本文主要介绍关于linux,安全的知识点,对【linux 堆利用基础知识】和【但不知道从哪入手怎么办】有兴趣的朋友可以看下由【_sky123_】投稿的技术文章,希望该技术和经验能帮到你解决你所遇的相关技术问题。
ptmalloc2 是目前 Linux 标准发行版中使用的堆分配器。
内存分配基本思想 堆管理器负责向操作系统申请内存,然后将其返回给用户程序,但是频繁的系统调用会造成大量的开销。为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。 堆的基本操作 mallocmalloc 函数返回对应大小字节的内存块的指针。此外,该函数还对一些异常情况进行了处理:
当 n=0 时,返回当前系统允许的堆的最小内存块。当 n 为负数时,由于在大多数系统上,size_t 是无符号数(这一点非常重要),所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。 realloc用以扩展 chunk,相邻 chunk 闲置且空间充足则会进行合并,否则会重新分配 chunk。
即通过 realloc 我们可以完成对一个 chunk 的 free,也就是说在特殊情况下 realloc 是可以当作 free 使用的,其中,在size 为 0 的情况下,realloc 函数会调用 free 释放该 chunk。
calloc该函数在分配时会清空 chunk 上的内容,这使得我们无法通过以往的重复存取后通过 chunk 上残留的脏数据的方式泄露信息(例如通过 bins 数组遗留的脏数据泄露 libc 基址等),同时该函数不从 tcache 中拿 chunk,但是 free() 函数默认还是会先往 tcache 里放的,这无疑增加了我们利用的难度。
free可以看出,free 函数会释放由 p 所指向的内存块。这个内存块有可能是通过 malloc 函数得到的,也有可能是通过相关的函数 realloc 得到的。
此外,该函数也同样对异常情况进行了处理:
内存管理函数背后的系统调用主要是 (s)brk 函数以及 mmap, munmap 函数。
在 main arena 中通过 sbrk 扩展 heap,而在 thread arena 中通过 mmap 分配新的 heap。
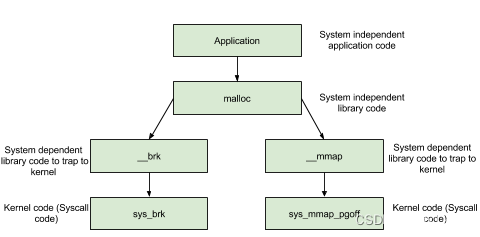
对于堆的操作,操作系统提供了 brk 函数,glibc 库提供了 sbrk 函数,我们可以通过增加 brk 的大小来向操作系统申请内存。
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启 ASLR,两者的具体位置会有所不同
不开启 ASLR 保护时,start_brk 以及 brk 会指向 data/bss 段的结尾。
开启 ASLR 保护时,start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
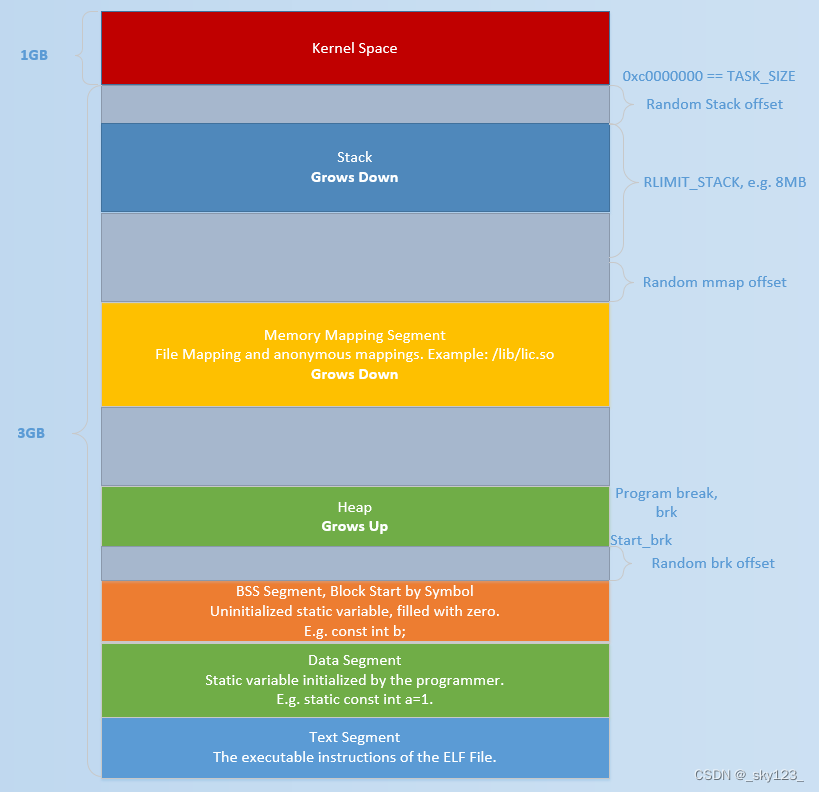
malloc 会使用 mmap 来创建独立的匿名映射段。匿名映射的目的主要是可以申请以 0 填充的内存,并且这块内存仅被调用进程所使用。
堆相关数据结构 malloc_par在ptmalloc中使用malloc_par结构体来记录堆管理器的相关参数,该结构体定义于malloc.c中,如下:
struct malloc_par
{
/* Tunable parameters */
unsigned long trim_threshold;
INTERNAL_SIZE_T top_pad;
INTERNAL_SIZE_T mmap_threshold;
INTERNAL_SIZE_T arena_test;
INTERNAL_SIZE_T arena_max;
/* Memory map support */
int n_mmaps;
int n_mmaps_max;
int max_n_mmaps;
/* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */
int no_dyn_threshold;
/* Statistics */
INTERNAL_SIZE_T mmapped_mem;
/*INTERNAL_SIZE_T sbrked_mem;*/
/*INTERNAL_SIZE_T max_sbrked_mem;*/
INTERNAL_SIZE_T max_mmapped_mem;
INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS */
/* First address handed out by MORECORE/sbrk. */
char *sbrk_base;
};
主要是定义了和 mmap 和 arena 相关的一些参数(如数量上限等),以及 sbrk 的基址
该结构体类型的实例 mp_ 用以记录ptmalloc相关参数,同样定义于 malloc.c 中,如下:
static struct malloc_par mp_ =
{
.top_pad = DEFAULT_TOP_PAD,
.n_mmaps_max = DEFAULT_MMAP_MAX,
.mmap_threshold = DEFAULT_MMAP_THRESHOLD,
.trim_threshold = DEFAULT_TRIM_THRESHOLD,
#define NARENAS_FROM_NCORES(n) ((n) * (sizeof (long) == 4 ? 2 : 8))
.arena_test = NARENAS_FROM_NCORES (1)
};
heap_info 位于一个 heap 块的开头,用以记录通过 mmap 系统调用从 Memory Mapping Segment 处申请到的内存块的信息。定义于 arena.c 中。
/* A heap is a single contiguous memory region holding (coalesceable) malloc_chunks. It is allocated with mmap() and always starts at an address aligned to HEAP_MAX_SIZE. */
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */
/* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
heap_info 结构体的成员如下:
