最近看了两篇文章,题目惊人的相似,但是切入点和潜在应用却完全不同:
1.《Temporal Cycle-Consistency Learning》[1],出自谷歌DeepMind,是上一篇《Time-Contrastive Networks: Self-Supervised Learning from Video》[2]的拓展升级版。在文中对于temporal alignment 任务,利用多个同类视频间的时间上下文的一致性来做frame matching,self-supervised 地学习多帧的embedding features。
2. 《Learning Correspondence from the Cycle-consistency of Time》[3],出自CMU的Xiaolong等。对于一个视频内时间上下文的mid-level特征一致性来做patch matching,self-supervised 地学习单帧的embedding features。
这两篇文章都同时提到很多相同的关键词:self-supervised, Correspondence, nearest neighbors, embeddings。
它们的主要相同点:1) 都设计了cycle-consistency的loss来进行自监督学习; 2) 都是先对每帧单独提取mid-level feature,然后再在deep space里进行matching。
它们的主要区别:1) 前者的cycle loss设计是基于多个视频间的,而后者是对于一个视频内部的;2) 由于前者对frame-level进行matching,帧global 与 global运算;而后者是local patch与global运算。
----------------------------------------------------------------
一、Temporal Cycle-Consistency Learning (TCC) [1],CVPR2019
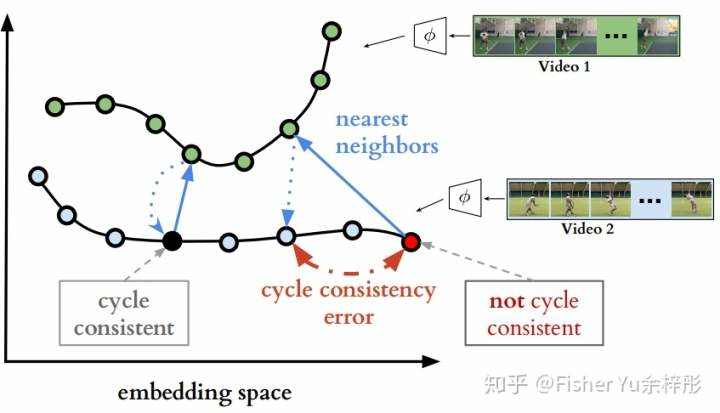
该文的目标是自学习embedding spaces,使得视频1和视频2尽量对齐。如下图所示,1) 首先对视频1和视频2若干帧映射到embedding spaces,左边的每个圆圈表示每帧的表征;2) 接着在视频1中寻找视频2当前帧(黑色和红色的圆圈)中的nearest neighbors(即实线蓝色箭头对应的两个绿色点);3) 最后cycle-back,用同样的方法寻找视频2中对应视频1两个绿色点nearest neighbors。这里产生的cycle consistency error就作为模型的Loss。
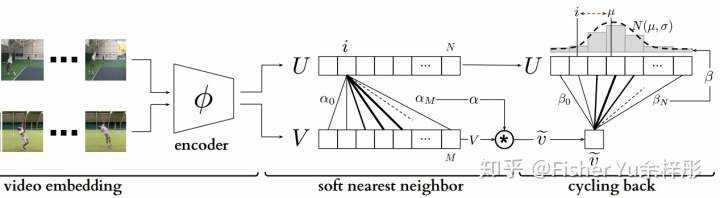
Cycle-consistent representation learning由于 cycle-consistency 的计算是不可微的,文中的主要贡献是设计了两种可微方法来实现 cycle-consistency,分别是Cycle-back 分类和Cycle-back 回归。
我们首先计算视频
![]()
中的
![]()
在视频
![]()
的soft nearest neighbor
![]()
,然后再反过来求
![]()
在视频
![]()
中的nearest neighbor。下面两种方式是用来实现soft nearest neighbor matching:
1.Cycle-back 分类
把每一帧当成是一个类别,那么匹配nearest neighbor可看成是one-hot分类问题,即只有匹配帧为1,其他帧为0。逻辑单元直接由两者在embedding space的距离表示,这样从视频
![]()
中寻找当前
![]()
的近邻可以表达成:
反过来,从视频
![]()
中寻找
![]()
