之前在整理Redis的五大数据结构的时候,其中提到了list、set等知识点的时候,就想起来刚上大学那会的青涩时光,抱着一本Java生啃得时候得傻样,跟女朋友交流的时候,她说那你怎么不也顺便整理一下啊,自己也回想以下那个时候咱俩谈恋爱你让我在机房等你的时候,哼!(ps:我闲的没啥事提这茬干啥啊,先去哄一下再回来继续写啊)
。。。
哄好了,回来继续写,翻出来那个时候整理的笔记,这是我做的思维导图(当时我的导师要求我做的,我感谢他培养了我这个习惯),正好在这里当作目录使用了(后面讲解得时候,我会展开展示)
在学Java以前,一说到存放东西,第一个想到的就是使用数组,使用数组,在数据的存取方面的却也挺方便,其存储效率高访问快,但是它也受到了一些限制,比如说数组的长度以及数组的类型,当我需要一组string类型数据的同时还需要Integer类型的话,就需要定义两次,同时,数组长度也受到限制,即使是动态定义数组长度,但是长度依然需要固定在某一个范围内,不方便也不灵活。
如果说我想要消除上面的这个限制和不方便应该怎么办呢?Java是否提供了相应的解决方法。答案是肯定的,这就是Java容器,java容器是javaAPI所提供的一系列类的实例,用于在程序中存放对象,主要位于Java.util包中,其长度不受限制,类型不受限制,你在存放String类的时候依然能够存放Integer类,两者不会冲突。
容器API类图结果如下所示:
Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
举例:
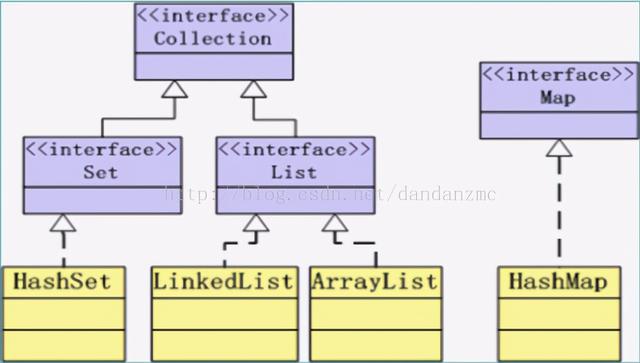
import java.util.*;public class TestA{public static void main(String[] args){Collection lstcoll=new ArrayList(); lstcoll.add("China"); lstcoll.add(new String("ZD")); System.out.println("size="+lstcoll.size()); System.out.println(lstcoll);}
结果:
List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,也就是说它是有顺序的,类似于Java的数组。和Set不同,List允许有相同的元素。J2SDK所提供的List容器类有ArrayList、LinkedList等。
实例:
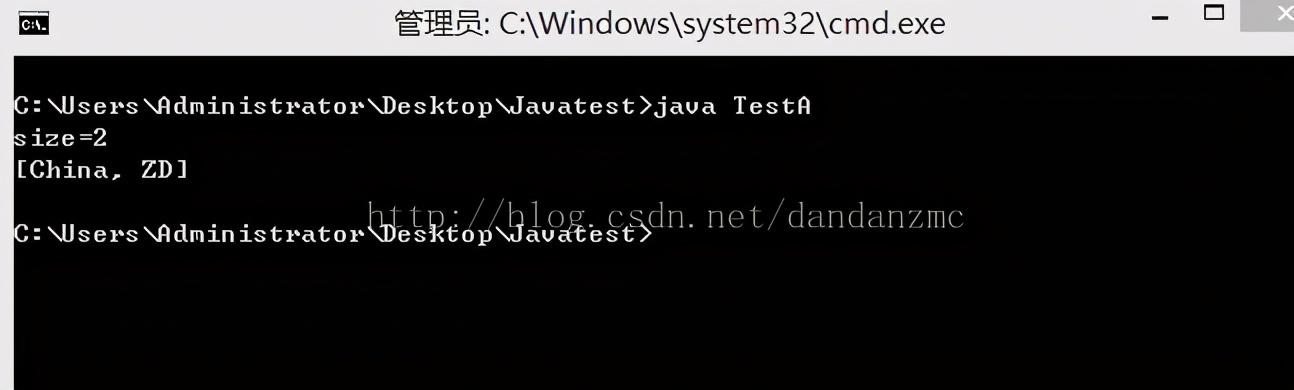
import java.util.*;public class TestB{public static void main(String[] args){List l1&#61;new LinkedList();for(int i&#61;0;i<&#61;5;i&#43;&#43;){l1.add("a"&#43;i);}System.out.println(l1);l1.add(3,"a100");System.out.println(l1);l1.set(6,"a200");System.out.println(l1);System.out.println((String)l1.get(2)&#43;" ");l1.remove(1);System.out.println(l1);}}
运行结果&#xff1a;
ArrayList
ArrayList其实就相当于顺式存储&#xff0c;它包装了一个数组 Object[]&#xff0c;当实例化一个ArrayList时&#xff0c;一个数组也被实例化&#xff0c;当向ArrayList中添加对象时&#xff0c;数组的大小也相应的改变。这样就带来以下有特点&#xff1a; 快速随即访问&#xff0c;你可以随即访问每个元素而不用考虑性能问题&#xff0c;通过调用get(i)方法来访问下标为i的数组元素。 向其中添加对象速度慢&#xff0c;当你创建数组时并不能确定其容量&#xff0c;所以当改变这个数组时就必须在内存中做很多事情。 操作其中对象的速度慢&#xff0c;当你要向数组中任意两个元素中间添加对象时&#xff0c;数组需要移动所有后面的对象。
下面我们来看一下源码级实际操作
基于数组&#xff0c;支持快速随机访问
public class ArrayList extends AbstractList implements List, RandomAccess, Cloneable, java.io.Serializable // 实现了RandomAccess表示支持快速随机访问
数组默认大小为10&#xff0c;基于数组实现
private static final int DEFAULT_CAPACITY &#61; 10;transient Object[] elementData; // non-private to simplify nested class access
添加元素时会调用add()方法&#xff0c;同时使用ensureCapacityInternal()方法来保证调用add()方法时数组的容量&#xff0c;当数组容量不够时&#xff0c;会调用grow()方法进行扩容。
扩容代码&#xff1a;
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity &#61; elementData.length; int newCapacity &#61; oldCapacity &#43; (oldCapacity >> 1); // 扩容大小为原来的1.5倍 ...... ......// minCapacity is usually close to size, so this is a win: elementData &#61; Arrays.copyOf(elementData, newCapacity); // 将原来的数组拷贝进新的数组&#xff0c;扩容的代价高 }
