neo4j cypher
几个月来,我一直在建立计算机科学论文的图表,现在,我已经加载了几千本,我意识到其中有很多重复。
它们不是重复的,因为有多个条目具有相同的标识符,但是具有不同的标识符,但似乎是同一篇论文!
例如,有几篇名为“在Taos操作系统中进行身份验证”的论文:
http://dl.acm.org/citation.cfm?id=174614
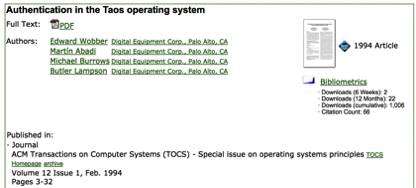
http://dl.acm.org/citation.cfm?id=168640

据我所知,这是同一篇论文发表在两个不同的期刊上。
现在,在这种情况下,很容易对这些论文的标题进行字符串相似性比较,并意识到它们是相同的。 我以前曾使用过出色的重复数据删除库来执行此操作,并且在Berlin Buzzwords 2014上也有一篇精彩的演讲,作者使用局部敏感的哈希来实现类似的结果。
但是,我很好奇我是否可以使用这些论文必须检测到的任何重复关系,而不仅仅是依靠字符串匹配。
该图如下所示:
我们将从编写查询开始,以查看不同的Taos论文有多少个通用参考文献:
MATCH (r:Resource {id: "168640"})-[:REFERENCES]->(other)
WITH r, COLLECT(other) as myReferencesUNWIND myReferences AS reference
OPTIONAL MATCH path = (other)-[:REFERENCES]->(reference)
WITH other, COUNT(path) AS otherReferences, SIZE(myReferences) AS myReferences
WITH other, 1.0 * otherReferences / myReferences AS similarity WHERE similarity > 0.5RETURN other.id, other.title, similarity
ORDER BY similarity DESC
LIMIT 10
╒════════╤═══════════════════════════════════════════╤══════════╕
│other.id│other.title │similarity│
╞════════╪═══════════════════════════════════════════╪══════════╡
│168640 │Authentication in the Taos operating system│1 │
├────────┼───────────────────────────────────────────┼──────────┤
│174614 │Authentication in the Taos operating system│1 │
└────────┴───────────────────────────────────────────┴──────────┘
该查询:
- 选择道教论文之一并找到参考
- 查找其他引用相同论文的论文
- 根据他们有多少个普通参考文献来计算相似性分数
- 返回具有超过50%的相同参考文献的论文,而最相似的论文在顶部
我在其他论文上尝试了一下,看看效果如何:
Firefly RPC的性能
╒════════╤════════════════════════════════════════════════════════════════╤══════════════════╕
│other.id│other.title │similarity │
╞════════╪════════════════════════════════════════════════════════════════╪══════════════════╡
│74859 │Performance of Firefly RPC │1 │
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│77653 │Performance of the Firefly RPC │0.8333333333333334│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│110815 │The X-Kernel: An Architecture for Implementing Network Protocols│0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│96281 │Experiences with the Amoeba distributed operating system │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│74861 │Lightweight remote procedure call │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│106985 │The interaction of architecture and operating system design │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│77650 │Lightweight remote procedure call │0.6666666666666666│
└────────┴────────────────────────────────────────────────────────────────┴──────────────────┘
分布式系统中的认证:理论与实践
╒════════╤══════════════════════════════════════════════════════════╤══════════════════╕
│other.id│other.title │similarity │
╞════════╪══════════════════════════════════════════════════════════╪══════════════════╡
│121160 │Authentication in distributed systems: theory and practice│1 │
├────────┼──────────────────────────────────────────────────────────┼──────────────────┤
│138874 │Authentication in distributed systems: theory and practice│0.9090909090909091│
└────────┴──────────────────────────────────────────────────────────┴──────────────────┘
遗憾的是,这并不像在参考文献中找到100%匹配项那么简单! 我希望以后的论文修订会增加更多的内容,因此会增加参考文献。
如果我们也寻找作者相似之处怎么办?
MATCH (r:Resource {id: "121160"})-[:REFERENCES]->(other)
WITH r, COLLECT(other) as myReferencesUNWIND myReferences AS reference
OPTIONAL MATCH path = (other)-[:REFERENCES]->(reference)
WITH r, other, authorSimilarity, COUNT(path) AS otherReferences, SIZE(myReferences) AS myReferences
WITH r, other, authorSimilarity, 1.0 * otherReferences / myReferences AS referenceSimilarity
WHERE referenceSimilarity > 0.5MATCH (r)<-[:AUTHORED]-(author)
WITH r, myReferences, COLLECT(author) AS myAuthorsUNWIND myAuthors AS author
OPTIONAL MATCH path &#61; (other)<-[:AUTHORED]-(author)
WITH other, myReferences, COUNT(path) AS otherAuthors, SIZE(myAuthors) AS myAuthors
WITH other, myReferences, 1.0 * otherAuthors / myAuthors AS authorSimilarity
WHERE authorSimilarity > 0.5RETURN other.id, other.title, referenceSimilarity, authorSimilarity
ORDER BY (referenceSimilarity &#43; authorSimilarity) DESC
LIMIT 10
╒════════╤══════════════════════════════════════════════════════════╤═══════════════════╤════════════════╕
│other.id│other.title │referenceSimilarity│authorSimilarity│
╞════════╪══════════════════════════════════════════════════════════╪═══════════════════╪════════════════╡
│121160 │Authentication in distributed systems: theory and practice│1 │1 │
├────────┼──────────────────────────────────────────────────────────┼───────────────────┼────────────────┤
│138874 │Authentication in distributed systems: theory and practice│0.9090909090909091 │1 │
└────────┴──────────────────────────────────────────────────────────┴───────────────────┴────────────────┘
╒════════╤══════════════════════════════╤═══════════════════╤════════════════╕
│other.id│other.title │referenceSimilarity│authorSimilarity│
╞════════╪══════════════════════════════╪═══════════════════╪════════════════╡
│74859 │Performance of Firefly RPC │1 │1 │
├────────┼──────────────────────────────┼───────────────────┼────────────────┤
│77653 │Performance of the Firefly RPC│0.8333333333333334 │1 │
└────────┴──────────────────────────────┴───────────────────┴────────────────┘
我敢肯定&#xff0c;我还能找到其他一些论文&#xff0c;但这些相似之处都不奏效&#xff0c;但这是一个有趣的开始。
我认为下一步是建立一套训练对&#xff0c;这些训练对是相互相似和不相似的。 然后&#xff0c;我们可以训练一个分类器来确定两个文档是否相同。
但这是另一天&#xff01;
翻译自: https://www.javacodegeeks.com/2016/07/neo4j-cypher-detecting-duplicates-using-relationships.html
neo4j cypher





![[翻译]微服务设计模式5. 服务发现服务端服务发现](https://img7.php1.cn/3cdc5/ca23/525/3af55d7cf19345b9.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号