的近邻也可通过距离的Softmax表示,最后产生的cross-entropy loss就是cycle consistency error。
2.Cycle-back 回归
由于上述分类过程没有约束cycled back的时间点要离当前时间点的远近,而作者希望对离得近的时间点惩罚小,而离得远的时间点惩罚大,故在cycling back的过程加入了regression loss,即约束相似性分布为高斯分布,使得在当前时间点附近有Peak分布,而整体的variance尽量小,Loss表示为:
后面实验时也对比了MSE版本的Loss,即只考虑高斯分布中的均值,不考虑方差,
![]()
,从实验结果来看,性能 Cycle-back 回归 > Cycle-back 分类 > MSE
------------------------------------
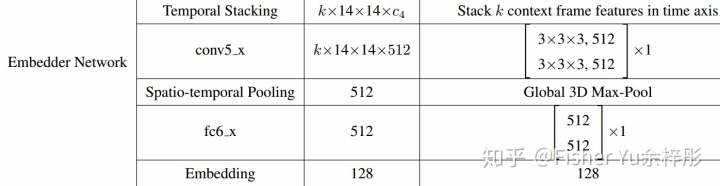
关于Encoder,使用的是VGG-M/ResNet50。而Embeeding Network结构如下,加入3D卷积和3D池化,在补充材料中作者说到,即使在 k=2 情况下,性能也较好。
实验结果
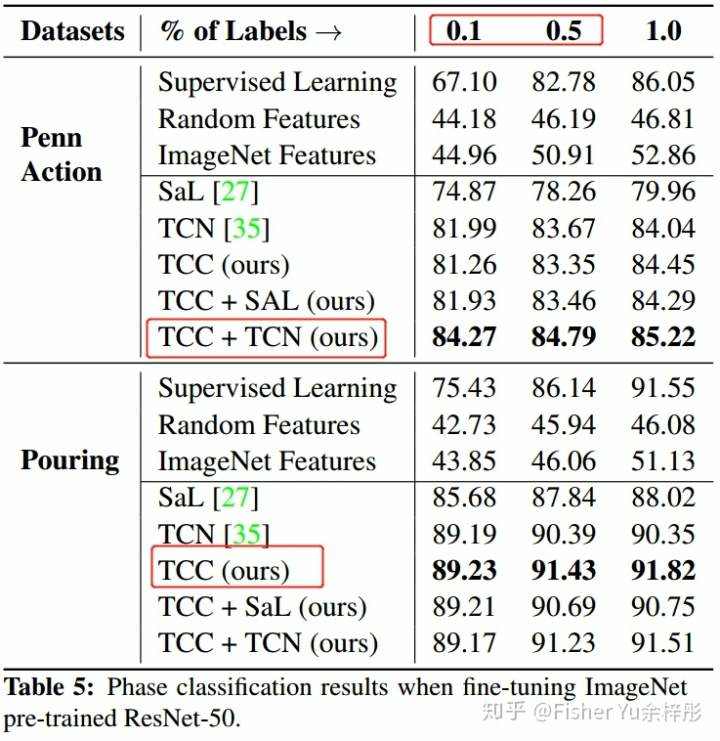
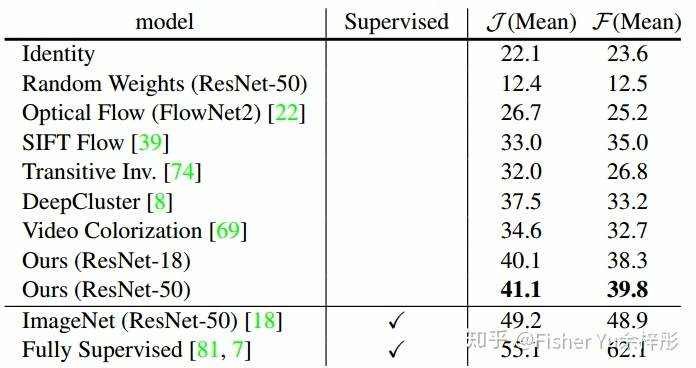
从下面实验结果图可见:1) 在仅仅有 0.1%和0.5%标注的label情况下,TCC性能远比Supervised learning的效果好,体现出 self-supervised learning在少样本学习下的优势; 2) TCC性能明显优于现有的两种无监督学习方法 SaL 和 TCN,当TCC+TCN结合时,在Penn Action下性能达到最大。
潜在应用
1.语音和视频跨模态迁移对齐
2.视频的细粒度检索,检索到内容对齐好的frame-level
3.视频异常检测
4.视频同步回放
具体可见 https://sites.google.com/view/temporal-cycle-consistency
--------------------------------------------------------------
二、Time-Contrastive Networks(TCN)[2],ICRA2018
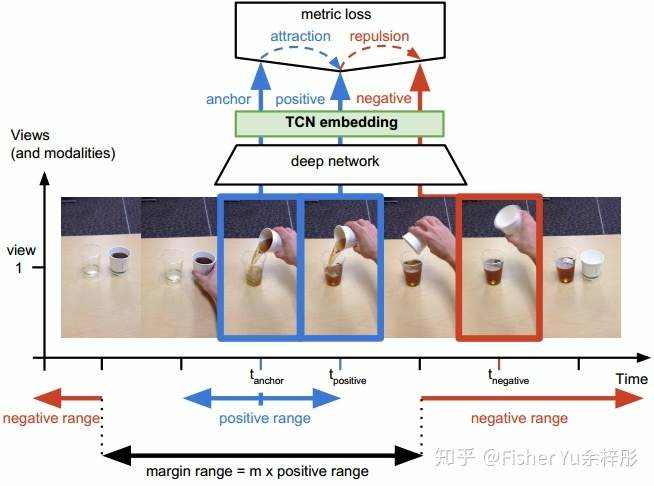
由于上面实验有对比TCN的结果,这里简单介绍下,都是同一个组的工作。主要思想在temporal上构造三元组,离anchor近的当成positive,离anchor远的当成negative。通过这个self-supervised learning,模型能学到强时间上下文的表达,尽管在空间上这些帧都是similar-looking images。
与TCC相比,TCN只有一个视频内部训练,难以学到多个视频的时间上下文关联,这也是在视频对齐中性能不如TCC的主要原因。
Single-view TCN----------------------------------------------------------------
三、Learning Correspondence from the Cycle-consistency of Time[3],CVPR2019
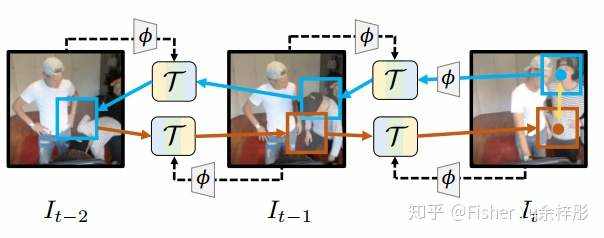
该文主要致力于统一光流和跟踪,通过自学习时空上的corresponding来得更好的embedding表征。如下图所示,主要贡献点有:1)构造了从t-->t-1-->t-2-->t-1-->t的time cycle,在不要手工标注label情况下,通过cycle前后的信息差异,来引导模型学习 ;2)对于上下文tracking,如t-->t-1,构造了可微分的tracking operation,使得网络能进行端到端地训练。
A Cycle in Time首先我们来看可微分tracking operation
