常用的全局搜索引擎有很多,有兴趣的童靴戳这里常见的Java全局搜索引擎,目前更常用的除了solr,还有就是我们今天要说的分布式搜索引擎 Elasticsearch(简称ES)
spring boot整合ES的方式目前常见的有两种,一种是使用spring data elasticsearch,一种就是使用elasticsearchTemplate进行整合。如对搜索没有高亮需求,用前者即可,如有高亮需求,则必须使用后者。
(ps:当然了,可能还有其它好用的方式是我不清楚的,若有的话承蒙不弃,请留言告知,thx。)
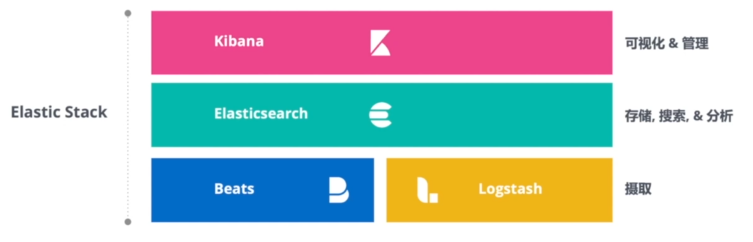
事实上Elasticsearch只是我们常讲的ELK技术栈中的其中一项,emm,现在最新的叫法为Elastic Stack,即在ELK的基础上再加上用于数据收集的Beats。ELK,即:
1)Elasticsearch(简称ES):用于深度搜索和数据分析,它是基于Apache Lucene的分布式开源搜索引擎,无须预先定义数据结构就能动态地对数据进行索引;
2)Logstash:用于日志集中管理,包括从多台服务器上传输和转发日志,并对日志进行丰富和解析,是一个数据管道,提供了大量插件来支持数据的输入和输出处理;
3)Kibana:提供了强大而美观的数据可视化,Kibana完全使用HTML和Javascript编写,它利用Elasticsearch
的RESTful API来实现其强大的搜索能力,将结果显示位各种震撼的图形提供给最终的用户。
ps:该篇文章只展示如何实现高亮及权重分页搜索,其它前置操作如索引创建/删除、数据保存删除等由于相关文章较多就不再赘述,可参考SpringBoot整合Elasticsearch
Here we go…
在开始整合之前你需得先把需要用到的东西下载准备好,下面是常用插件的官方下载地址:
ps:如果只是想实现搜索效果的话你只需下载ES。至于分词器,可以使你的搜索效果更加友好。安装基本上都是开箱即用,如有不清楚的百度即可。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.2.RELEASE
com.yby.es
181-elasticsearch
0.0.1-SNAPSHOT
war
181-elasticsearch
181 project for global search
1.8
org.springframework.boot
spring-boot-starter-tomcat
provided
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
test
mysql
mysql-connector-java
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.2
org.springframework.boot
spring-boot-starter-data-elasticsearch
src/main/java
**/*.xml
src/main/resources
**/*.yml
**/*.properties
org.springframework.boot
spring-boot-maven-plugin
## tomcat配置 - start
# 指定服务端口
server.port=9999
## tomcat配置 - end
# 禁止对外提供Spring MBeans
# spring.jmx.enabled=false
## 数据库配置 - start
#spring.datasource.url=jdbc:mysql://localhost:3306/springboot-test?serverTimezOne=GMT%2B8
spring.datasource.url=jdbc:mysql://192.168.5.58:3306/181_realestate?serverTimezOne=GMT%2B8
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
## 数据库配置 - end
## myBatis - start
# 打印SQL语句
mybatis.configuration.log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
## myBatis - end
## ElasticSearch - start
#开启 Elasticsearch 仓库(默认值:true)
spring.data.elasticsearch.repositories.enabled=true
#默认 9300 是 Java 客户端的端口。9200 是支持 Restful HTTP 的接口
# spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
spring.data.elasticsearch.cluster-nodes=192.168.5.58:9300
#集群名(默认值: elasticsearch)
spring.data.elasticsearch.cluster-name=realestate
#集群节点地址列表,用逗号分隔。如果没有指定,就启动一个客户端节点
#spring.data.elasticsearch.propertie 用来配置客户端的额外属性
#存储索引的位置
spring.data.elasticsearch.properties.path.home=/data/project/target/elastic
#连接超时的时间
spring.data.elasticsearch.properties.transport.tcp.connect_timeout=120s
## ElasticSearch - end
## log配置 - start
logging.path=/data/tomcat_log/181-elasticsearch/181-elasticsearch_log_error.log
logging.level.com.favorites=DEBUG
logging.level.org.springframework.web=INFO
logging.level.org.hibernate=ERROR
## log配置 - end
注:Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document:作用在类,标记实体类为文档对象,一般有两个属性
@Id:作用在成员变量,标记一个字段作为id主键
@Field:作用在成员变量,标记为文档的字段,并指定字段映射属性:
type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
index:是否索引,布尔类型,默认是true
store:是否存储,布尔类型,默认是false
analyzer:分词器名称,这里的ik_max_word即使用ik分词器
package com.yby.es.po;
import java.io.Serializable;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import com.yby.es.po.constant.EsConstant;
/**
* 游记
*/
@Document(indexName = EsConstant.INDEX_NAME.TRAVEL, type = "doc")
public class Travel extends BaseEntity implements Serializable {
private static final long serialVersiOnUID= -1838668690328733289L;
/**
* 关键词
*/
@Field(type = FieldType.Keyword)
private String keyword;
/**
* 途经城市
*/
@Field(type = FieldType.Keyword)
private String passCity;
public Travel() {
super();
}
public String getKeyword() {
return keyword;
