Table of Contents
Slob, Slab VS Slub
Overview
slub分配器
Linux slab 分配器剖析
动态内存管理
slab 缓存
slab 背后的动机
API 函数
kmem_cache_create
kmem_cache_destroy
kmem_cache_alloc
kmem_cache_zalloc
kmem_cache_free
kmalloc 和 kfree
其他函数
slab 缓存的示例用法
slab 的 proc 接口
SLOB 分配器
结束语
原文地址:
First, "slab" has become a generic name referring to a memory allocation strategy employing an object cache, enabling efficient allocation and deallocation of kernel objects. It was first documented by Sun engineer Jeff Bonwick and implemented in the Solaris 2.4 kernel.1
Linux currently offers three choices for its "slab" allocator :
Slab is the original, based on Bonwick's seminal paper and available since Linux kernel version 2.2. It is a faithful implementation of Bonwick's proposal, augmented by the multiprocessor changes described in Bonwick's follow-up paper2.
Slub is the next-generation replacement memory allocator, which has been the default in the Linux kernel since 2.6.23. It continues to employ the basic "slab" model, but fixes several deficiencies in Slab's design, particularly around systems with large numbers of processors. Slub is simpler than Slab.
SLOB (Simple List Of Blocks) is a memory allocator optimized for embedded systems with very little memory—on the order of megabytes. It applies a very simple first-fit algorithm on a list of blocks, not unlike the old K&R-style heap allocator. In eliminating nearly all of the overhad from the memory allocator, SLOB is a good fit for systems under extreme memory constraints, but it offers none of the benefits described in 1 and can suffer from pathological fragmentation.
作者:itrocker 发布于:2015-12-21 18:51 分类:内存管理
Linux的物理内存管理采用了以页为单位的buddy system(伙伴系统),但是很多情况下,内核仅仅需要一个较小的对象空间,而且这些小块的空间对于不同对象又是变化的、不可预测的,所以需要一种类似用户空间堆内存的管理机制(malloc/free)。然而内核对对象的管理又有一定的特殊性,有些对象的访问非常频繁,需要采用缓冲机制;对象的组织需要考虑硬件cache的影响;需要考虑多处理器以及NUMA架构的影响。90年代初期,在Solaris 2.4操作系统中,采用了一种称为“slab”(原意是大块的混凝土)的缓冲区分配和管理方法,在相当程度上满足了内核的特殊需求。