![]()
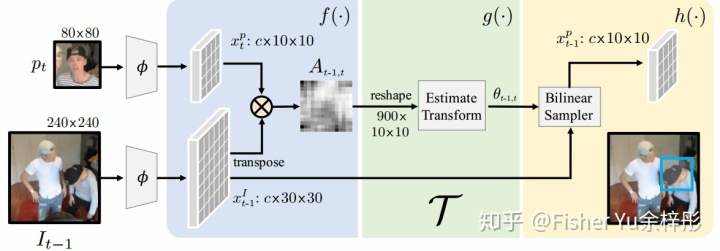
,简单的patch matching过程。如下图所示,1) 首先对当前帧需要跟踪的patch和上一帧,提取下采样8倍的Mid-level feature,进行L2正规化,通过点乘计算Affinity矩阵后Softmax; 2)接着通过两个卷积层和一个全连接层,定位出仿射变换的三个参数,2D平移和旋转;3)最后进行双线性sample,得到匹配后区域的特征。
网络的端到端训练是基于Backward-forward的iterative tracking后的模板匹配来实现的。如下图所示,在backward过程,从
![]()
-->
![]()
-->
![]()
,通过迭代进行上述的tracking operation
![]()
,我们可以得到跟踪到的特征;然后进行反向forward,迭代两次
![]()
,最后得到cycled back的patch特征,计算与原始patch特征的loss,更新网络
![]()
和
文中使用的 Loss 由三部分组成:
![]()
为每个tracking operation
![]()
前后的patch feature的相似度损失;
![]()
和
![]()
为 2-step skip cycle和原始cycle下的坐标级别的patch alignment误差。
实验结果
性能远超当前的几种unsupervised methods,但相比fully supervised,仍需努力。
实例分割on DAVIS-2017不同应用下可视化效果,在不需要人工label情况下,已经很棒棒哒:
官方的代码链接:https://github.com/xiaolonw/TimeCycle
-------------------------------------------------------------
总结与展望:
两篇文章从不同视角来构造cycle-consistency约束,目标都是为了在不需要标注label情况下,学到更好的视频representation,这也是解决在real-world中大规模无标注视频数据的低利用率及高昂的frame-level人工标注成本等问题。正如作者在future work里谈到的,这两篇文章还是存在一定局限,比如[1]中的训练需要保证同一个视频内部尽量无重复的动作片段,以及两个视频的类别及内容必须有一定的相似性;[3]中在训练过程patch的选取是随机化的,可能包含多个物体,很容易导致网络学习歧异。
未来展望的话,必须把两篇文章的思想用起来,拓展到各种视频任务中;而对于两篇文章本身,双方的结合未尝不可,对于[1]中embedding特征是基于全局的,可参考[3]中类似思想,找到场景下带语义的object/patch来进行cycle交互,估计能理解得更好,对齐得更好。
Reference:
[1] Debidatta Dwibedi et al., Temporal Cycle-Consistency Learning, CVPR2019
[2] Pierre Sermanet et al., Time-Contrastive Networks: Self-Supervised Learning from Video, ICRA2018
[3] Xiaolong Wang et al. , Learning Correspondence from the Cycle-consistency of Time, CVPR2019

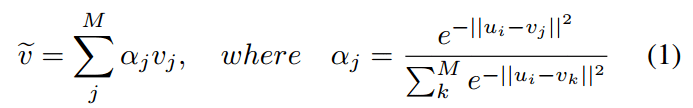
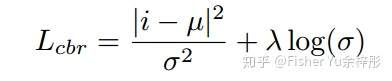

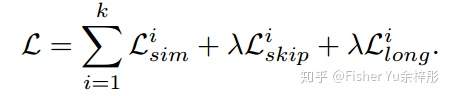






 京公网安备 11010802041100号
京公网安备 11010802041100号