ar_ptr:指向管理该堆块的 arenaprev:该heap_info所链接的上一个 heap_infosize:记录该堆块的大小mprotect_size:记录该堆块中被保护(mprotected)的大小pad:即 padding ,用以在 SIZE_SZ 不正常的情况下进行填充以让内存对齐,正常情况下 pad 所占用空间应为 0 字节 arena大部分情况下对于每个线程而言其都会单独有着一个 arena 实例用以管理属于该线程的堆内存区域。ptmalloc内部的内存池结构是由 malloc_state 结构体进行定义的,即 arena本身便为 malloc_state 的一个实例对象。
malloc_state结构体定义于malloc/malloc.c中,代码如下:
struct malloc_state
{
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
malloc_state 结构体的成员如下:
mutex:mutex 变量即为多线程互斥锁,用以保证线程安全。flags:标志位,用以表示 arena 的一些状态,如:是否有 fastbin 、内存是否连续等。fastbinY:存放 fastbin chunk 的数组。top:指向 Top Chunk 的指针。last_remainder:chunk 切割中的剩余部分。malloc 在分配 chunk 时若是没找到 size 合适的 chunk 而是找到了一个 size 更大的 chunk ,则会从大 chunk 中切割掉一块返回给用户,剩下的那一块便是 last_remainder ,其随后会被放入 unsorted bin 中。bins:存放闲置 chunk 的数组。bins 包括 large bin,small bin 和 unsorted bin 。binmap:记录 bin 是否为空的 bitset 。需要注意的是chunk被取出后若一个bin空了并不会立即被置0,而会在下一次遍历到时重新置位。next:指向下一个 arena 的指针。一个进程内所有的arena串成了一条循环单向链表,malloc_state 中的next指针便是用以指向下一个 arena ,方便后续的遍历 arena 的操作(因为不是所有的线程都有自己独立的 arena )。next_free:指向下一个空闲的arena的指针。与 next 指针类似,只不过指向的是空闲的 arena(即没有被任一线程所占用)。attached_threads:与该 arena 相关联的线程数。该变量用以表示有多少个线程与该arena相关联,这是因为aerna的数量是有限的,并非每一个线程都有机会分配到一个arena,在线程数量较大的情况下会存在着多个线程共用一个arena的情况。system_mem:记录当前 arena 在堆区中所分配到的内存的总大小。max_system_mem:当操作系统予进程以内存时,system_mem 会随之增大,当内存被返还给操作系统时,sysyetm_mem 会随之减小,max_system_mem 变量便是用来记录在这个过程当中 system_mem 的峰值。main_arena 为一个定义于 malloc.c 中的静态的 malloc_state 结构体。
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};
