作者:鬼厉--七月 | 来源:互联网 | 2023-07-11 17:17
Pandas统计时间段数据这一段时间用python做数据统计,数据都存放在txt文件中这里我的数据长这样,总共24列17592719043682383089846010700003
Pandas统计时间段数据
这一段时间用python做数据统计,数据都存放在txt文件中
这里我的数据长这样,总共24列
17592719043682 3 83 0898 460107 0 0 0 0 3 4361 2017-05-19 01:09:12 2017-05-19 01:05:19 13 11 10466d3f609cb938dd153738103b0303 3 110.3645 20.0353 110.3665 20.0059 2017 05 19
17592719302995 3 83 0898 460106 0 0 0 0 3 5756 2017-05-19 02:08:13 2017-05-19 02:04:38 17 10 64469d36591de2366d4124291d411f02 3 110.3337 20.0652 110.3361 20.0364 2017 05 19
17592719330238 3 83 0898 460108 0 0 0 0 3 2828 2017-05-19 02:35:16 2017-05-19 02:33:07 9 7 6446a134591de8e2385848fd215f3602 3 110.3401 20.0081 110.3333 20.0222 2017 05 19
17592720943629 3 83 0898 460105 0 0 0 0 3 4854 2017-05-19 07:49:19 2017-05-19 07:47:21 14 11 64469c31591e3288b6b1ab452d31a102 3 110.2842 20.0071 110.3002 19.9818 2017 05 19
17592721794216 3 83 0898 460108 0 0 0 0 3 4478 2017-05-19 08:13:32 2017-05-19 08:10:58 12 12 10618ef5591e380f00007dbe49a914e0 3 110.3265 20.0297 110.3157 20.058 2017 05 19
这里我需要筛选2017年5月19日1点到3点之间的数据,主要用到第13列时间数据:
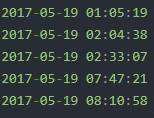
我想要提取2017-05-19 01:00:00到2017-05-19 03:00:00之间的数据,在网上找了好多代码,都不是我想要的,最后通过不断的修改,写出了自己想要的代码,话不多说,直接上源码:
import datetime
import pandas as pd
# 首先定义自己数据所在的路径以及处理完数据后的输出路径
data_path = 'D:\\7.txt'
output_path1 = 'D:\\10月17日'
if __name__ == '__main__':
# pandas读取txt数据,这里我的原来的数据是没有表头的,所以header为None,low_memory通俗理解就是只需要程序猜测你的数据格式一次,下面的数据都按照第一次猜测的来(我理解大概就是这个意思,嘿嘿嘿)
msg = pd.read_table(data_path,low_memory=False,header=None)
# 将数据的列重新命名,我的数据共有24列
msg.columns = ['1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24']
print('---------索引分界线-----------')
# 我将要处理的数据作为索引,这里要处理的时间数据在第13列,将第三列设置为标准时间格式
msg['13'] = pd.to_datetime(msg['13'])
msg = msg.set_index('13')
# print(msg)
# print("开始写入-----------")
# 设置为一个开始的时间日期,从5.19日零点开始
begin =datetime.datetime(2017,5,19,0,0,0)
# 结束时间为5.20零点(我是想将每个数据文件中对应日期的每一个小时的数据都提取出来)
end =begin + datetime.timedelta(hours=24)
# out = msg[(msg['index'] >= begin) & (msg['index'] <= end)]
# 循环的时候每次增加一个小时
delta = datetime.timedelta(hours=1)
# 开始循环啦(觉得循环真是个好东西,我之前一条一条输出的,被白眼嘲笑)
while begin < end:
a = begin
a = a.strftime("%Y-%m-%d %H:%M:%S")
print("开始写入"+a)
begin = begin + delta
begin1 = begin.strftime("%Y-%m-%d %H:%M:%S")
# 敲黑板,重点!!! 这里将每一小时间隔的数据提取出来,a/begin1都必须是字符串类型的,所以上边要用strftime转一下,最后保存
msg[a:begin1].to_csv(output_path1+ "\\"+ (begin1.replace(':','')) +".txt",encoding='utf-8-sig',sep='\t',index=True,header=None)
这个程序能直接跑的喔 只要把你对应的数据改好就行。
要修改对应的地方:输入输出路径,列索引,对应的时间





 京公网安备 11010802041100号
京公网安备 11010802041100号