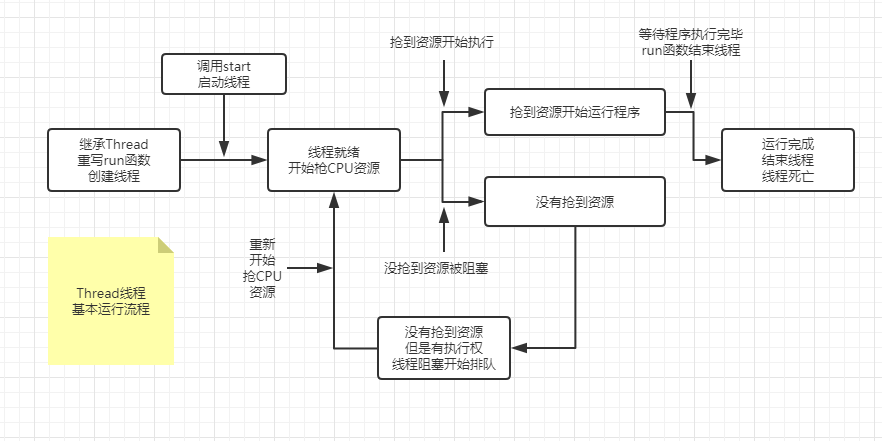
/**
* 无监控不调优,不知道她的性能怎么能调优?
* java虚拟机主要在内存中占这么几个部分
* 1:虚拟机栈:放局部变量,每一个方法对应一个栈针,方法里面的形参和局部变量全都放在这个栈针里面,也可以说这个栈针属于某一个线程,
*
每一个线程都有自己的一块栈空间,在这个线程里面调用一个方法的时候,就会启动一个栈针,每一个栈针都保存着这个方法用到的局部变量
* 2:堆:new出来的东西都放在堆里面
* 3:本地方法栈:java访问本地方法
* 4:方法区,在java8以后叫永久区,放class文件信息,静态变量,字符串常量,常量池这一类东西
* 5:程序计数器:程序执行时需要用到的临时寄存器
/**
* 堆内存分为:1:新生代 (new) 2老年代(old)
* 1:新生代分为eden survivor1 survivor2 (用的是copy的算法)
* eden里面放的对象很多,但是GC之后,剩的对象就会很少;当new一个不太大的对象时直接放到eden里面,这个时候发生了一次垃圾收集,这个对象没有被回收,他就被扔到survivor1,
* 运行第二次GC时,这个survivor1就被复制到survivor2中,同时
* 第二次eden没有被回收的对象也被扔到了survivor2中,又运行一次GC,就把survivor2里面没有被回收的对象和eden没有被回收的对象扔到survivor1中,以此类推,survivor1和survivor2
* 之间复制来复制去,为什么要复制来复制去,因为在内存中,复制是很快的,保证了效率
* 经过了好多次的GC,如果对象还没有被回收,他就会被放到old区
* 2:老年代:比较大的对象,或者是一直使用的对象(里面用的是marker-compact算法)
*/
/**
* java对象的分配
* 假如你的对象非常小,而且你开了栈上优化(默认是开着的),他会优先把这个对象放到栈上,为什么放大栈上?有什么好处?因为在栈针里面,当方法结束,栈针就没了,都不用垃圾收集了,自己就进行垃圾收集了
* 所以在栈上分配的效率特别高;加入你的栈空间分配满了,这个时候就去找线程本地内存;如果这个对象还是特别大,就把他放到老年代,假设老年代也不够大,就放到eden区
* 1:栈上分配
*
线程私有的小对象
*
无逃逸(在方法内new了一个对象,如果在方法外有一个引用指向这个对象,就说明这个对象已经逃逸出去了,这种对象绝不能在栈上分配)
*
支持标量替换(把这个栈里面的对象的成员变量单独拿出来放到栈上作为普通的数据类型往栈上存)
*
无需调整
* 2:线程本地分配TLAB(Thread Local Allacation Buffer)
*
占用eden,默认1%
*
多线程的时候不用竞争
eden就可以申请空间,提高效率
*
小对象
*
无需调整
* 3:老年代
*
大对象
* 4:eden
*/
/**引用:分为强软弱虚
* GC垃圾
*
* 什么是垃圾?
* String s = new String();此时s在栈里面,new出来的对象在堆里面,s指向堆里面的对象,假如让s=null,此时s没有任何一个引用,则堆里面的那个对象就成为垃圾了;;概念:一般来说,没有任何引用的对象就是垃圾
* 强软弱虚引用
* 如何确定垃圾?