由于其为libc中的静态变量,该arena会被随着libc文件一同加载到Memory Mapping Segment。因此在堆题中通常通过泄露arena的地址以获得 libc 在内存中的基地址。
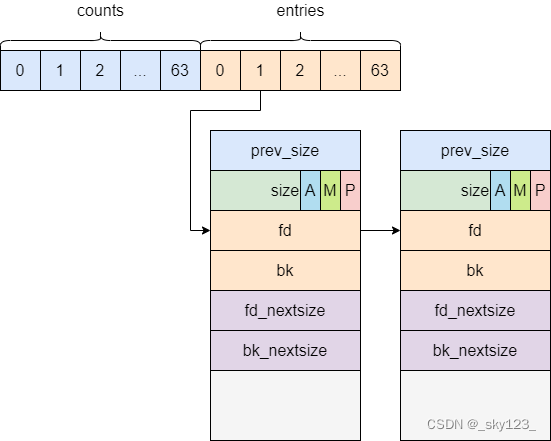
chunk在程序的执行过程中,我们称由 malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构体来表示。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。
malloc_chunk 定义如下:
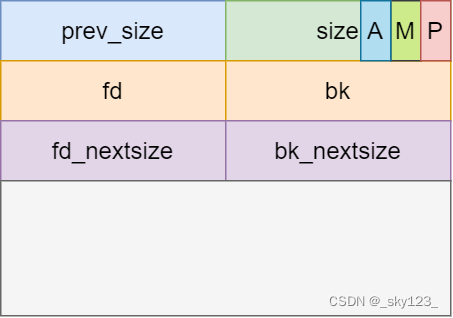
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
每个字段的具体的解释如下:
prev_size:如果物理相邻的前一地址 chunk 是空闲的话,那该字段记录的是前一个 chunk 的大小 (包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个 chunk 的数据。
size:该 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍。该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示为:
fd,bk。 chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
fd 指向下一个(非物理相邻)空闲的 chunkbk 指向上一个(非物理相邻)空闲的 chunk通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。(chunk 的结构如下图所示:
我们曾经说过,用户释放掉的 chunk 不会马上归还给系统,ptmalloc 会统一管理 heap 和 mmap 映射区域中的空闲的 chunk。当用户再一次请求分配内存时,ptmalloc 分配器会试图在空闲的 chunk 中挑选一块合适的给用户。这样可以避免频繁的系统调用,降低内存分配的开销。
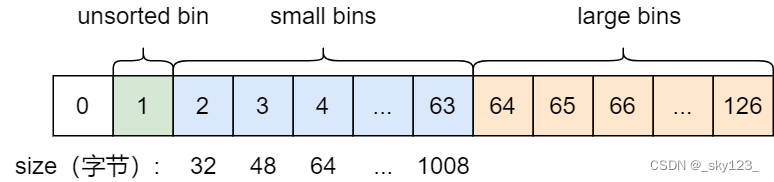
在具体的实现中,ptmalloc 采用分箱式方法对空闲的 chunk 进行管理。首先,它会根据空闲的 chunk 的大小以及使用状态将 chunk 初步分为 4 类:fast bins,small bins,large bins,unsorted bin 。对于 libc2.26 以上版本还有 tcache 。
对于 small bins,large bins,unsorted bin 来说,ptmalloc 将它们维护在一个 bins 数组中。这些 bin 对应的数据结构在 malloc_state 中,如下:
#define NBINS 128
/* Normal bins packed as described above */
mchunkptr bins[ NBINS * 2 - 2 ];
bins 数组实际上可以看做是以 chunk 为单位,只不过采用空间复用策略,因为实际用到的只有 fd 和 bk 。这就解释了为什么 bin 0 不存在。
