Balance-Tree & Balance+Tree
为什么索引这么快,一个好的索引能将检索速度提升几个量级,这种效率离不开这个数据结构
1.1 门路清
为什么需要"索引" ?
我们总得依据什么才能去找你想查的东西,那么我们就依据 id=1去寻找一条记录,怎么找呢? 难道是"顺序检索" ?
数据库里的东西现在大都大到分布在很多个磁盘页上。如果顺序检索基本就是噩梦。你知道"二分法" 比较快,那是因为数据已经被排过序了。 同样的如果现在存在一种排过序的数据结构,使得我们能快速去找出我们想要的东西在哪儿 ,这样一定很方便对吧。
所以归根到底,现在最大的问题的就是"这条记录到底存在哪" 。 解决办法是这样的:
- 依据这个键比如ID,去产生一个序号,这样就组成了 Key[序号]-Value[记录的位置] 的形式
- 这种K-V结构,会变成数据结构的一个节点。 到时候我们拿着ID,计算出序号,根据这个序号,在这种数据结构里畅游快速找到这个节点
- 找到对应节点后查找出记录的位置,去内存里取,完成" select * from users where id = 1 "
为什么叫它"索引" ?
在上面的介绍中我们已经看到了,实现快速找到内容的关键就是这个 "序号" 。这个所谓的序号就非常像"索引"这个名词
为什么不用二分法查找?
理论上,二分法已经是 O(logN), 非常快了。 实际上索引可能很多,多到你都没办法把索引全部加载到内存里,所以这些索引基本上都在磁盘里,依靠磁盘IO,分批次加载到内存里。
既然提到磁盘IO,就应该知道磁盘IO效率非常低,低到实际上就, 如果谁能减少磁盘IO次数,谁就会是最好的索引实现方案。
- 二分法一次两个节点
- 整个树非常的 "瘦高" ->
- 我们需要向下遍历很多层 ->
- 我们需要向下加载很多次磁盘IO -> 效率不高
- 我们想要把树变的矮胖,减少层数
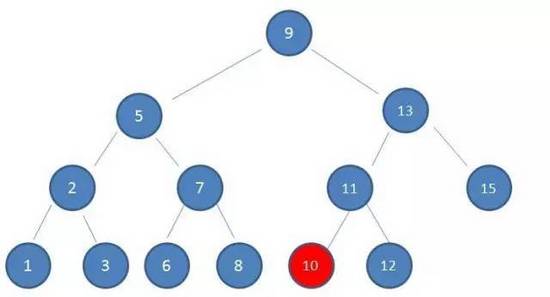
1.2 Balance-Tree

1.2.1 Balance-Tree中的节点为什么是这样子 ? 查询数据的过程
- 一个节点中会包含很多个键值对, 以及很多个 "指针p" 我们以 { 2 6 } 节点举例看里面有什么
- 节点内部是这样安排的 { [p1] [序号=2] [p2] [序号=6] [p3] }
- 假设一个现在 序号[6] 来了,正好能匹配上,前往6对应位置取回数据
- 假设一个现在 序号[3] 来了,[3] 不匹配任何,但是位于2~6之间, 前往p2继续寻找
- 假设一个现在 序号[1] 来了,[1] 不匹配任何, 且小于2,前往p1继续寻找
- 节点内的所有元素都已经排过序了,因此拿着[序号]来节点里查找的时候效率也比较高
刚刚,我们就走完了一个节点,我们完成了一轮查找。每一轮开始之前我们会先执行磁盘IO,把下一个节点对应内容从磁盘加载到内存里,然后再在组内查找,找得到就退出,找不到继续
根据上述结论,我们也能发现一个重要结论: 既然我们不能一次性把所有索引都加载到内存里,既然我们要分批次做磁盘IO。那树的高度其实就是我们IO的次数,那么矮树就会是最快的方案
func balance_tree_search (node *Node , key int) (*Data,error) {
if node == nil {
return nil,fmt.Errorf("最终也没能找到对应序号")
}
for _, pair := range node {
if (pair.Key == key){
return pair.Data,nil
}
if (pair.Key > key) {
// 考虑到节点内键值对是已经排序,从小到大的
// 那既然上个键值对不满足,这个键值对又过于大
// 那说明没有符合的,前往下一个节点
return balance_tree_search( pair.NextNode, key )
}
}
// 比节点内所有键值对都大,直接前往下一个
return balance_tree_search( pair.NextNode, key )
}
1.2.2 Balance-Tree的插入过程


- 现在是这样,因为BT不能允许一个节点里的有过多的键值对,因此当 [序号4] 过来的时候
- 实际节点 { 3 5 } 不能容纳 [序号4]
- 如果不能容纳,那么我们会一路向上找到能容纳的下的节点,于是我们找到根节点
- 相对应的,根节点变成两个,多出一个位置用于存放指针,相对应的树结构做出调整
- { [p1] [序号=4] [p2] } -> { [p1] [序号=4] [p2] [序号=9] [p3] }
自调整的过程虽然很漫长,看起来也很麻烦,但是这个恰好是满足了BT的自调整性质
1.2.3 Balance-Tree的删除过程


- 假设我们现在想要删除这个红色的节点,但是删除后 [序号12] 左边会缺少一个位置
- 于是我们现在需要调整一下,旋转一下,成为满足要求的Balance-Tree
1.2.4 Balance-Tree的定义
- 依据自旋转过程,保证树都是一样高的,m (也叫秩m)
- 每个节点上元素的数量 [m/2 ~ m]
- 节点上元素需要排序
1.3 Balance+Tree

