作者:酱油丸子-310 | 来源:互联网 | 2023-08-30 20:57
一.数据备份的意义
(1)保护数据的安全;
(2)在出现意外的时候(硬盘的损坏,断电,黑客的攻击),以便数据的恢复;
(3)导出生产的数据以便研发人员或者测试人员测试学习;
(4)高权限的人员操作失误导致数据丢失,以便恢复;
二.数据库的备份类型
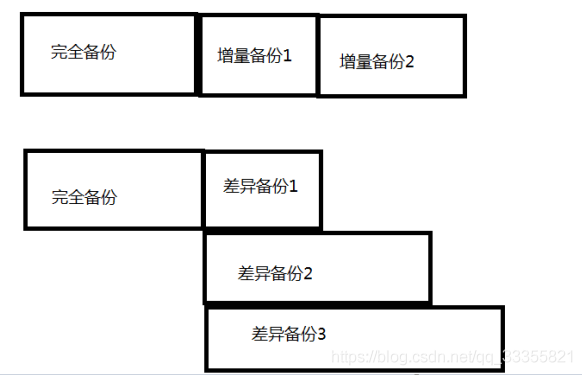
(1)完全备份:对整个数据库的数据进行备份
(2)部分备份:对部分数据进行备份(可以是一张表也可以是多张表)
增量备份:是以上一次备份为基础来备份变更数据的,节约空间
差异备份:是以第一次完全备份的基础来备份变更备份的,浪费空间
三.数据备份的方式
(1)逻辑备份:直接生成sql语句保存起来,在恢复数据的时候执行备份的sql语句来实现数据的恢复
(2)物理备份:直接拷贝相关的物理数据
区别:逻辑备份效率低,恢复数据效率低,但是逻辑备份节约空间;物理备份浪费空间,但是相对逻辑备份而言效率比
较高
四.mysql自带命令mysqldump来备份单库或者多库
mysqldump是mysql自带的命令,可以利用他来导出数据库数据,一般是放在mysql的安装目录的bin目录下,我的是在/usr/local/mysql/bin下面:

注意:
1.使用mysqldump备份最好不要把备份的数据放在与源mysql数据库同一台服务器上,之前备份的意义中有提到,当服务器的磁盘发生损坏的时候,整个服务器炸了的情况下,备份数据与源数据放在一台服务器上那么备份也就没有了意义,都是不可用的。
2.mysqldump是属于完全备份,是备份整个库或者整个表,不是增量备份,并且是逻辑备份
(1) mysqldump使用语法:
mysqldump -u 用户(需要备份数据库的用户) -h host(需要备份的数据库的ip) -p 密码(需要备份的数据库的密码) dbname(需要备份的库名) table(需要备份的表名) > 路径(备份到本机哪个目录下)
在本机备份则-h选项可以不加
(2) mysqldump比较重要的参数(红色是常用比较重要的):
- -?, –help: 显示帮助信息,英文的;
- -u, –user: 指定连接的用户名;
- -p, –password: 指定用户的密码,可以交互输入密码;
- -S , –socket: 指定socket文件连接,本地登录才会使用。
- -h, –host: 指定连接的服务器名称或者IP。
- -P, –port=: 连接数据库监听的端口。
- –default-character-set: 设置字符集,默认是UTF8。
- -A, –all-databases: 导出所有数据库。不过默认情况下是不会导出information_schema库。
- -B, –databases: 导出指定的某个/或者某几个数据库,参数后面所有名字参量都被看作数据库名,包含CREATE DATABASE创建库的语句。
- –tables: 导出指定表对象,参数格式为“库名 表名”,默认该参数将覆盖-B/–databases参数。
- -w, –where: 只导出符合条件的记录。
- -l, –lock-tables: 默认参数,锁定读取的表对象,想导出一致性备份的话最后使用该参数,会导致无法对表执行写入操作。
- –single-transaction:
- 该选项在导出数据之前提交一个BEGIN SQL语句,BEGIN 不会阻塞任何应用程序且能保证导出时数据库的一致性状态。它只适用于多版本存储 引擎,仅InnoDB。本选项和–lock-tables 选项是互斥的,因为LOCK TABLES 会使任何挂起的事务隐含提交,使用参数–single-transaction会自动关闭该选项。
- 在InnoDB导出时会建立一致性快照,在保证导出数据的一致性前提下,又不会堵塞其他会话的读写操作,相比–lock-tables参数来说锁定粒度要低,造成的影响也要小很多。指定这个参数后,其他连接不能执行ALTER TABLE、DROP TABLE 、RENAME TABLE、TRUNCATE TABLE这类语句,事务的隔离级别无法控制DDL语句。
- -d, –no-data: 只导出表结构,不导出表数据。
- -t, –no-create-info: 只导出数据,而不添加CREATE TABLE 语句。
- -f, –force: 即使遇到SQL错误,也继续执行,功能类似Oracle exp命令中的ignore参数。
- -F, —flush-logs: 在执行导出前先刷新日志文件,视操作场景,有可能会触发多次刷新日志文件。一般来说,如果是全库导出,建议先刷新日志文件,否则就不用了,刷新日志的意思也就是新建一个binlog日志,后面的语句都从新的日志开始记录,方便恢复的时候寻找。
- –master-data[=#]: 该选项将当前备份时候二进制日志的位置和文件名写入到输出中。该选项要求有RELOAD权限,并且必须启用二进制日志。如果该选项值等于1,位置和文件名被写入CHANGE MASTER语句形式的转储输出,如果你使用该SQL转储主服务器以设置从服务器,从服务器从主服务器二进制日志的正确位置开始。如果选项值等于2,CHANGE MASTER语句被写成SQL注释。如果value被省略,这是默认动作,也就是说-master-data=1会将CHANGE MASTER语句写入备份文件中,-master-data=2也会写入备份文件中,只不过会注释掉
- –master-data选项会启用–lock-all-tables,除非还指定–single-transaction(在这种情况下,只在刚开始转储时短时间获得全局读锁定。又见–single-transaction。在任何一种情况下,日志相关动作发生在转储时。该选项自动关闭–lock-tables。