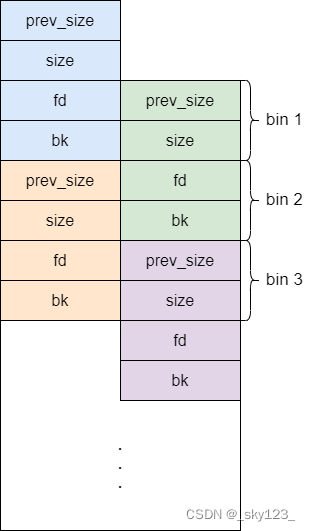
由于是双链表结构 bins 数组每连续两个 chunk 指针维护一个 bin(即 fd 和 bk ),其结构如下图所示(64位)。其中 small bins 中 chunk 大小已给出。large bins 的每个 bin 中的 chunk 大小在一个范围内。由于我求的结果跟 ctfwiki 上有出入,就不标注了。其实关键还是 small bins 和 large bins 的边界值。
统计 large bins 范围:
#include
cnt;
// for (int i = 512, j;; i = j + 8) {
// if (largebin_index_32(i) == 126) {
// cout <
// break;
// }
// for (j = i; largebin_index_32(j + 8) == largebin_index_32(i); j += 8);
// cout <
// cnt[j - i + 8]++;
// }
// for (auto[x, c]:cnt) {
// cout <
// }
return 0;
}
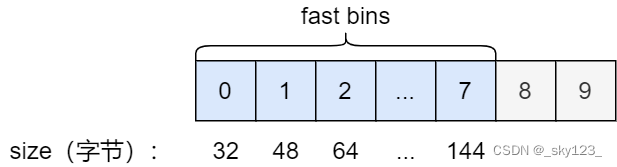
对于 fast bin ,在 malloc_state 又单独定义了一个 fastbinsY 的结构维护。
typedef struct malloc_chunk *mfastbinptr;
/* This is in malloc_state. /* Fastbins */
mfastbinptr fastbinsY[ NFASTBINS ];
*/
由于 fast bin 为单链表结构,因此数组中一个指针就可以维护一个 bin 。结构如图所示:
为了避免大部分时间花在了合并、分割以及中间检查的过程中影响效率,因此 ptmalloc 中专门设计了 fast bin。
fast bin 采用单链表形式,结构如下图所示:
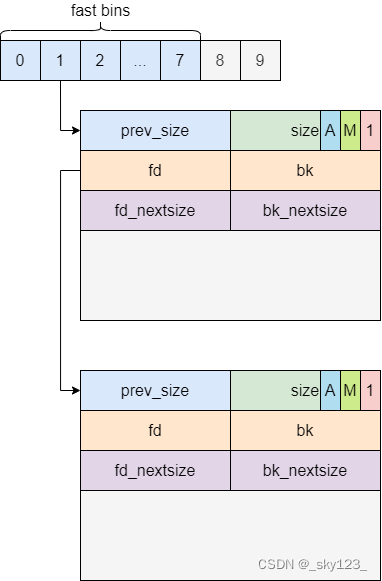
安全检查:
size:在 malloc() 函数分配 fastbin size 范围的 chunk 时,若是对应的 fastbin 中有空闲 chunk,在取出前会检查其 size 域与对应下标是否一致,不会检查标志位,若否便会触发abortdouble free:在 free() 函数中会对fastbin链表的头结点进行检查,若将要被放入 fastbin 中的 chunk 与对应下标的链表的头结点为同一chunk,则会触发abortSafe linking 机制(only glibc2.32 and up):自 glibc 2.32 起引入了 safe-linking 机制,其核心思想是在链表上的 chunk 中并不直接存放其所连接的下一个 chunk 的地址,而是存放下一个 chunk 的地址与【fd指针自身地址右移 12位】所异或得的值,使得攻击者在得知该 chunk 的地址之前无法直接利用其构造任意地址写#define PROTECT_PTR(pos, ptr) \ ((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
small bin 采用双向链表,结构如下图所示。
