作者:欣欣然人人宇 | 来源:互联网 | 2023-08-12 18:57
目录
什么是seq2seq
第一种seq2seq
第二种seq2seq
beam-search算法
参考文献
什么是seq2seq
seq2seq 模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
第一种seq2seq
第一次提出seq2seq应该是在论文[1](在本文中他还提出了rnn的变体,GRU结构单元代替原始的RNN单元)中,他采取了以下结构:

其中 Encoder 部分应该是非常容易理解的,就是一个RNNCell(RNN ,GRU,LSTM 等) 结构。每个 timestep, 我们向 Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词 XT ,然后输出整个句子的语义向量 c(一般情况下, c=hXT , XT 是最后一个输入)因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个 c 就能够把整个句子的信息都包含了,我们可以把 c 当成这个句子的一个语义表示,也就是一个句向量。在 Decoder 中,我们根据 Encoder 得到的句向量 c, 一步一步地把蕴含在其中的信息分析出来;
在decoder中,每个时刻的ht在论文中由以下公式得到:
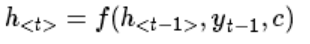
需要注意的是在训练阶段yt-1是真实label,而不是上一时刻的预测值。测试阶段是上一时刻的预测值,可以通过beam search(见附录)来优化解码。
但是在实际训练过程中,label是否使用真实数据2种方式,可以交替进行,即一种是把标准答案作为decoder的输入,还有一种是吧decoder上一次的输出的结果作为输入,因为如果完全使用标准答案,会导致收敛的过快,导致测试的时候产生不稳定性。
好了既然我们得到了h,那我们就可以根据ht,yt-1以及encoder的输入c得到这一时刻的输出yt的条件概率,定义为:
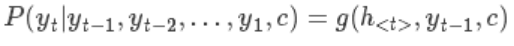
这里有两个函数 f 和 g , 一般来说&#xff0c; f 函数结构应该是一个 RNNCell 结构或者类似的结构&#xff08;论文[1]原文中用的是 GRU&#xff09;&#xff1b;g 函数一般是 softmax &#xff08;或者是论文 [4] 中提出的 sampled_softmax 函数&#xff09;。具体实现的时候是&#xff0c;decoder先输入一个开始符号y0&#xff0c;例如start一般写成SOS&#xff08;start of seq&#xff09;&#xff0c;然后Decoder 根据 h<0>&#xff0c;y0&#xff0c;c &#xff0c;就能够计算出 y1 的概率分布了&#xff0c;同理&#xff0c;根据 h<1>,y1&#xff0c;c 可以计算y2 的概率分布…以此类推直到预测到结束的特殊标志 &#xff0c;才结束预测。
第二种seq2seq
在论文[2] 中&#xff0c;google机器翻译团队使用了encoder-decoder模型的变体&#xff0c;其模型结构如下&#xff1a;

我们可以看到&#xff0c;相比于上一个网络&#xff0c;该结构encoder的输出只作用了一次&#xff0c;也就是作为decoder的初始状态h&#xff0c;同时我们不使用SOS&#xff0c;只使用EOS&#xff0c;实际上没有什么本质区别&#xff0c;只是一词两用而已。这个结构简化了原始的模型。原文中使用的是lstm单元&#xff0c;其具体的结构图大概如下图所示&#xff0c;这是一个邮件回复系统&#xff1a;

在原文中&#xff0c;作者除了使用的是4层lstm之外还使用了一些小trick&#xff0c;就是把输入的语句倒过来&#xff0c;但是作者没有明确给出解释&#xff0c;只是大致猜测了一下&#xff0c;可能是由于这种结构会使翻译pair开头的单词距离接近&#xff0c;使语义能够更好地传递。
但是有一点应该是可以改进的&#xff0c;既然反向的效果好&#xff0c;可以在encoder的时候使用bilstm&#xff0c;然后把2个隐层的state输入到decoder。
beam-search算法
首先beam-search只在test的时候有用。假设词表是a&#xff0c;b&#xff0c;c&#xff0c;beam_size&#61;2
1.生成第一个词的时候&#xff0c;选择概率最大的两个词&#xff0c;设为a和c
2.生成第二个词的时候&#xff0c;把前一时刻的输入进去&#xff0c;得到第二时刻的a&#xff0c;b&#xff0c;c的概率&#xff0c;也就是当输入是a的时候我们得到的abc相当于aa&#xff0c;ab&#xff0c;ac的概率&#xff0c;输入是c的时候得到的是ca&#xff0c;cb&#xff0c;cc的概率&#xff0c;在这6个序列中&#xff0c;选择2个得分最高的&#xff0c;然后作为保留序列&#xff0c;例如选择了aa和cb
3.生成第三个词的时候&#xff0c;由前2个保留的序列&#xff0c;可见输入是a和b&#xff0c;也就是6个序列为&#xff0c;aaa&#xff0c;aab&#xff0c;aac和cba&#xff0c;cbb&#xff0c;cbc&#xff0c;再选2个最大的。
4.之后的重复这个过程&#xff0c;获得2个最佳序列
参考文献
文献[1]:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
文献[2]: Sequence to Sequence Learning with Neural Networks
文献[3]: Neural Machine Translation by Jointly Learning to Align and Translate
文献[4]:On Using Very Large Target Vocabulary for Neural Machine Translation
文献[5]: A Neural Conversational Model
文献[6]:Beam Search Algorithm
文章转载自&#xff1a;https://zhuanlan.zhihu.com/p/27766645






 京公网安备 11010802041100号
京公网安备 11010802041100号