多年以来,SLAB成为linux kernel对象缓冲区管理的主流算法,甚至长时间没有人愿意去修改,因为它实在是非常复杂,而且在大多数情况下,它的工作完成的相当不错。但是,随着大规模多处理器系统和 NUMA系统的广泛应用,SLAB 分配器逐渐暴露出自身的严重不足:
1). 缓存队列管理复杂;
2). 管理数据存储开销大;
3). 对NUMA支持复杂;
4). 调试调优困难;
5). 摒弃了效果不太明显的slab着色机制;
针对这些SLAB不足,内核开发人员Christoph Lameter在Linux内核2.6.22版本中引入一种新的解决方案:SLUB分配器。SLUB分配器特点是简化设计理念,同时保留SLAB分配器的基本思想:每个缓冲区由多个小的slab 组成,每个 slab 包含固定数目的对象。SLUB分配器简化kmem_cache,slab等相关的管理数据结构,摒弃了SLAB 分配器中众多的队列概念,并针对多处理器、NUMA系统进行优化,从而提高了性能和可扩展性并降低了内存的浪费。为了保证内核其它模块能够无缝迁移到SLUB分配器,SLUB还保留了原有SLAB分配器所有的接口API函数。
(注:本文源码分析基于linux-4.1.x)
整体数据结构关系如下图所示:
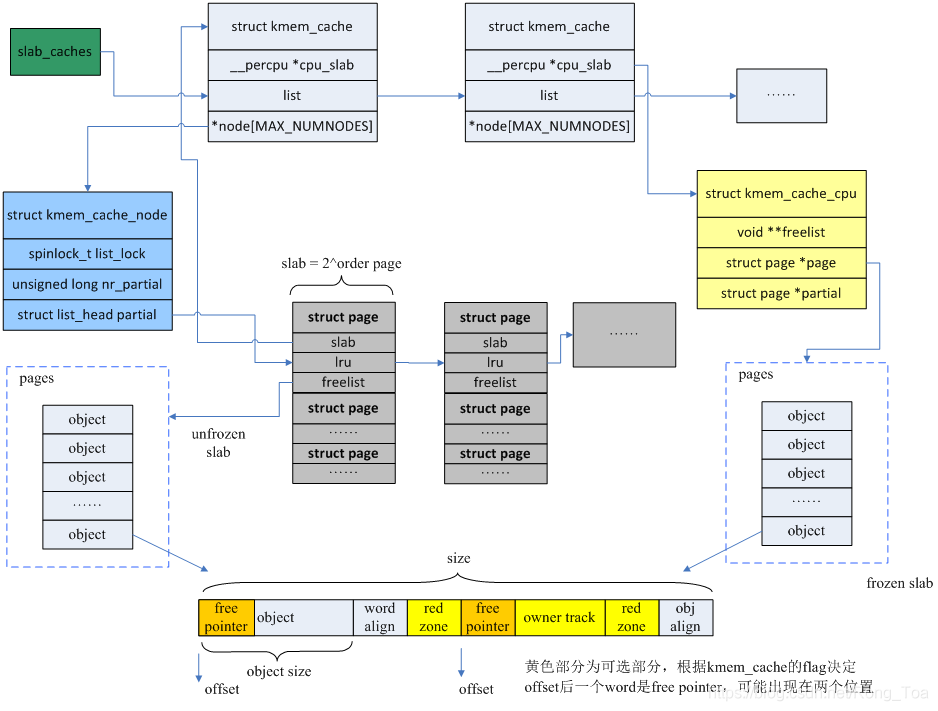
1 SLUB分配器的初始化
SLUB初始化有两个重要的工作:第一,创建用于申请struct kmem_cache和struct kmem_cache_node的kmem_cache;第二,创建用于常规kmalloc的kmem_cache。
1.1 申请kmem_cache的kmem_cache
第一个工作涉及到一个“先有鸡还是先有蛋”的问题,因为创建kmem_cache需要从kmem_cache的缓冲区申请,而这时候还没有创建kmem_cache的缓冲区。kernel的解决办法是先用两个静态变量boot_kmem_cache和boot_kmem_cache_node来保存struct kmem_cach和struct kmem_cache_node缓冲区管理数据,以两个静态变量为基础申请大小为struct kmem_cache和struct kmem_cache_node对象大小的slub缓冲区,随后再从这些缓冲区中分别申请两个kmem_cache,然后把boot_kmem_cache和boot_kmem_cache_node中的内容拷贝到新申请的对象中,从而完成了struct kmem_cache和struct kmem_cache_node管理结构的bootstrap(自引导)。
void __init kmem_cache_init(void)
{//声明静态变量,存储临时kmem_cache管理结构static __initdata struct kmem_cache boot_kmem_cache,boot_kmem_cache_node;
•••kmem_cache_node = &boot_kmem_cache_node;kmem_cache = &boot_kmem_cache;//申请slub缓冲区,管理数据放在临时结构中create_boot_cache(kmem_cache_node, "kmem_cache_node",sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);create_boot_cache(kmem_cache, "kmem_cache",offsetof(struct kmem_cache, node) +nr_node_ids * sizeof(struct kmem_cache_node *),SLAB_HWCACHE_ALIGN);//从刚才挂在临时结构的缓冲区中申请kmem_cache的kmem_cache,并将管理数据拷贝到新申请的内存中kmem_cache = bootstrap(&boot_kmem_cache);//从刚才挂在临时结构的缓冲区中申请kmem_cache_node的kmem_cache,并将管理数据拷贝到新申请的内存中kmem_cache_node = bootstrap(&boot_kmem_cache_node);