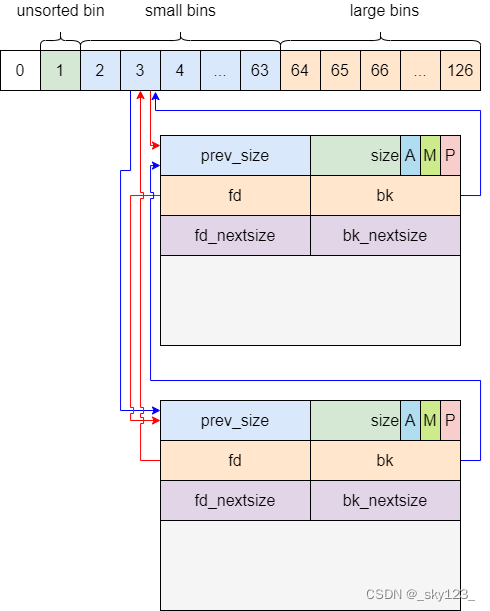
large bins 中一共包括 63 个 bin,每个 bin 中的 chunk 的大小不一致,而是处于一定区间范围内。large bin 的结构如下:
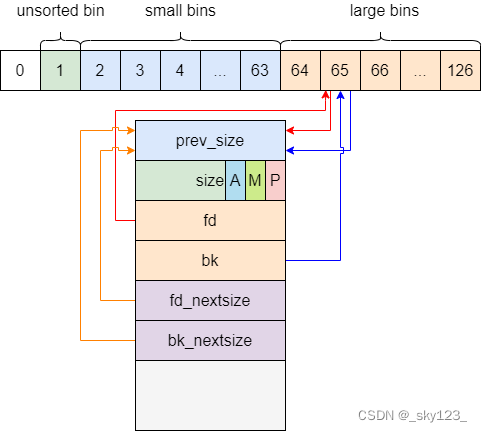
关于 fd_nextsize 和 bk_nextsize 的机制,这里以 fd_nextsize 为例:
fd_nextsize 和 bk_nextsize 与 bins 数组没有连接关系(这就解释了为什么 bins 上 没有体现 fd_nextsize 和 bk_nextsize 结构)。
large bin 里的 chunk 在 fd 指针指向的方向上按照 chunk 大小降序排序。
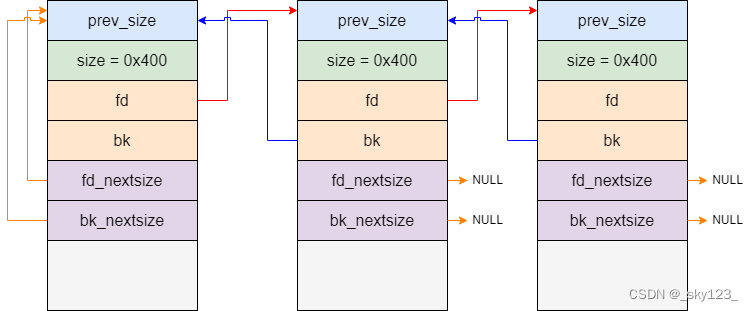
当 large bin 里有一个 chunk 时, fd_nextsize 和 bk_nextsize 指向自己(如上面 large bin 的结构图所示)。
当 large bin 里同一大小的 chunk 有多个时,只有相同大小 chunk 中的第一个的 fd_nextsize 和 bk_nextsize 指针有效,其余的 chunk 的 fd_nextsize 和 bk_nextsize 设为 NULL 。
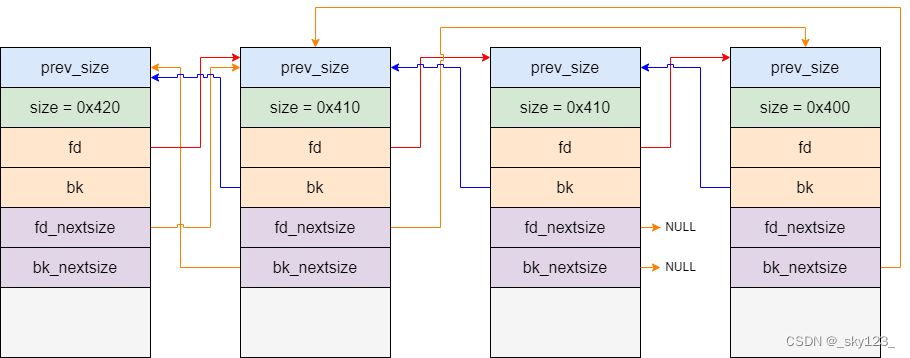
large bin 中有多个不同大小的 chunk 时 fd_nextsize 连接比它小的第一个 chunk,bk_nextsize 就是把 fd_nextsize 反过来连到对应结构上。
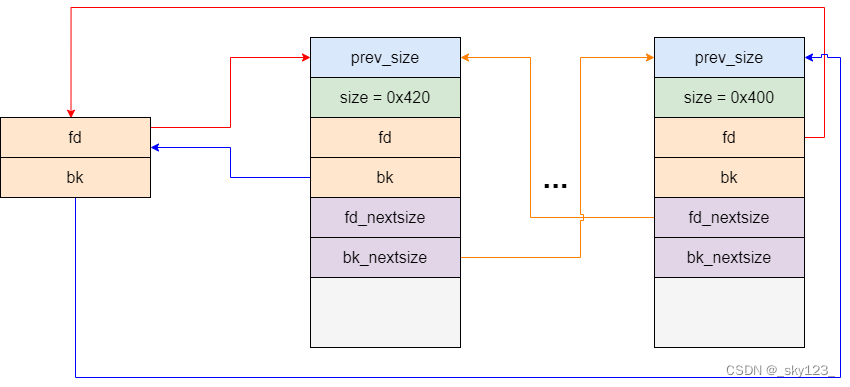
large bin 最小的一组 chunk 中的第一个 chunk 的 fd_nextsize 连接的是最大的 chunk,最大的 chunk 的 bk_nextsize 相反。
unsorted bin 可以视为空闲 chunk 回归其所属 bin 之前的缓冲区。像 small bin 一样采用双向链表维护。chunk 大小乱序。
Top Chunk程序第一次进行 malloc 的时候,heap 会被分为两块,一块给用户,剩下的那块就是 top chunk。其实,所谓的 top chunk 就是处于当前堆的物理地址最高的 chunk。这个 chunk 不属于任何一个 bin,它的作用在于当所有的 bin 都无法满足用户请求的大小时,如果其大小不小于指定的大小,就进行分配,并将剩下的部分作为新的 top chunk。否则,就对 heap 进行扩展后再进行分配。在 main arena 中通过 sbrk 扩展 heap,而在 thread arena 中通过 mmap 分配新的 heap。
需要注意的是,top chunk 的 prev_inuse 比特位始终为 1,否则其前面的 chunk 就会被合并到 top chunk 中。
在用户使用 malloc 请求分配内存时,ptmalloc2 找到的 chunk 可能并不和申请的内存大小一致,这时候就将分割之后的剩余部分称之为 last remainder chunk ,unsort bin 也会存这一块。top chunk 分割剩下的部分不会作为 last remainder.
