lLucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开发源代码的全文检索引擎工具包。它是一个很强大的搜索库,能轻易的将搜索功能加入到任何程序中。能对文档搜索,文档内信息搜索或相关文档进行搜索等操作,源码由java实现,是一个成熟,卡原的检索工具。
lucene的整体架构如下:
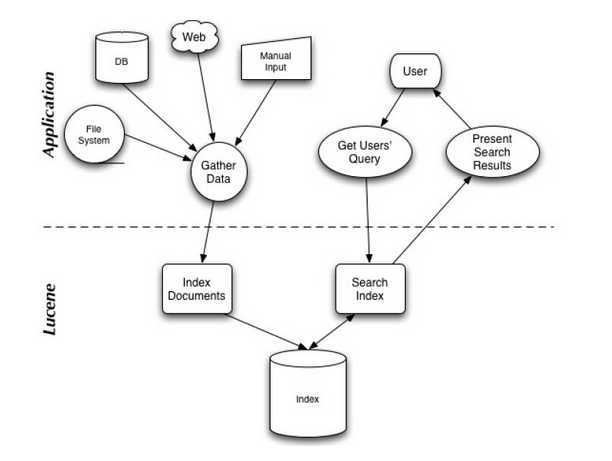
从图中,我们可以看出,主要分为两个大步骤,一个是建立索引的过程,一个是通过关键字查找索引搜索的过程。
索引过程,可以从DB,web,文件系统等来源抓取原始数据,对该数据通过以某种方式,对某些内容,建立索引文档。
搜索过程,通过对用户搜索的关键字,通过分词等构造得到查询关键字的索引,进而从索引库中找到相关内容。
从构建索引和搜索两个过程,来介绍lucene的使用。
首先,得了解使用lucene的几个基本类。
索引过程:
1,indexWirter
indexWriter是写索引的关键组件。这个类负责创建,打开或关闭索引,并想索引中写入内容。不过IndexWrier需要一个空间来储存内容,这个由Directory完成。
2,Directory
directory描述了lucene的储存路径。每个directory对应一个索引库。
3,Analysis
该类是对文档索引之前的操作,文档再索引之前会经过分词器的处理,比如一行“hello world",对空格处理的分词器就将该内容分成两个部分”hello“,”world",大写也有可能会都变成小写。这一些在索引之前的一些操作由分词器来操作。
4,Field
该类是保存一个文档中的的基本单位,也可以理解为一个文档中的一个属性。lucene中有不同的Field类,比如字符串类型,整型等,同时Field还有很多设置选项,比如该Field是否存储,是否被索引,已经存储格式等。是Document中携带信息单元。
5,document
document字面上意思就是一个文档,一个document是索引保存记录的基本单位,索引中保存的位置什么的就是document的位置信息,和db比较,可以理解为一个表中的一行记录。它代表一些域Field的集合。
下面是一个索引过程的基本代码(lucene版本5.4.1)
Analyzer analyzer = new SimpleAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setRAMBufferSizeMB(bufferMB);
config.setMaxBufferedDocs(bufferSize);
String path = "D:\\repositoryName";
Directory index = FSDirectory.open(Paths.get(path));
IndexWriter writer = new IndexWriter(index, config);
for (int i = 0; i <100; i++) {
Document doc = new Document();
doc.add(newStringField("msid", record.getMsid(),
Field.Store.YES));
doc.add(new StringField("city", record.getCity(),
Field.Store.YES));
writer.add(doc);
}
writer.close();
检索过程:
1,Term
Term是搜索功能的基本单元,和构建索引过程的Field类似,不过Field可能会被分词成几个单元。term包含的是搜索的字段名称,以及对应搜索的内容。
2,IndexReader,indexSearcher
indexReader与indexWriter想对应。indexWriter是对索引的写入,而indexReader是对索引的读取。indexSearcher则是在indexReader上构建的一个搜索入口对象。
3,Query
query指的就是查询,query是指的查询的条件,有一个或多个Term构成。同时query有很多子类,分别对应不同类型,不同范围的查询。
4,TopDocs
topDocs是查询结果集,indexSearcher查询条件query得到的结果。包含的是结果document的id。
搜索过程基本代码:
String path ="D:\\repositoryName";
Directory index = FSDirectory.open(Paths.get(path));
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = new TermQuery(new Term("msid","ttt"));
List retList = new ArrayList();
TopScoreDocCollector collector = TopScoreDocCollector.create(maxResultCount);
searcher.search(query, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs;
for(int i=0;ii) {
int docId = hits[i].doc;
Document document = searcher.doc(docId);
String msid = document.get("msid");
}
reader.close();
以上是lucene的一个最基本的功能构建索引与搜索的简单代码,能快速入手使用。
lucene介绍

![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号