* 1:引用计数,但是当处理循环引用时(A指向B,B指向A,在堆内存中,还有环形引用,A指B,B指C,C指A),这个就不行了。
* 2:采用正向可达的算法(根搜索算法),从roots对象(比如main方法里面创建的对象)计算可以到达的对象都不是垃圾,剩下的全是垃圾
* 垃圾收集算法(有很多,常用的是地下这个三个)
* 1:Mark-Sweep标记清除
*
把内存中可回收的对象标记出来,根据正向可达算法(根搜索算法找到需要回收的对象)然后清除它;这个算法最大的弊端就是内存碎片化,
*
如果来了一个大对象需要连续的空间,就无法存放他;这个时候就会产生fullgc全回收,这个时候就会把内存的对象压缩,给大对象腾地方,这样效率就低了
* 2:Copying复制(堆里面的两个survior来回复制)
*
效率比标记清除高,它把内存分为两部分,只用一半的内存,根据正向可达算法(根搜索算法)找到不是垃圾的对象,直接把他拷贝到另一半的内存中,而且是连续且压缩的,如果产生新对象就会放在它的下面,以此类推,再次回收都是这个过程
*
但是它的问题是浪费内存,4G内存只能使用2G
* 3:Mark-Compact标记压缩
*
把所有存活的对象都往一端压缩,压缩到一起(替换位置),效率比copying低一点
*/
/**
* jvm采用分带算法
* new :特点:存活对象少,使用copy算法,占用的空间不是很大,效率高
* old:垃圾少,一般使用marker-compact算法
*/
/**
* JVM参数
* 1:- 标准参数,所有jvm都应该支持(默认的jvm是HotSpot)
* 2:-X 非标准参数,每个jvm实现都不同
* 3:-XX 不稳定参数,下一个版本可能就没了
*/
/**
* JVM中的垃圾收集器
* 1:Serial Collector(序列化收集器)单线程,比较少用
* 2:Parallel Collector 多线程,并发量大,每次进行垃圾收集时,JVM需要停下来,等垃圾收集完,JVM才会继续执行
* 3:CMS Collector多线程且并发(分成好多的区,这些区一块来完成),停顿时间段,当我们进行垃圾收集时,JVM还会继续运行
* 4:G1 Collector(并发)不仅停顿短,同时并发大
* 如果你的需求并发量要求特别大,但是中间停顿1,2下没关系,应该选择Parallel Collector;如果你的业务要求及时响应,停顿时间比较短,那么应该选择CMS Collector;或者选择折中的G1 Collector
*
*/
/**
* 创建10000000万个对象的小例子,Run as--Runconfigurations--选择arguements,在VM arguements中写入-XX:-DoEscapeAnalysis -XX:-EliminateAllocations -XX:-UseTLAB -XX:+PrintGC
* -XX-DoEscapeAnalysis不做逃逸分析 前面是-就是不做逃逸分析,+就是做这个东西(默认是打开逃逸分析的,是可以在栈上分配的,如果是-就是不做逃逸分析)
* -XX-EliminateAllocations不做标量替换(有了这个和上面的那个就不在栈上分配了)
* -XX-UseTLAB不使用线程本地缓存
* -XX+PrintGC把这个GC的过程打印出来
* 如果按照上面的这种配置,则不在栈上分配,直接在eden分配;如果想要最快,就把前面三个参数都写成+
* -XX+PrintGCDetails打印GC细节(eden区和old区的使用情况)
* Runtime.getRuntime().totalMemory()打印所有的内存(大概);Runtime.getRuntime().freeMemory()打印空闲内存(大概)
* -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=c:\jvm.dump -XX:+PrintGCDetails -Xms10M -Xmx10M
* -XX+HeapDumpOnOutOfMemoryError 一旦遇到堆内存溢出了,请把信息给我倒出来
* HeapDumpPath=c:\jvm.dump就把信息给我放到这个下面 ,这个文件是在这个地方新创建的,如果原来有就会报错
* -Xms10M -Xmx10M 左边程序起始时为这个程序分配多少内存(堆的内存),右边为最大的内存一般情况下起始值要小于最大值,但在调优时往往起始值要接近或等于最大值 ;这两个参数在eclipse的eclipse.ini的文件内可以修改
* jvm.dump这个文件需要用专门的软件打开(工具特别多),在你的jdk的安装文件下bin\jvisualvm.exe,用这个打开,它用来监测虚拟机运行的情况
* 文件--装入--选择那个dump的文件--选择类--查看那个大小是最大的那个,然后回想这个有问题的地方
*/
/**
* 递归调用:方法一直调用自己,直到等到一个结束标志为止
* 线程栈的大小-Xss128k 如果这个值比较小,线程的并发数就特别多 如果这个数比较大 -Xss512k 线程的递归调用比较大,就会比较深
*/
/**
* 常用参数设置
* 1:堆设置
*
-Xms:初始堆大小
*
-Xmx:最大堆大小
*
-Xss:线程栈大小
*
-XX:NewSize=n:设置年轻代大小
*
-XX:NewRatio=n:设置年轻代和老年代的比值,比如:3,年轻代个老年代的比值为1:3
*
-XX:SurvivorRatio=n:年轻代中eden区和两个survivor区的比值,注意survicor区有两个,如3,表示Eden:Survivor=3:2
*
-XX:MaxPermitSize=n;设置持久带的大小
* 2:收集器设置
*
-XX:+UseSerialGC:设置串行收集器
*
-XX:+UseParallelGC:设置并行收集器
*
-XX:+UseConcMarkSweepGC:设置并发收集器
* 3:垃圾回收信息
*
-XX:+PrintGC
*
-XX:PrintGCDetails
*/
/**
* 典型的tomcat优化
* set JAVA_OPTS=
*
-Xms4g 给tomcat设置初始的内存4g,假设你的电脑是64g的,只有一个jvm在跑,那么你可以给她设置63g,这个时候如果java -version起不来了,设成62g,能跑起来就是62g,以此类推
*
-Xmx4g 最大的内存4g
*
-Xss512k 线程栈512k
*
-XX:+AggressiveOpts 设置jvm全部的优化
*
-XX:+UseBiasedLocking 偏置锁 优化线程的
*
-XX:PermSize=64M 永久区的大小 (jdk8取消了)
*
-XX:MaxPermSize=300M 最大300M
*
-XX:+DisableExplicitGC 不让你显示调用gc,也就是后面的方法//System.gc()
* 这些参数都放在tomcat安装文件的bin\catalina.bat文件里面
* set JAVA_OPTS=-Xms2g -Xmx2g等等
* 性能测试:找4太电脑,每台电脑起10000万个线程,每个线程都访问这个服务器,看响应时间是不是拖长了 可以使用免费软件JMeter测试
*/








 京公网安备 11010802041100号
京公网安备 11010802041100号