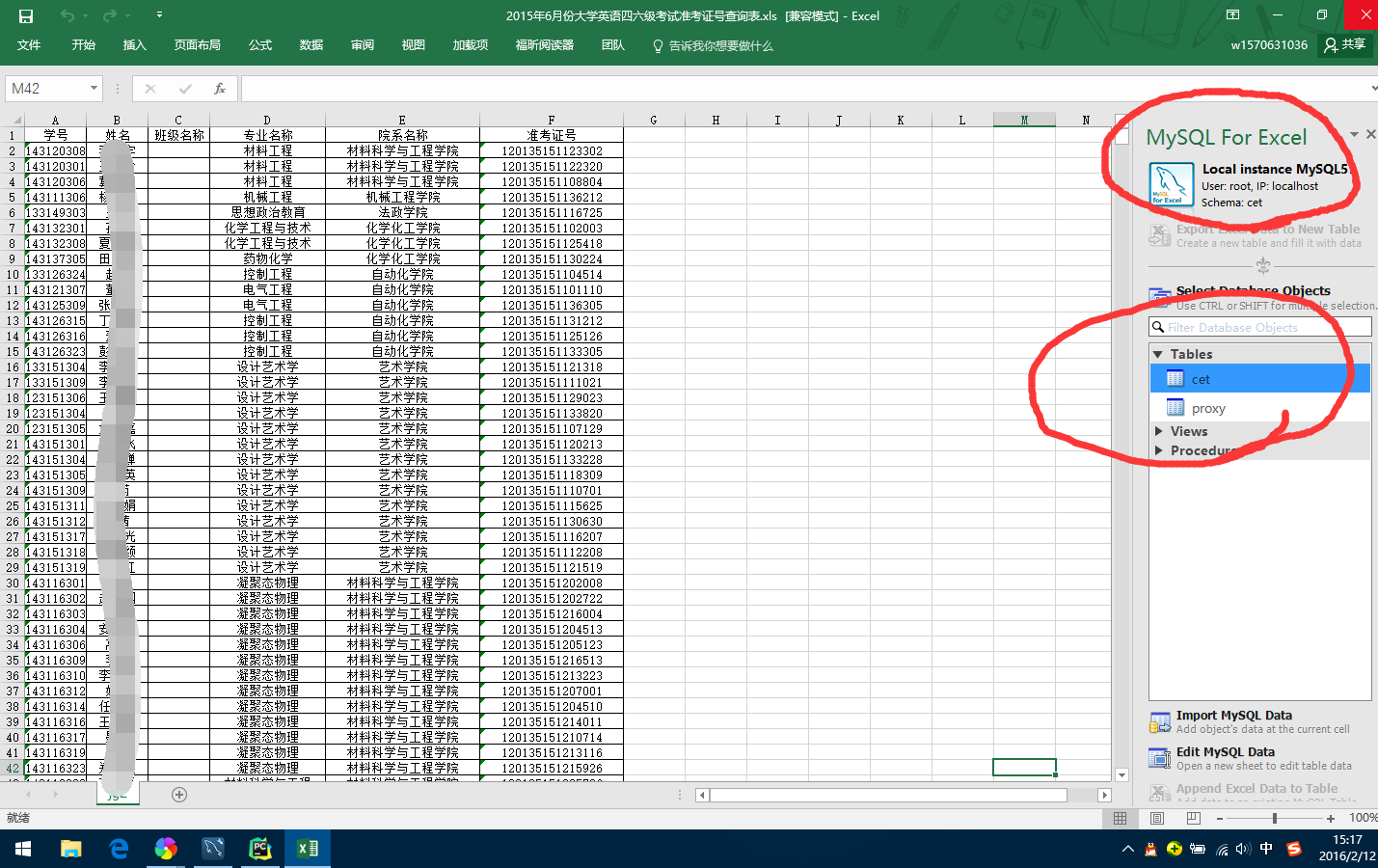
数据库代码如下:
import MySQLdb
cOnn= MySQLdb.Connect(host='localhost', user='root', passwd='root', db='cet', port=3306, charset='utf8')
cur = conn.cursor()
curr = conn.cursor()
cur.execute("select name from cet.cet where zkzh=(%s)" % i)
xm = cur.fetchone()[0]
print "Name is " + xm
sqltxt = "update cet.cet set leibie=(%s),zOngfen=(%s),tingli=(%s),yuedu=(%s),xiezuo=(%s) WHERE zkzh=(%s)" % (
ss, m[0], m[1], m[2], m[3], i)
cur.execute(sqltxt)
conn.commit()
cur.close()
conn.close()
代码说明:
3.python连接数据库代码
6.连接数据库取得姓名部分
9.这行我好无语啊,使用‘“+ss+”'这样的写法一直报错,最终找了半天资料,这个写法我不太喜欢,但是凑合着用吧。
12.记得一定要提交事务!!!commit()!!!不然是没有效果的
四、使用代理服务器(保留以后写)
运行了一段时间之后,大概抓了几百人的吧,然后就出现要求验证码了,解决办法只能处理验证码或者使用代理服务器了,这部分继续加强学习再弄出来了↖(^ω^)↗
五、源代码和效果
# encoding=utf8
import MySQLdb
import re
import time
from selenium import webdriver
# connect mysql,get zkxh and xm
cOnn= MySQLdb.Connect(host='localhost', user='root', passwd='root', db='cet', port=3306, charset='utf8')
cur = conn.cursor()
curr = conn.cursor()
url = 'http://www.chsi.com.cn/cet/query'
def kaishi(i):
print i,
print " start"
try:
cur.execute("select name from cet.cet where zkzh=(%s)" % i)
xm = cur.fetchone()[0]
print "Name is " + xm
driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\phantomjs.exe')
driver.get(url)
driver.find_element_by_id('zkzh').send_keys(i)