•••
}
1.2 创建kmalloc常规缓存
原则上系统会为每个2次幂大小的内存块申请一个缓存,但是内存块过小时,会产生很多碎片浪费,所以系统为96B和192B也各自创建了一个缓存。于是利用了一个size_index数组来帮助确定小于192B的内存块使用哪个缓存
void __init create_kmalloc_caches(unsigned long flags)
{
•••/*使用SLUB时KMALLOC_SHIFT_LOW=3,KMALLOC_SHIFT_HIGH=13也就是说使用kmalloc能够申请的最小内存是8B,最大内存是8KB申请内存是向上对其2的n次幂,创建对应大小缓存保存在kmalloc_caches [n]*/for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {if (!kmalloc_caches[i]) {kmalloc_caches[i] = create_kmalloc_cache(NULL,1 <
}
2 缓存的创建与销毁
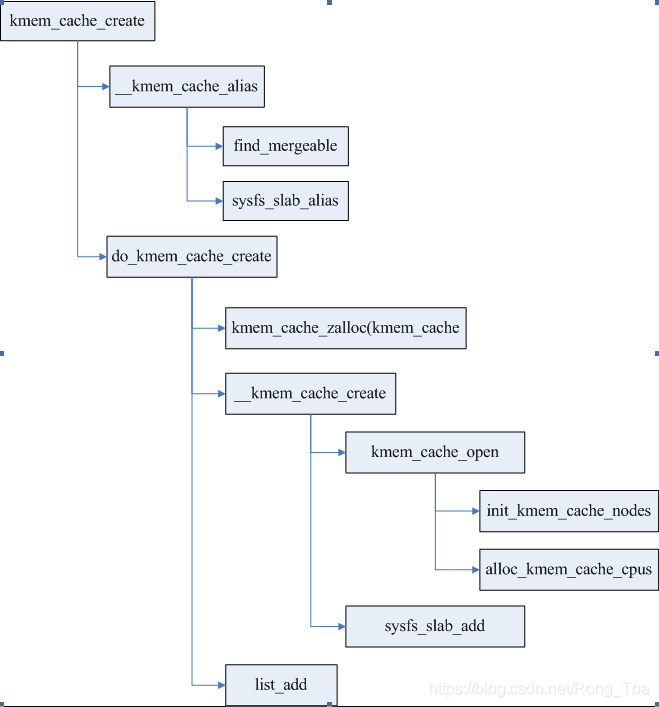
2.1 缓存的创建
创建缓存通过接口kmem_cache_create进行,在创建新的缓存以前,尝试找到可以合并的缓存,合并条件包括对对象大小以及缓存属性的判断,如果可以合并则直接返回已存在的kmem_cache,并创建一个kobj链接指向同一个节点。
创建新的缓存主要是申请管理结构暂用的空间,并初始化,这些管理结构包括kmem_cache、kmem_cache_nodes、kmem_cache_cpu。同时在sysfs创建kobject节点。最后把kmem_cache加入到全局cahce链表slab_caches中。
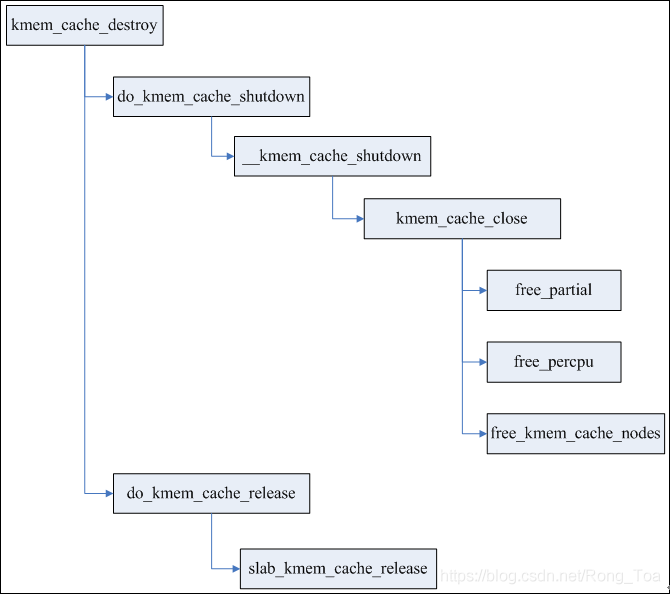
2.2 缓存的销毁
销毁过程比创建过程简单的多,主要工作是释放partial队列所有page,释放kmem_cache_cpu,释放每个node的kmem_cache_node,最后释放kmem_cache本身。
3 申请对象
对象是SLUB分配器中可分配的内存单元,与SLAB相比,SLUB对象的组织非常简洁,申请过程更加高效。SLUB没有任何管理区结构来管理对象,而是将对象之间的关联嵌入在对象本身的内存中,因为申请者并不关心对象在分配之前内存的内容是什么。而且各个SLUB之间的关联,也利用page自身结构进行处理。
每个CPU都有一个slab作为本地高速缓存,只要slab所在的node与申请者要求的node匹配,同时该slab还有空闲对象,则直接在cpu_slab中取出空闲对象,否则就进入慢速路径。
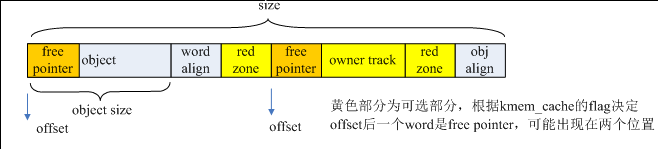
每个对象内存的offset偏移位置都存放着下一个空闲对象,offset通常为0,也就是复用对象内存的第一个字来保存下一个空闲对象的指针,当满足条件(flags & (SLAB_DESTROY_BY_RCU | SLAB_POISON)) 或者有对象构造函数时,offset不为0,每个对象的结构如下图。
cpu_slab的freelist则保存着当前第一个空闲对象的地址。
如果本地CPU缓存没有空闲对象,则申请新的slab;如果有空闲对象,但是内存node不相符,则deactive当前cpu_slab,再申请新的slab。
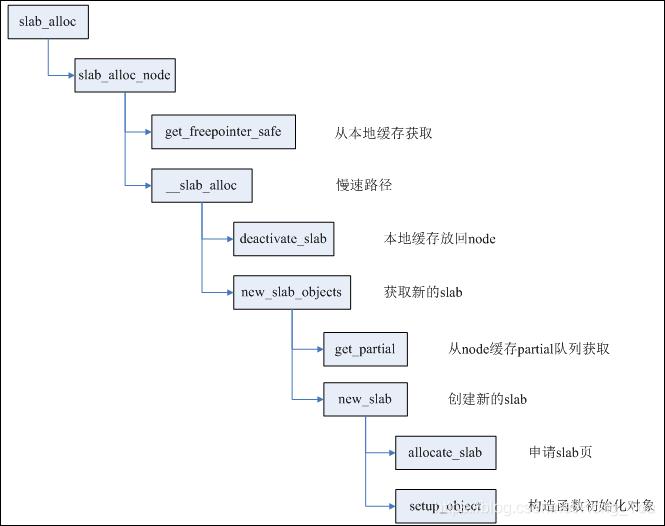
deactivate_slab主要进行两步工作:
第一步,将cpu_slab的freelist全部释放回page->freelist;
第二部,根据page(slab)的状态进行不同操作,如果该slab有部分空闲对象,则将page移到kmem_cache_node的partial队列;如果该slab全部空闲,则直接释放该slab;如果该slab全部占用,而且开启了CONFIG_SLUB_DEBUG编译选项,则将page移到full队列。
page的状态也从frozen改变为unfrozen。(frozen代表slab在cpu_slub,unfroze代表在partial队列或者full队列)。