}
public String getPassCity() {
return passCity;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
public void setPassCity(String passCity) {
this.passCity = passCity;
}
}
package com.yby.es.po;
import java.io.Serializable;
import java.util.Date;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* 基础实体
*
* @author lwx
* @date 2019/02/28
*/
public class BaseEntity implements Serializable {
private static final long serialVersiOnUID= 5695568297523302402L;
/**
* ID
*/
@Id
private Long id;
/**
* 类型
*/
@Field(type = FieldType.Keyword)
private String type;
/**
* 状态
*/
@Field(type = FieldType.Keyword)
private String status;
/**
* 标题
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;
/**
* 内容
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
/**
* 忽略检索内容
*/
private String ignoreContent;
/**
* 描述
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String description;
/**
* 创建时间
*/
@Field(type = FieldType.Keyword)
private Date createTime;
/**
* 更新时间
*/
@Field(type = FieldType.Keyword)
private Date updateTime;
public BaseEntity() {
super();
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getStatus() {
return status;
}
public String getTitle() {
return title;
}
public String getContent() {
return content;
}
public String getIgnoreContent() {
return ignoreContent;
}
public String getDescription() {
return description;
}
public Date getCreateTime() {
return createTime;
}
public Date getUpdateTime() {
return updateTime;
}
public void setId(Long id) {
this.id = id;
}
public void setType(String type) {
this.type = type;
}
public void setStatus(String status) {
this.status = status;
}
public void setTitle(String title) {
this.title = title;
}
public void setContent(String content) {
this.cOntent= content;
}
public void setIgnoreContent(String ignoreContent) {
this.ignoreCOntent= ignoreContent;
}
public void setDescription(String description) {
this.description = description;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public void setUpdateTime(Date updateTime) {
this.updateTime = updateTime;
}
}
package com.yby.es.service.impl;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder.Field;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
/**
* 游记
*/
@Override
public Page searchTravel(String keyword, Integer pageNumber, Integer pageSize) {
// 页码
if (pageNumber == null || pageNumber <0) {
pageNumber = 0;
}
// 页数
if (pageSize == null || pageSize <1) {
pageSize = 10;
}
Page page = null;
try {
// 构建查询
NativeSearchQueryBuilder searchQuery = new NativeSearchQueryBuilder();
// 多索引查询
searchQuery.withIndices(EsConstant.INDEX_NAME.TRAVEL);
// 组合查询,boost即为权重,数值越大,权重越大
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.multiMatchQuery(keyword, "title").boost(3))
.should(QueryBuilders.multiMatchQuery(keyword, "passCity", "description").boost(2))
.should(QueryBuilders.multiMatchQuery(keyword, "content", "keyword").boost(1));
searchQuery.withQuery(queryBuilder);
// 高亮设置
List highlightFields = new ArrayList();
highlightFields.add("title");
highlightFields.add("passCity");
highlightFields.add("description");
highlightFields.add("content");
highlightFields.add("keyword");
Field[] fields = new Field[highlightFields.size()];
for (int x = 0; x AggregatedPage mapResults(SearchResponse response, Class clazz, Pageable pageable) {
// 获取高亮搜索数据
List list = new ArrayList();
SearchHits hits = response.getHits();
for (SearchHit searchHit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
Travel data = new Travel();
// 公共字段
data.setId(new Double(searchHit.getId()).longValue());
data.setType(String.valueOf(searchHit.getSourceAsMap().get("type")));
