作者:菠萝97 | 来源:互联网 | 2024-12-12 20:02
消息的物理存储结构
在Kafka中,每条消息在日志文件(log)中都有详细的存储格式,包括多个关键字段,这些字段共同决定了消息的结构和功能。
| 字段 | 描述 |
|---|
| 8字节偏移量(Offset) | 每个消息在分区内的唯一标识符,用于确定消息的位置。 |
| 4字节消息大小 | 消息体的总大小。 |
| 4字节CRC32校验码 | 用于验证消息的完整性和准确性。 |
| 1字节“魔数”(Magic) | 表示Kafka服务程序的协议版本号。 |
| 1字节属性(Attributes) | 包含版本、压缩类型等信息。 |
| 4字节键长 | 表示消息键的长度,若键不存在,则该值为-1。 |
| K字节键(Key) | 消息的键,可选字段。 |
| 消息体(Value) | 实际的消息数据。 |
例如,一条典型的消息可能如下所示:
offset: 3 position: 211 CreateTime: 1606446771205 isvalid: true keysize: -1 valuesize: 7 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 4567890
基本概念
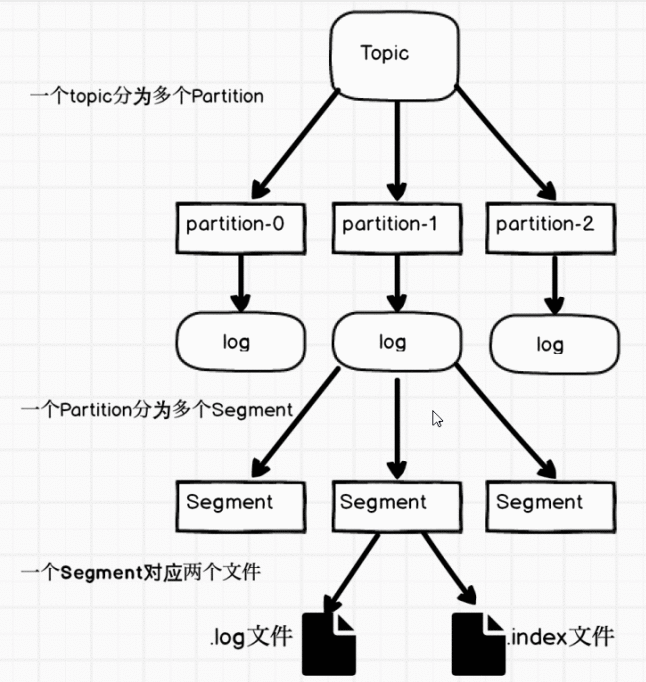
1. Kafka中的主题(Topic)是一个逻辑概念,所有消息根据分区(Partition)进行物理存储。
2. 分区对应于文件系统中的目录,命名格式为topicName-编号,编号从0开始。
3. 每个分区的数据进一步划分为多个段(Segment),每个段由.log和.index两个文件组成。
4. .log文件存储实际的消息数据,而.index文件则存储消息的索引信息,便于快速定位。
例如,名为pet的主题有3个分区,其目录结构如下:
drwxr-xr-x 2 root root 215 12月 1 10:27 pet-0 drwxr-xr-x 2 root root 215 12月 1 09:51 pet-1 drwxr-xr-x 2 root root 215 12月 1 09:51 pet-2
进入pet-0分区,可以看到如下文件结构:
-rw-r--r-- 1 root root 10485760 12月 1 09:44 00000000000000000000.index -rw-r--r-- 1 root root 4851 12月 1 17:29 00000000000000000000.log -rw-r--r-- 1 root root 10485756 12月 1 09:44 00000000000000000000.timeindex -rw-r--r-- 1 root root 34 12月 1 09:44 00000000000000000000.txnindex -rw-r--r-- 1 root root 240 12月 1 09:44 00000000000000000054.snapshot -rw-r--r-- 1 root root 28 12月 1 10:27 leader-epoch-checkpoint
其中,.index文件存储了稀疏的键值对,.log文件则存储了实际的消息内容。
消费者如何查找信息?
1. 消费者首先根据消息的偏移量(offset)查找索引文件(.index)。由于索引文件是以稀疏的方式存储的,可以通过二分查找快速定位。
2. 找到相应的索引文件后,根据偏移量找到对应的物理位置(position)。
3. 利用物理位置在日志文件(.log)中查找具体的消息内容,通过比较每条消息的偏移量来确定目标消息。
日志文件过大如何处理?
Kafka对日志文件的大小和生命周期有明确的管理策略:
1. 大小限制:单个日志文件的最大大小通常设置为1GB,超过此大小会自动创建新的日志文件。
2. 时间限制:根据配置的保留策略,消息会在一定时间后被删除以释放磁盘空间。例如,设置保留时间为2天,意味着消息在发布后2天内可被消费,之后将被删除。
日志文件与索引文件的区别
1. 索引文件(.index)中存储的是稀疏的键值对,主要用于快速定位消息。
2. 日志文件(.log)中存储的是实际的消息内容,每个消息都有固定的格式和字段。
文件命名规则
1. 日志文件和索引文件一一对应。
2. 日志文件的命名基于其第一条记录的偏移量值。
图解
总结
- Kafka的消息存储在分区目录下的日志文件中,索引文件则用于快速查找消息。
- 消费者通过偏移量(offset)在索引文件中找到物理位置(position),再在日志文件中查找具体的消息内容。











 京公网安备 11010802041100号
京公网安备 11010802041100号