driver.find_element_by_id('xm').send_keys(xm)
driver.find_elements_by_tag_name('form')[1].submit()
driver.set_page_load_timeout(10)
leibie = driver.find_element_by_xpath("//tr[3]/td[1]").text
leibie2 = str(leibie.encode("utf-8"))
ss = ""
if leibie2.decode("utf-8") == '英语四级'.decode("utf-8"):
ss = 4
else:
ss = 6
# zOngfen= driver.find_element_by_xpath("//tr[6]/th[1]").text
# print zongfen
# print "===="
chuli = driver.find_element_by_xpath("//tr[6]/td[1]").text
print chuli
chuli2 = str(chuli.encode("utf-8"))
m = re.findall(r'(\w*[0-9]+)\w*', chuli2)
sqltxt = "update cet.cet set leibie=(%s),zOngfen=(%s),tingli=(%s),yuedu=(%s),xiezuo=(%s) WHERE zkzh=(%s)" % (
ss, m[0], m[1], m[2], m[3], i)
cur.execute(sqltxt)
conn.commit()
print str(i) + " finish"
except Exception, e:
print e
driver.close()
time.sleep(10)
kaishi(i)
# for j1 in range(1201351511001, 1201351512154):
for j1 in range(1201351511007, 1201351512154):
for j2 in range(0, 3):
for j3 in range(0, 10):
j = str(j1) + str(j2) + str(j3)
if str(j2) + str(j3) == "00":
print "0.0"
elif str(j2) + str(j3) == "29":
kaishi(str(j1) + str(j2) + str(j3))
j4 = str(j1) + "30"
kaishi(j4)
else:
kaishi(j)
print "END!!!"
cur.close()
conn.close()
总结:python的字符串处理细节真的很重要,动不动就输出错误,还有IDE的编码不一样,记得还有个系统编码,字符编码,环境编码,数据库编码等等都要一致。
以上就是本文的全部内容,希望对大家的学习有所帮助。
推荐阅读
-
本文将详细介绍如何在ThinkPHP6框架中实现多数据库的部署,包括读写分离的策略,以及如何通过负载均衡和MySQL同步技术优化数据库性能。 ...