申请新的slab有两种情况,如果cpu_slab的partial队列不为空,则取出队列中下一个page作为新的cpu_slab,同时再次检测内存node是否相符,还不相符则循环处理。
如果cpu_slab的partial队列为空,则查看本node的partial队列是否为空,如果不空,则取出page;如果为空,则看一定距离范围内其它node的partial队列,如果还为空,则需要创建新slab。
创建新slab其实就是申请对应order的内存页,用来放足够数量的对象。值得注意的是其中order以及对象数量的确定,这两者又是相互影响的。order和object数量同时存放在kmem_cache成员kmem_cache_order_objects中,低16位用于存放object数量,高位存放order。order与object数量的关系非常简单:((PAGE_SIZE <
下面重点看calculate_order这个函数
static inline int calculate_order(int size, int reserved)
{
•••//尝试找到order与object数量的最佳配合方案//期望的效果就是剩余的碎片最小min_objects = slub_min_objects;if (!min_objects)min_objects = 4 * (fls(nr_cpu_ids) + 1);max_objects = order_objects(slub_max_order, size, reserved);min_objects = min(min_objects, max_objects);//fraction是碎片因子,需要满足的条件是碎片部分乘以fraction小于slab大小// (slab_size - reserved) % size <= slab_size / fractionwhile (min_objects > 1) {fraction = 16;while (fraction >= 4) {order = slab_order(size, min_objects,slub_max_order, fraction, reserved);if (order <= slub_max_order)return order;//放宽条件,容忍的碎片大小增倍fraction /= 2;}min_objects--;}//尝试一个slab只包含一个对象order = slab_order(size, 1, slub_max_order, 1, reserved);if (order <= slub_max_order)return order;//使用MAX_ORDER且一个slab只含一个对象order = slab_order(size, 1, MAX_ORDER, 1, reserved);if (order
4 释放对象
从上面申请对象的流程也可以看出,释放的object有几个去处:
1)cpu本地缓存slab,也就是cpu_slab;
2)放回object所在的page(也就是slab)中;另外要处理所在的slab:
2.1)如果放回之后,slab完全为空,则直接销毁该slab;
2.2)如果放回之前,slab为满,则判断slab是否已被冻结;如果已冻结,则不需要做其他事;如果未冻结,则将其冻结,放入cpu_slab的partial队列;如果cpu_slab partial队列过多,则将队列中所有slab一次性解冻到各自node的partial队列中。
值得注意的是cpu partial队列的功能是个可选项,依赖于内核选项CONFIG_SLUB_CPU_PARTIAL,如果没有开启,则不使用cpu partial队列,直接使用各个node的partial队列。
M. Jones,2010 年 9 月 20 日发布
内存管理的目标是提供一种方法,为实现各种目的而在各个用户之间实现内存共享。内存管理方法应该实现以下两个功能:
内存管理实际上是一种关于权衡的零和游戏。您可以开发一种使用少量内存进行管理的算法,但是要花费更多时间来管理可用内存。也可以开发一个算法来有效地管理内存,但却要使用更多的内存。最终,特定应用程序的需求将促使对这种权衡作出选择。