data.setStatus(String.valueOf(searchHit.getSourceAsMap().get("status")));
data.setTitle(String.valueOf(searchHit.getSourceAsMap().get("title")));
data.setContent(String.valueOf(searchHit.getSourceAsMap().get("content")));
data.setIgnoreContent(String.valueOf(searchHit.getSourceAsMap().get("ignoreContent")));
data.setDescription(String.valueOf(searchHit.getSourceAsMap().get("description")));
Object createTime = searchHit.getSourceAsMap().get("createTime");
Object updateTime = searchHit.getSourceAsMap().get("updateTime");
if (createTime != null) {
data.setCreateTime(new Date(Long.valueOf(createTime.toString())));
}
if (updateTime != null) {
data.setUpdateTime(new Date(Long.valueOf(updateTime.toString())));
}
// 个性字段
data.setKeyword(String.valueOf(searchHit.getSourceAsMap().get("keyword")));
data.setPassCity(String.valueOf(searchHit.getSourceAsMap().get("passCity")));
// 反射调用set方法将高亮内容设置进去
try {
for (String field : highlightFields) {
HighlightField highlightField = searchHit.getHighlightFields().get(field);
if (highlightField != null) {
String setMethodName = parSetName(field);
Class poemClazz = data.getClass();
Method setMethod = poemClazz.getMethod(setMethodName, String.class);
String highlightStr = highlightField.fragments()[0].toString();
// 截取字符串
if ("content".equals(field) && highlightStr.length() > 50) {
highlightStr = StringUtil.truncated(highlightStr,
EsConstant.HIGH_LIGHT_START_TAG, EsConstant.HIGH_LIGHT_END_TAG);
}
setMethod.invoke(data, highlightStr);
}
}
} catch (Exception e) {
e.printStackTrace();
}
list.add(data);
}
if (list.size() > 0) {
AggregatedPage result = new AggregatedPageImpl((List) list, pageable,
response.getHits().getTotalHits());
return result;
}
return null;
}
});
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
package com.yby.es.po.constant;
public interface EsConstant {
/**
* 高亮显示 - 开始标签
*/
String HIGH_LIGHT_START_TAG = "";
/**
* 高亮显示 - 结束标签
*/
String HIGH_LIGHT_END_TAG = "";
/**
* 索引名称
*/
class INDEX_NAME {
/**
* 游记
*/
public static final String TRAVEL = "travel";
}
}
当发现搜索返回结果中出现即表示高亮搜索成功,如下:
实际开发中,我们需要将自己的数据库导入以及同步到ES,数据同步的方式多种多样,这里展示其中两种:
注:logstash具体部署这里不展开讲,不清楚的搜索下即可。
以mysql为例,jdbc.conf配置如下:
input {
stdin {}
jdbc {
# type => "activity"
add_field => { "[@metadata][type]" => "activity" }
jdbc_connection_string => "jdbc:mysql://192.168.5.58:3306/181_realestate?characterEncoding=UTF-8&autoRecOnnect=true"
jdbc_user => "root"
jdbc_password => "root"
# mysql依赖包路径;
jdbc_driver_library => "mysql/mysql-connector-java-8.0.13.jar"
# mysql驱动
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_cOnnection=> "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启);
# jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
# jdbc_page_size => "10000"
# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;
# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;
# statement => "SELECT KeyId,TradeTime,OrderUserName,ModifyTime FROM `DetailTab` WHERE ModifyTime>= :sql_last_value order by ModifyTime asc"
statement_filepath => "mysql/realestate/sql/activity.sql"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "id"
# Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => numeric
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql/realestate/last_id/activity.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
# 每天凌晨3点
# schedule => "* * * * *"
schedule => "0 3 * * *"
}
jdbc {
# type => "travel"
add_field => { "[@metadata][type]" => "travel" }
jdbc_connection_string => "jdbc:mysql://192.168.5.58:3306/181_realestate?characterEncoding=UTF-8&autoRecOnnect=true"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "mysql/mysql-connector-java-8.0.13.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
