Evaluation methods for unsupervised word embeddingsTable of Contents- 1. 背景及问题描述
- 2. 已有的解决方案
- 3. 提出的解决方案
- 4. 词频对词向量的影响
论文作者来源一句话概述链接源码数据词向量评估方法CornellACL 2015 https://www.aclweb.org/anthology/D15-1036.pdf
Note
本文是对词向量评估的方法综述:
- 内在评估方法,直接评估词语之间的相似性
- 外在评估方法,通过下游任务的表现来间接评估
得出两个结论:
- 不同下游任务,不同的词向量构造方法表现有差异。一种方法不会完美适用于所有下游任务。(这个在今天已经是常识)
- 词向量中蕴含词频信息,是词向量的一个缺陷。(数据驱动的弊端,对于低频词表现差)
1 背景及问题描述
词向量是在大规模语料上训练出来的中间产物。本文是对如何评估word-embeding的质量的一个综述。
2 已有的解决方案
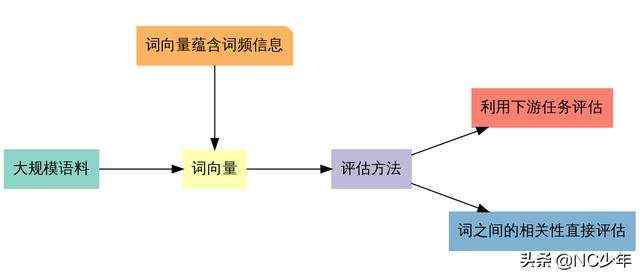
词向量提供语法、语义信息。目前评估词向量的方法可以分为两类:
- 内在(Intrinsic):直接评估词之间的语法、语义关系。相关性: 对两个词之间的相关性进行人工评分。两个词之间的cos相似度作为基于词向量的评分。通过比较cos相似度和人工评分的相关性,来评估。类比analogy: vec(中国)-vec(北京)=vec(法国)-vec(巴黎)分类:对词打上类别标签,通过词向量来聚类,评判聚类好坏词法:确定一个名词是主语还是宾语
- 外在(Extrinsic):将训练好的词向量作为下游任务的输入特征,通过下游任务表现来评估词向量的质量高低。比如NER、情感分析等下游任务。
3 提出的解决方案
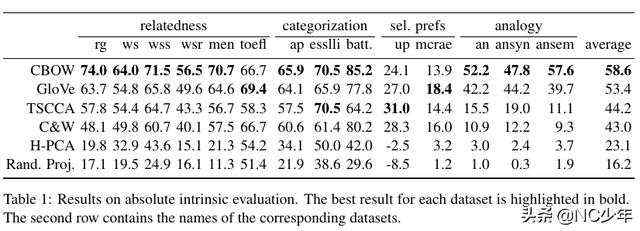
通过亚马逊劳务众包平台(Amazon MechanicalTurk)直接评估不同词向量的质量高低。
直接人工评估相关性
- 精心人为设计100个query词(考虑了词频、词性、抽象/具体)
- 通过6种不同构造词向量的方法,将query词最相似的前k个候选词
- 让众包人员选出最相似的一个词
如果某种方法选出的候选词和人工评估的吻合度越高,代表效果越好。
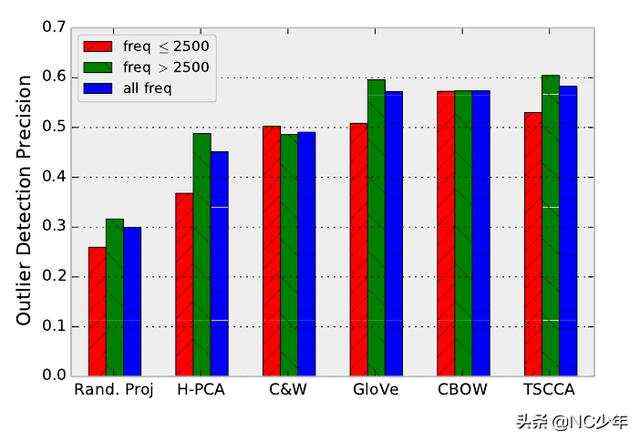
一致性(离群点检测)
通过词向量构造数据集:
- 自动找出query word(a)两个最相似的词语b和c,
- 和一个不相关的词语,作为离群点
- 让众包人员从四个词语中,去找到不相关的那个词语
众包人员找到离群点的Precision作为评估指标。
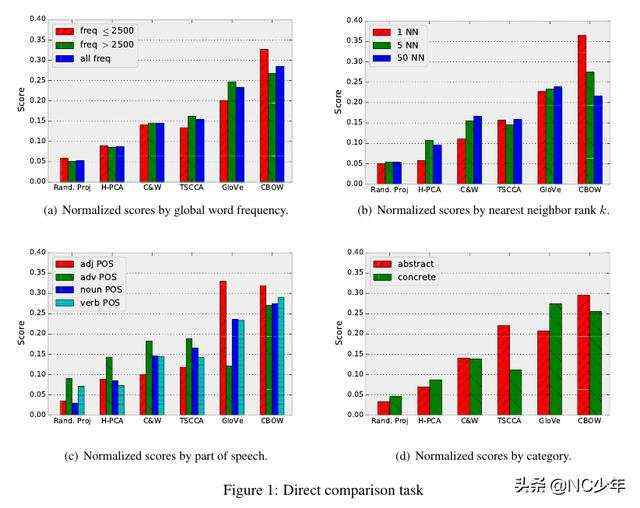
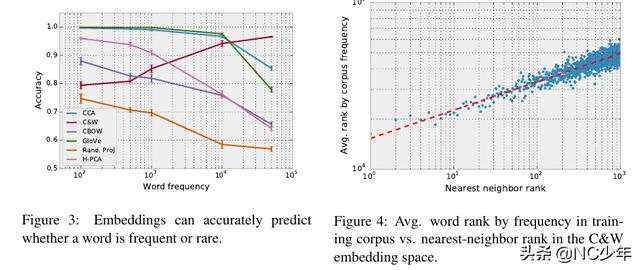
4 词频对词向量的影响
拿词向量作为特征,通过LR来预测一个词是否高频词。对于各种方法,都能比较准确地进行分类。得出结论:词向量蕴含了词频的信息。
词向量的相似度和词频比较强的相关性。
Note
理论而言,考虑两个词的相关性,和词频没有任何关系。(不能说一个词越常见,就和query word越相似)
但词向量是基于大规模语料训练出来的,数据驱动,数据中高频词和低频词对词向量是有影响的。本文通过词频分类、相关性分析,指出了词向量的一个缺陷。










 京公网安备 11010802041100号
京公网安备 11010802041100号