每个内存管理器都使用了一种基于堆的分配策略。在这种方法中,大块内存(称为 堆)用来为用户定义的目的提供内存。当用户需要一块内存时,就请求给自己分配一定大小的内存。堆管理器会查看可用内存的情况(使用特定算法)并返回一块内存。搜索过程中使用的一些算法有 first-fit(在堆中搜索到的第一个满足请求的内存块 )和 best-fit(使用堆中满足请求的最合适的内存块)。当用户使用完内存后,就将内存返回给堆。
这种基于堆的分配策略的根本问题是碎片(fragmentation)。当内存块被分配后,它们会以不同的顺序在不同的时间返回。这样会在堆中留下一些洞,需要花一些时间才能有效地管理空闲内存。这种算法通常具有较高的内存使用效率(分配需要的内存),但是却需要花费更多时间来对堆进行管理。
另外一种方法称为 buddy memory allocation,是一种更快的内存分配技术,它将内存划分为 2 的幂次方个分区,并使用 best-fit 方法来分配内存请求。当用户释放内存时,就会检查 buddy 块,查看其相邻的内存块是否也已经被释放。如果是的话,将合并内存块以最小化内存碎片。这个算法的时间效率更高,但是由于使用 best-fit 方法的缘故,会产生内存浪费。
本文将着重介绍 Linux 内核的内存管理,尤其是 slab 分配提供的机制。
Linux 所使用的 slab 分配器的基础是 Jeff Bonwick 为 SunOS 操作系统首次引入的一种算法。Jeff 的分配器是围绕对象缓存进行的。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff 发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。例如,如果内存被分配给了一个互斥锁,那么只需在为互斥锁首次分配内存时执行一次互斥锁初始化函数(mutex_init)即可。后续的内存分配不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。
Linux slab 分配器使用了这种思想和其他一些思想来构建一个在空间和时间上都具有高效性的内存分配器。
图 1 给出了 slab 结构的高层组织结构。在最高层是cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
图 1. slab 分配器的主要结构
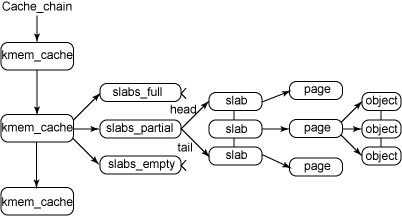
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在 3 种 slab:
slabs_full
完全分配的 slab
slabs_partial
部分分配的 slab
slabs_empty
空 slab,或者没有对象被分配
注意 slabs_empty 列表中的 slab 是进行回收(reaping)的主要备选对象。正是通过此过程,slab 所使用的内存被返回给操作系统供其他用户使用。
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab 分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab 列表之间进行移动。例如,当一个 slab 中的所有对象都被使用完时,就从 slabs_partial 列表中移动到slabs_full 列表中。当一个 slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到 slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中。
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab 分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
现在来看一下能够创建新 slab 缓存、向缓存中增加内存、销毁缓存的应用程序接口(API)以及 slab 中对对象进行分配和释放操作的函数。
第一个步骤是创建 slab 缓存结构,您可以将其静态创建为:
struct struct kmem_cache *my_cachep;
然后其他 slab 缓存函数将使用该引用进行创建、删除、分配等操作。kmem_cache 结构包含了每个中央处理器单元(CPU)的数据、一组可调整的(可以通过 proc 文件系统访问)参数、统计信息和管理 slab 缓存所必须的元素。