connection_retry_attempts => "3"
jdbc_validate_cOnnection=> "true"
jdbc_validation_timeout => "3600"
# jdbc_paging_enabled => "true"
# jdbc_page_size => "10000"
statement_filepath => "mysql/realestate/sql/travel.sql"
lowercase_column_names => false
sql_log_level => warn
record_last_run => true
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "id"
# 跟踪数据类型: numeric,timestamp,Default value is "numeric"
tracking_column_type => numeric
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql/realestate/last_id/travel.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
# 每天凌晨3点
# schedule => "* * * * *"
schedule => "0 3 * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
# output模块的type需和jdbc模块的type一致
# if [type] == "activity" {
if [@metadata][type] == "activity" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
# hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
hosts => ["127.0.0.1:9200"]
# 索引名字,必须小写
index => "activity"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{id}"
}
}
if [@metadata][type] == "travel" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "travel"
document_id => "%{id}"
}
}
stdout {
codec => json_lines
}
}
注:至于需要同步单独的某行数据的可以以提供接口的方式进行同步,此处不展开
package com.yby.es.task;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import com.yby.es.po.Travel;
/**
*
* 数据导入定时任务
*
*
* @author lwx
*/
@Component
// 开启定时任务
@EnableScheduling
// 开启多线程
@EnableAsync
public class ImportTask {
protected Log logger = LogFactory.getLog(this.getClass());
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private TravelEsRepository travelEsRepository;
@Autowired
private TravelMapper travelMapper;
/**
* 游记
*/
@Async
@Scheduled(cron = "0 16 3 ? * *") // 每天 03:16
public void importTravel() throws InterruptedException {
logger.info("【信息】执行定时任务...");
logger.info("【信息】正在清除游记数据...");
try {
boolean delete = elasticsearchTemplate.deleteIndex(Travel.class);
if (delete) {
logger.info("【信息】游记数据清除完毕,正在导入游记数据...");
Iterable data = travelEsRepository.saveAll(travelMapper.list());
if (data != null) {
logger.info("【success】游记数据导入完毕!");
}
}
} catch (Exception e) {
logger.debug("【error】游记数据导入失败!");
e.printStackTrace();
}
}
}
1、index、type的初衷:
之前es将index、type类比于关系型数据库(例如mysql)中database、table,这么考虑的目的是“方便管理数据之间的关系”。
2、为什么现在要移除type?
2.1 在关系型数据库中table是独立的(独立存储),但es中同一个index中不同type是存储在同一个索引中的(lucene的索引文件),因此不同type中相同名字的字段的定义(mapping)必须一致。
2.2 不同类型的“记录”存储在同一个index中,会影响lucene的压缩性能。
3.1 一个index只存储一种类型的“记录”
这种方案的优点:
a)lucene索引中数据比较整齐(相对于稀疏),利于lucene进行压缩。
b)文本相关性打分更加精确(tf、idf,考虑idf中命中文档总数)
3.2 用一个字段来存储type
如果有很多规模比较小的数据表需要建立索引,可以考虑放到同一个index中,每条记录添加一个type字段进行区分。
这种方案的优点:
a)es集群对分片数量有限制,这种方案可以减少index的数量。
之前一个index上有多个type,如何迁移到3.1、3.2方案?
4.1 先针对实际情况创建新的index,[3.1方案]有多少个type就需要创建多少个新的index,[3.2方案]只需要创建一个新的index。
4.2 调用_reindex将之前index上的数据同步到新的索引上。
此处参考:https://www.cnblogs.com/huangfox/p/9460361.html
必须小写,如果出现大写的名称,将报如下异常:
Caused by: org.elasticsearch.hadoop.EsHadoopIllegalArgumentException: Cannot determine write shards for [CC-2017.01.24/compliance]; likely its format is incorrect (maybe it contains illegal characters?)
at org.elasticsearch.hadoop.util.Assert.isTrue(Assert.java:50)
at org.elasticsearch.hadoop.rest.RestService.initSingleIndex(RestService.java:439)
at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:400)
at org.elasticsearch.spark.rdd.EsRDDWriter.write(EsRDDWriter.scala:40)
at org.elasticsearch.spark.rdd.EsSpark$$anonfun$saveToEs$1.apply(EsSpark.scala:67)
at org.elasticsearch.spark.rdd.EsSpark$$anonfun$saveToEs$1.apply(EsSpark.scala:67)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213
The end.








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有