[详细]
蜡笔小新 2024-12-17 18:59:28
-
1:有如下一段程序:packagea.b.c;publicclassTest{privatestaticinti0;publicintgetNext(){return ...
[详细]
蜡笔小新 2024-12-27 19:32:17
-
-
本文详细介绍了Python编程语言的学习路径,涵盖基础语法、常用组件、开发工具、数据库管理、Web服务开发、大数据分析、人工智能、爬虫开发及办公自动化等多个方向。通过系统化的学习计划,帮助初学者快速掌握Python的核心技能。 ...
[详细]
蜡笔小新 2024-12-25 12:54:33
-
本文详细介绍了如何启用和使用 MySQL 的调试模式,包括编译选项、环境变量配置以及调试信息的解析。通过实际案例展示了如何利用调试模式解决客户端无法连接服务器的问题。 ...
[详细]
蜡笔小新 2024-12-19 19:17:32
-
本文将介绍如何利用Python爬虫技术抓取国内主流在线学习平台的数据,并以51CTO学院为例,进行详细的技术解析和实践操作。 ...
[详细]
蜡笔小新 2024-12-17 11:53:33
-
随着PHP技术的发展,各类开发框架层出不穷,成为了开发者们热议的话题。本文将详细介绍并对比十款主流的PHP开发框架,旨在帮助开发者根据自身需求选择最合适的工具。 ...
[详细]
蜡笔小新 2024-12-17 11:15:55
-
本文详细介绍了IBM DB2数据库在大型应用系统中的应用,强调其卓越的可扩展性和多环境支持能力。文章深入分析了DB2在数据利用性、完整性、安全性和恢复性方面的优势,并提供了优化建议以提升其在不同规模应用程序中的表现。 ...
[详细]
蜡笔小新 2024-12-28 13:22:19
-
本文探讨了在Windows 10(64位)环境下开发的Windows服务,旨在定期向本地MS SQL Server (v.11)插入记录。尽管服务已成功安装并运行,但记录并未正确插入。我们将详细分析可能的原因及解决方案。 ...
[详细]
蜡笔小新 2024-12-28 10:30:14
-
本文详细介绍如何使用Python进行配置文件的读写操作,涵盖常见的配置文件格式(如INI、JSON、TOML和YAML),并提供具体的代码示例。 ...
[详细]
蜡笔小新 2024-12-28 08:39:55
-
本文详细探讨了云计算为企业和个人带来的多种优势,包括成本节约、安全性提升、灵活性增强等。同时介绍了云计算的五大核心特点,并结合实际案例进行分析。 ...
[详细]
蜡笔小新 2024-12-23 13:54:13
-
2019独角兽企业重金招聘Python工程师标准model:public$imageFile;publicfunctionrules(){return[[[na ...
[详细]
蜡笔小新 2024-12-20 10:19:12
-
本文探讨了2019年前端技术的发展趋势,包括工具化、配置化和泛前端化等方面,并提供了详细的学习路线和职业规划建议。 ...
[详细]
蜡笔小新 2024-12-19 10:19:35
-
本文介绍了文档对象模型(DOM)的基本概念,包括其作为HTML文档的节点树结构,以及如何通过JavaScript操作DOM来实现网页的动态交互。 ...
[详细]
蜡笔小新 2024-12-19 06:28:15
-
本文深入分析了HTML中常见的DIV样式问题,并提供了有效的解决策略。适合所有对Web前端开发感兴趣的读者。 ...
[详细]
蜡笔小新 2024-12-17 15:26:54
-
本文详细解析 PHP 中 preg_match 函数中 isU 修饰符的具体含义及其应用场景,帮助开发者更好地理解和使用正则表达式。 ...
[详细]
蜡笔小新 2024-12-17 13:35:59
-
有一颗爱心和寂寞的心
这个家伙很懒,什么也没留下!










 京公网安备 11010802041100号
京公网安备 11010802041100号