内核函数 kmem_cache_create 用来创建一个新缓存。这通常是在内核初始化时执行的,或者在首次加载内核模块时执行。其原型定义如下:
struct kmem_cache *
kmem_cache_create( const char *name, size_t size, size_t align,unsigned long flags;void (*ctor)(void*, struct kmem_cache *, unsigned long),void (*dtor)(void*, struct kmem_cache *, unsigned long));
name 参数定义了缓存名称,proc 文件系统(在 /proc/slabinfo 中)使用它标识这个缓存。 size 参数指定了为这个缓存创建的对象的大小, align 参数定义了每个对象必需的对齐。 flags 参数指定了为缓存启用的选项。这些标志如表 1 所示。
表 1. kmem_cache_create 的部分选项(在 flags 参数中指定)
| 选项 | 说明 |
|---|---|
| SLAB_RED_ZONE | 在对象头、尾插入标志,用来支持对缓冲区溢出的检查。 |
| SLAB_POISON | 使用一种己知模式填充 slab,允许对缓存中的对象进行监视(对象属对象所有,不过可以在外部进行修改)。 |
| SLAB_HWCACHE_ALIGN | 指定缓存对象必须与硬件缓存行对齐。 |
ctor 和 dtor 参数定义了一个可选的对象构造器和析构器。构造器和析构器是用户提供的回调函数。当从缓存中分配新对象时,可以通过构造器进行初始化。
在创建缓存之后, kmem_cache_create 函数会返回对它的引用。注意这个函数并没有向缓存分配任何内存。相反,在试图从缓存(最初为空)分配对象时,refill 操作将内存分配给它。当所有对象都被使用掉时,也可以通过相同的操作向缓存添加内存。
内核函数 kmem_cache_destroy 用来销毁缓存。这个调用是由内核模块在被卸载时执行的。在调用这个函数时,缓存必须为空。
void kmem_cache_destroy( struct kmem_cache *cachep );
要从一个命名的缓存中分配一个对象,可以使用kmem_cache_alloc 函数。调用者提供了从中分配对象的缓存以及一组标志:
| 1 |
|
这个函数从缓存中返回一个对象。注意如果缓存目前为空,那么这个函数就会调用 cache_alloc_refill 向缓存中增加内存。 kmem_cache_alloc 的 flags 选项与 kmalloc 的 flags 选项相同。表 2 给出了标志选项的部分列表。
表 2. kmem_cache_alloc 和 kmalloc 内核函数的标志选项
| 标志 | 说明 |
|---|---|
| GFP_USER | 为用户分配内存(这个调用可能会睡眠)。 |
| GFP_KERNEL | 从内核 RAM 中分配内存(这个调用可能会睡眠)。 |
| GFP_ATOMIC | 使该调用强制处于非睡眠状态(对中断处理程序非常有用)。 |
| GFP_HIGHUSER | 从高端内存中分配内存。 |
内核函数 kmem_cache_zalloc 与 kmem_cache_alloc 类似,只不过它对对象执行 memset 操作,用来在将对象返回调用者之前对其进行清除操作。
要将一个对象释放回 slab,可以使用 kmem_cache_free。调用者提供了缓存引用和要释放的对象。
| 1 |
|
内核中最常用的内存管理函数是 kmalloc 和 kfree 函数。这两个函数的原型如下:
| 1 2 |
|
注意在 kmalloc 中,惟一两个参数是要分配的对象的大小和一组标志(请参看 表 2 中的部分列表)。但是 kmalloc 和kfree 使用了类似于前面定义的函数的 slab 缓存。kmalloc没有为要从中分配对象的某个 slab 缓存命名,而是循环遍历可用缓存来查找可以满足大小限制的缓存。找到之后,就(使用 __kmem_cache_alloc)分配一个对象。要使用 kfree 释放对象,从中分配对象的缓存可以通过调用 virt_to_cache 确定。这个函数会返回一个缓存引用,然后在 __cache_free 调用中使用该引用释放对象。