- 在B+T中,中间节点并不会存储任何跟"数据在那儿"相关的信息,只会做数据索引,指引你前往叶子节点。
- 无论怎样你都要遍历一下叶子节点,比BT更加稳定
- 不需要前往中间节点,遍历全部数据的时候比BT快
- B+T所有节点都会按顺序保存好数据,并且所有叶子节点都是串在一起的,这样当数据来的时候我们只要按照粉色的路径一路寻找就好了
关于索引,你需要知道
2.1 多个列,组合索引
- 在你 create table 的时候假设你定义出 A+B+C 成为你的组合索引,你需要知道这三列现在开始是不等价的,实际上这里面只有第一列 A 重量级最高
- 在上面我们提到了[序号],那么 A+B+C 现在就是这条数据的序号,在进行索引比较的时候会 先比较A,A相同了比较B,B相同了再去比较C
- 多说一句,我们不喜欢使用字符串作为索引的原因,是因为"字符串比较" 会比 "整数比较" 开销更大,那种很长的字符串比较就更是麻烦了
- A重量级最高: 如果你想真的从索引中受益,那么你的WHERE筛选条件中一定要带上这个重量级最高的A,否则索引没有真的发挥作用,举个例子,你可以这么使用索引
- WHERE A=1 (首列精确匹配)
- WHERE A IS LIKE 1 (首列的近似匹配)
- WHERE A=1 AND B IS LIKE 2 (首列精确,二列近似)
- 如果你尝试在筛选条件里不带上A,那么本次查找索引就根本没有发挥作用
- 我们都知道 BT&B+T 能拥有一个很良好的"排序性质",我们既然能按照 排序 的方式快速找到一个键值对,那么在BT&B+T为基础的索引上
- 完成 ORDER BY 很快
- 完成范围查找很快 -> B IS IN ( 20,100 )
2.2 哈希索引
假设我们定义出A+B+C作为索引列,哈希索引就是针对每一条记录计算出hash(A,B,C) 对应的值是这条记录存储的位置,哈希索引非常快,但是也有自身对应的一些弊端
- 因为已经没有排序结构了,因此ORDER BY 功能已经没有那么快了
- 哈希功能需要所有索引列参与,你不能在只有B&C的情况下去指望使用上哈希索引
2.2.1 哈希冲突
假设现在两条记录能哈希出同一个值,这种时候:
// 如果只依赖hash 则返回两条记录
SELECT * FROM users WHERE hash(name) = 1;
>> liangxiaohan 23 M
zhangxiaoming 24 F
// 最好的办法是不仅使用hash同时也指定索引列自身的值
// hash冲突下,形成链表,存储引擎遍历链表所有行
SELECT * FROM users WHERE hash(name) = 1 and name = "liangxiaohan"
>> liangxiaohan 23 M
2.2.2 自创索引
InnoDB支持哈希,但他的支持是指,它会自优化你的B树索引成为"某种程度上的"哈希索引。针对这一点,你可以自己实现一个简单的哈希索引
// 更新表,新建一列用于存放哈希值
ALTER TABLE ADD COLUMN name_crc VARCHAR(20)
// 关于哈希值,你可以使用 TRIGGER 实现自动插入
// 你只负责插入name就行了,关于crc32哈希值它每次会自己计算
CREATE TRIGGER crc_create BEFORE INSERT ON users
FOR EACH ROW SET NEW.name_crc = crc32(NEW.name)
2.3 聚簇索引
2.3.1 关于聚簇索引,你需要知道
- 聚簇索引 并不是一种新型的索引,它所代表的只是一种数据存储方式
- 在聚簇索引,相当于一种变形B+T
- 它的中间节点同样不负责存储任何数据
- 它的叶子节点会存下这条记录的所有内容实体,而不是一个指针
- 叶子节点首位相接
- 一个表只能有一个聚簇索引:按照聚簇索引的要求,数据会被存在一个指定的位置。但是数据不能既在这里又在哪里,所以只能有一个聚簇索引
- 它之所以被叫做“聚簇” : 是因为按照索引的要求,数据全都被存储在了指定位置,并且索引上相邻的位置,他们也存储的很近
2.3.2 聚簇索引的优点 & 缺点
- 优点
- "聚簇"可能可以发挥出很大的威力: 假设我们令用户ID成为聚簇索引,那么这个用户可能所有相关的信息全存在一起,我们有可能存在一次IO读取所有邮件
- 访问更快: 聚簇索引将索引+数据全都保存在同一个BT中,读数据通常更快
- 缺点
- 假设一个应用,像是读邮件这种应用,本质上是IO密集应用,如果这种时候我们能好好利用聚簇索引,效果卓群。但是如果数据全都存在内存中,并不涉及磁盘IO那就没有多少优势了
- 最大的问题: 执行插入的速度 。 因为在聚簇索引中,所有的数据已经是直接存在B+T中并且排序了,那么问题就来了
- 如果我按照聚簇索引顺序插入 -> 速度很快
- 如果我随机插入 -> 涉及数据的复制移动等,速度感人
- 还是关于聚簇的随机插入: 页分裂。 假设现在一个内存页已经填满了数据,但是现在有一个数据试图在中间插入,存储引擎会将这一页分裂成两页,将第一页的一部分复制到第二页去
- 效率极低
- 产生内存碎片
- 因为内存不连续导致扫描全表变慢
- 如果真的要随机插入,记得在插入完成以后使用 OPTIOMIZE TABLE 重新整理内存




![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号