tcachetcache 是 glibc 2.26 (ubuntu 17.10) 之后引入的一种技术,目的是提升堆管理的性能,与 fast bin 类似。
tcache 引入了两个新的结构体,tcache_entry 和 tcache_perthread_struct。
tcache_entry 定义如下:
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
tcache_entry 用于链接空闲的 chunk 结构体,其中的 next 指针指向下一个大小相同的 chunk。
需要注意的是这里的 next 指向 chunk 的 user data,而 fastbin 的 fd 指向 chunk 开头的地址。
而且,tcache_entry 会复用空闲 chunk 的 user data 部分。
tcache_perthread_struct 定义如下:
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL;
对应结构如下
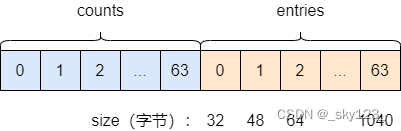
每个 thread 都会维护一个 tcache_perthread_struct,它是整个 tcache 的管理结构,一共有 TCACHE_MAX_BINS 个计数器和 TCACHE_MAX_BINS项 tcache_entry,其中
tcache_entry 用单向链表的方式链接了相同大小的处于空闲状态(free 后)的 chunk,这一点上和 fastbin 很像。
counts 记录了 tcache_entry 链上空闲 chunk 的数目,每条链上最多可以有 7 个 chunk。
结构如下:
仅简要介绍大致过程,具体细节最好还是查看 libc 源码。
malloc 首先在 _libc_malloc 函数中先判断 __malloc_hook 函数指针是否为空,如果不为空则调用 __malloc_hook 函数。如果存在 tcache 且有相应大小的 chunk 则将其从 tcache 中取出并返回结果。调用 _int_malloc 函数。 首先把申请的内存的字节数转化为 chunk 的大小。如果 arena 未初始化 ,则调用 sysmalloc 向系统申请内存,然后将获取的 chunk 返回。如果申请的 chunk 大小不超过 fast bin 的最大值,则尝试从对应的 fast bin 的头部获取 chunk 。在获取到 chunk 后,如果对应的 fast bin 还有 chunk 并且大小在 tcache 范围就将它们依次从头结点取出放到 tcache 中,直到把 tcache 放满。最后将申请到的 chunk 返回。如果申请的 chunk 在 small bin 大小范围则进行与 fast bin 一样的操作,只不过这次取 chunk 是依次从链表尾部取。调用 malloc_consolidate 函数将 fast bin 中的 chunk 合并后放入 unsorted bin 。循环进行如下操作: 循环取 unsorted bin 最后一个 chunk 。 如果用户的请求为 small bin chunk,那么我们首先考虑 last remainder,如果当前 chunk 是 last remainder ,且 last remainder 是 unsorted bin 中的唯一一个 chunk , 并且 last remainder 的大小分割后还可以作为一个 chunk,则从 last reminder 中切下一块内存返回。如果 chunk 的大小恰好等于申请的 chunk 大小,则如果该内存大小在 tcache 范围且 tcache 没有满,则先将其放入 tcache,之后会考虑从 tcache 中找 chunk 。否则直接将找到的 chunk 返回。根据 chunk 的大小将其放入 small bin 或 large bin 中。对于 small bin 直接从链表头部加入;对于 large bin,首先特判加入链表尾部的情况,如果不在链表尾部则从头部遍历找位置,如果 large bin 中有与加入的 chunk 大小相同的 chunk ,则加到第一个相等 chunk 后面,否则加到合适位置后还需要更新 nextsize 指针。尝试从 tcache 找 chunk 。如果循环超过 10000 次则跳出循环。 尝试从 tcache 找 chunk 。如果申请 chunk 大小不在 small bin 范围,则从后往前遍历对应 large bin ,找到第一个不小于申请 chunk 大小的 chunk 。为了 unlink 时避免修改 nextsize 的操作,如果存在多个合适的 chunk 则选择第二个 chunk 。