- 所以,我在INNODB引擎的数据库备份时,我会同时使用–master-data=2 和 –single-transaction两个选项。
- -n, –no-create-db: 不生成建库的语句CREATE DATABASE … IF EXISTS,即使指定–all-databases或–databases这类参数。
- –triggers: 导出表的触发器脚本,默认就是启用状态。使用–skip-triggers禁用它。
- -R, –routines: 导出存储过程以及自定义函数。
- 在转储的数据库中转储存储程序(函数和程序)。
- -E, –events: 输出event。
- –ignore-table: 指定的表对象不做导出,参数值的格式为[db_name,tblname],注意每次只能指定一个值,如果有多个表对象都不进行导出操作的话,那就需要指定多个–ignore-table参数,并为每个参数指定不同的参数值。
- –add-drop-database: 在任何创建库语句前,附加DROP DATABASE 语句。
- –add-drop-table: 在任何创建表语句前,附加DROP TABLE语句。这个参数是默认启用状态,可以使用– skip-add-drop-table参数禁用该参数。
- –add-drop-trigger: 创建任何触发器前,附加DROP TRIGGER语句。
- –add-locks: 在生成的INSERT语句前附加LOCK语句,该参数默认是启用状态。使用–skip-add-locks参数禁用。
- -K, –disable-keys: 在导出的文件中输出 ‘/!40000 ALTER TABLE tb_name DISABLE KEYS */; 以及
- ‘/!40000 ALTER TABLE tb_name ENABLE KEYS */; ‘ 等信息。这两段信息会分别放在INSERT语句的前后,也就是说,在插入数据前先禁用索引,等完成数据插入后再启用索引,目的是为了加快导入的速度。该参数默认就是启用状态。可以通过–skip-disable-keys参数来禁用。
- –opt: 功能等同于同时指定了 –add-drop-table, –add-locks, –create-options, –quick, –extended-insert, –lock-tables, –set-charset, 以及 –disable-keys这些参数。默认就是启用状态。使用–skip-opt来禁用该参数。
- –skip-opt: 禁用–opt选项,相当于同时禁用 –add-drop-table, –add-locks, –create-options, –quick, –extended-insert, –lock-tables, –set-charset, 及 –disable-keys这些参数。
- -q, –quick: 导出时不会将数据加载到缓存,而是直接输出。默认就是启用状态。可以使用–skip-quick 来禁用该参数。
(3)远程备份单库例子(将远程192.168.10.101 的test1库的数据备份到本机/usr/local/mysqlData目录下)
这里并不会备份建库的语句,只有建表还有表数据的语句。
mysqldump -uroot -proot -h192.168.10.101 test1 > /usr/local/mysqlData/test1.sql
(4)远程备份单库例子并保留创建库语句(需要加上--databases属性):
mysqldump -uroot -proot -h192.168.10.101 --databases test1 > /usr/local/mysqlData/test1.sql
(5)远程备份单库单表的例子:
mysqldump -uroot -proot -h192.168.10.101 test1 user > /usr/local/mysqlData/test1_user.sql
(6)远程备份多库的例子
mysqldump -uroot -proot -h192.168.10.101 --databases test1 test2 > /usr/local/mysqlData/test1_test2.sql
(7)远程备份全库的例子:
mysqldump -uroot -proot -h192.168.10.101 --all-databases > /usr/local/mysqlData/test1_all.sql
(8)备份全库,并截断二进制日志,加上master-data参数
mysqldump -uroot -p'Qqmima917@' --all-databases --single-transaction --master-data=1 --flush-logs > `date +%F`-mysql-all.sql;
(9)只导出mdc库的data_alarm表的deviceId为636136575130275840的数据,并且只导出数据
mysqldump -ucadmin -p1q2w3e -t qa_mdc data_alarm --where="DeviceId=636136575130275840"> alarm.sql
五.数据恢复
(1)远程恢复数据(备份的数据文件里有创建库的语句):
前面的-u,-p,-h都是需要恢复数据库到哪台数据库服务器的信息。
注意:必须在存放备份数据目录下执行命令,不然<后面就要加全路径
mysql -uroot -proot -h192.168.10.101 (2)远程恢复数据(备份的数据文件里没有创建库的语句):
如果备份的时候没有写建库语句,并且数据库又被删了,这时候就可以使用这种方式进行数据恢复,只要在<前面加上库名就行
mysql -uroot -proot -h192.168.10.101 test1




 京公网安备 11010802041100号
京公网安备 11010802041100号