slab 缓存 API 还提供了其他一些非常有用的函数。kmem_cache_size 函数会返回这个缓存所管理的对象的大小。您也可以通过调用 kmem_cache_name 来检索给定缓存的名称(在创建缓存时定义)。缓存可以通过释放其中的空闲 slab 进行收缩。这可以通过调用 kmem_cache_shrink 实现。注意这个操作(称为回收)是由内核定期自动执行的(通过kswapd)。
| 1 2 3 |
|
下面的代码片断展示了创建新 slab 缓存、从缓存中分配和释放对象然后销毁缓存的过程。首先,必须要定义一个kmem_cache 对象,然后对其进行初始化(请参看清单 1)。这个特定的缓存包含 32 字节的对象,并且是硬件缓存对齐的(由标志参数 SLAB_HWCACHE_ALIGN 定义)。
清单 1. 创建新 slab 缓存
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
使用所分配的 slab 缓存,您现在可以从中分配一个对象了。清单 2 给出了一个从缓存中分配和释放对象的例子。它还展示了两个其他函数的用法。
清单 2. 分配和释放对象
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
最后,清单 3 演示了 slab 缓存的销毁。调用者必须确保在执行销毁操作过程中,不要从缓存中分配对象。
清单 3. 销毁 slab 缓存
| 1 2 3 4 5 6 7 |
|
proc 文件系统提供了一种简单的方法来监视系统中所有活动的 slab 缓存。这个文件称为 /proc/slabinfo,它除了提供一些可以从用户空间访问的可调整参数之外,还提供了有关所有 slab 缓存的详细信息。当前版本的 slabinfo 提供了一个标题,这样输出结果就更具可读性。对于系统中的每个 slab 缓存来说,这个文件提供了对象数量、活动对象数量以及对象大小的信息(除了每个 slab 的对象和页面之外)。另外还提供了一组可调整的参数和 slab 数据。
要调优特定的 slab 缓存,可以简单地向 /proc/slabinfo 文件中以字符串的形式回转 slab 缓存名称和 3 个可调整的参数。下面的例子展示了如何增加 limit 和 batchcount 的值,而保留 shared factor 不变(格式为 “cache name limit batchcount shared factor”):
| 1 |
|
limit 字段表示每个 CPU 可以缓存的对象的最大数量。batchcount 字段是当缓存为空时转换到每个 CPU 缓存中全局缓存对象的最大数量。 shared 参数说明了对称多处理器(Symmetric MultiProcessing,SMP)系统的共享行为。
注意您必须具有超级用户的特权才能在 proc 文件系统中为 slab 缓存调优参数。
对于小型的嵌入式系统来说,存在一个 slab 模拟层,名为 SLOB。这个 slab 的替代品在小型嵌入式 Linux 系统中具有优势,但是即使它保存了 512KB 内存,依然存在碎片和难于扩展的问题。在禁用 CONFIG_SLAB 时,内核会回到这个 SLOB 分配器中。更多信息请参看 参考资料 一节。
slab 缓存分配器的源代码实际上是 Linux 内核中可读性较好的一部分。除了函数调用的间接性之外,源代码也非常直观,总的来说,具有很好的注释。如果您希望了解更多有关 slab 缓存分配器的内容,建议您从源代码开始,因为它是有关这种机制的最新文档。 下面的 参考资料 一节提供了介绍 slab 缓存分配器的参考资料,但是不幸的是就目前的 2.6 实现来说,这些文档都已经过时了。
相关主题
http://wiki.dreamrunner.org/public_html/Embedded-System/kernel/slab-slub-slob.html
http://www.wowotech.net/memory_management/247.html
https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 