如果选取的 chunk 比申请的 chunk 大不少于 MINSIZE ,则需要将多出来的部分切出来作为 remainder ,并将其加入 unsorted bin 头部。然后将获取的 chunk 返回。找一个 chunk 范围比申请 chunk 大的非空 bin 里面找最后一个 chunk ,这个过程用 binmap 优化,同时也可以更新 binmap 的状态。这个 chunk 上切下所需的 chunk ,剩余部分放入 unsorted bin 头部。然后将获取的 chunk 返回。如果 top chunk 切下所需 chunk 后剩余部分还是不小于 MINSIZE 则从top chunk 上切下所需 chunk 返回。如果 fast bins 还有 chunk 则调用 malloc_consolidate 合并 fast bin 中的 chunk 并放入 unsorted bin 中,然后继续循环。最后 sysmalloc 系统调用向操作系统申请内存分配 chunk 。 如果 arena 没有初始化或者申请的内存大于 mp_.mmap_threshold,并且 mmap 的次数小于最大值,则使用 mmap 申请内存。然后检查一下是否 16 字节对齐然后更新 mmap 次数和 mmap 申请过的最大内存大小后就将 chunk 返回。如果 arena 没有初始化就返回 0对之前的 top chunk 进行检查,如果是 dummy top 的话,因为是用 unsorted bin 表示的,因此 top chunk 的大小需要是 0 。否则堆的大小应该不小于 MINSIZE,并且前一个堆块应该处于使用中,并且堆的结束地址应该是页对齐的,由于页对齐的大小默认是 0x1000,所以低 12 个比特需要为 0。除此之外,top chunk 大小必须比申请 chunk 大小加上 MINSIZE 要小。如果 arena 不是 main arena 尝试将 top chunk 所在的 heap 扩展大小,如果成功则更新 arena 记录的内存总大小 system_mem 和 top chunk 大小。尝试申请一个新的 heap 。设置新的 heap 以及 arena 的参数并且将原来的 top chunk 先从尾部切下 2 个 0x10 大小的 chunk ,剩余部分如果不小于 MINSIZE 则将其释放掉。否则,如果前面没有执行到 mmap 申请 chunk 的分支就尝试执行。 如果 arena 是 main arena 计算需要获取的内存大小。需要获取的内存大小等于申请的 chunk 大小加上 0x20000 和 MINSIZE 。如果堆空间连续,则可以再减去原来内存的大小。然后将需要获取的内存大小与页大小对齐。sbrk 扩展内存如果成功则会尝试调用一个 hook 函数,否则 mmap 申请内存,然后 brk 移到申请的内存处并设置堆不连续参数。如果成功获取到内存,则更新 arena 记录的内存总大小 system_mem 和 sbrk_base。之后对一系列的情况进行处理,在这期间,之前的 top chunk 会被从尾部切下两个 0x10 大小的chunk,剩余部分如果不小于 MINSIZE 则将其释放掉。 最后从新获取的 top chunk 上切下所需的 chunk 并返回。 free 首先在 __libc_free 函数中先判断 __free_hook 函数指针是否为空,如果不为空则调用 __free_hook 函数。如果 chunk 是 mmap 申请的,则调用 munmap_chunk 释放。调用 _int_free 函数 如果释放的 chunk 大小在 tcache 范围且对应的 tcache 没有满,则直接放到 tcache 中然后返回。如果在 fast bin 范围则加入到 fast bin 头部并返回。如果不是 mmap 申请的内存 如果与释放 chunk 相邻的前一个 chunk 是空闲的,则将前一个 chunk 从 bin 中取出和释放 chunk 合并。如果与释放 chunk 相邻的后一个 chunk 不是 top chunk 如果与释放 chunk 相邻的后一个 chunk 是空闲的,则将其从 bin 中取出和释放 chunk 合并,否则将其 PREV_INUSE 位置 0将释放的 chunk 加入到 unsorted bin 头部。 否则将其合并到 top chunk如果合并后的 chunk 的大小大于FASTBIN_CONSOLIDATION_THRESHOLD 就向系统返还内存 否则调用 munmap_chunk 释放 chunk本文《linux 堆利用基础知识》版权归_sky123_所有,引用linux 堆利用基础知识需遵循CC 4.0 BY-SA版权协议。


![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有