删除元素是会调用system.arraycopy()方法&#xff0c;将index&#43;1后面的元素都复制到index的位置上&#xff0c;代价高
System.arraycopy(elementData, index&#43;1, elementData, index, numMoved);
LinkedList
LinkedList相当于链式存储&#xff0c;它是通过节点直接彼此连接来实现的。每一个节点都包含前一个节点的引用&#xff0c;后一个节点的引用和节点存储的值。当一个新节点插入时&#xff0c;只需要修改其中保持先后关系的节点的引用即可&#xff0c;当删除记录时也一样。这样就带来以下特点&#xff1a; 操作其中对象的速度快&#xff0c;只需要改变连接&#xff0c;新的节点可以在内存中的任何地方。 不能随即访问&#xff0c;虽然存在get()方法&#xff0c;但是这个方法是通过遍历接点来定位的&#xff0c;所以速度慢。
代码实现
private static class Node { E item; Node next; Node prev; Node(Node prev, E element, Node next) { this.item &#61; element; this.next &#61; next; this.prev &#61; prev; } }
Set接口
Set是一种不包含重复的元素的Collection&#xff0c;即任意的两个元素e1和e2都有e1.equals(e2)&#61;false&#xff0c;Set最多有一个null元素。 Set的构造函数有一个约束条件&#xff0c;传入的Collection参数不能包含重复的元素。
Set容器类主要有HashSet和TreeSet等。
HashSet
此类实现 Set 接口&#xff0c;由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序&#xff1b;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
举例&#xff1a;
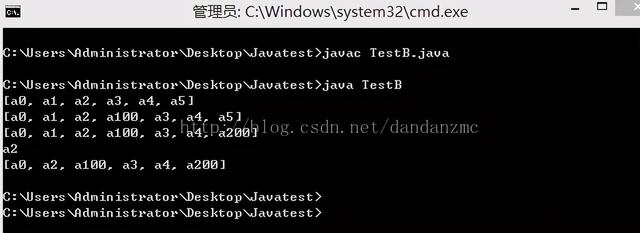
import java.util.*;public class TestC{public static void main(String[] args){Set s&#61;new HashSet();s.add("Hello"); //相同元素s.add("Hello"); System.out.println(s);}
结果&#xff1a;
treeset
TreeSet是一个有序的集合&#xff0c;它的作用是提供有序的Set集合。它继承了AbstractSet抽象类&#xff0c;实现了NavigableSet&#xff0c;Cloneable&#xff0c;Serializable接口。TreeSet是基于TreeMap实现的&#xff0c;TreeSet的元素支持2种排序方式&#xff1a;自然排序或者根据提供的Comparator进行排序。
实例
public static void demoOne() { TreeSet ts &#61; new TreeSet<>(); ts.add(new Person("张三", 11)); ts.add(new Person("李四", 12)); ts.add(new Person("王五", 15)); ts.add(new Person("赵六", 21)); System.out.println(ts); }
执行结果&#xff1a;会抛出一个 异常&#xff1a;java.lang.ClassCastException
显然是出现了类型转换异常。原因在于我们需要告诉TreeSet如何来进行比较元素&#xff0c;如果不指定&#xff0c;就会抛出这个异常
如何解决&#xff1a;
如何指定比较的规则&#xff0c;需要在自定义类(Person)中实现Comparable接口&#xff0c;并重写接口中的compareTo方法
public class Person implements Comparable { private String name; private int age; ... public int compareTo(Person o) { return 0; //当compareTo方法返回0的时候集合中只有一个元素 return 1; //当compareTo方法返回正数的时候集合会怎么存就怎么取 return -1; //当compareTo方法返回负数的时候集合会倒序存储 }}
为什么返回0&#xff0c;只会存一个元素&#xff0c;返回-1会倒序存储&#xff0c;返回1会怎么存就怎么取呢&#xff1f;原因在于TreeSet底层其实是一个二叉树机构&#xff0c;且每插入一个新元素(第一个除外)都会调用compareTo()方法去和上一个插入的元素作比较&#xff0c;并按二叉树的结构进行排列。
如果将compareTo()返回值写死为0&#xff0c;元素值每次比较&#xff0c;都认为是相同的元素&#xff0c;这时就不再向TreeSet中插入除第一个外的新元素。所以TreeSet中就只存在插入的第一个元素。
如果将compareTo()返回值写死为1&#xff0c;元素值每次比较&#xff0c;都认为新插入的元素比上一个元素大&#xff0c;于是二叉树存储时&#xff0c;会存在根的右侧&#xff0c;读取时就是正序排列的。
如果将compareTo()返回值写死为-1&#xff0c;元素值每次比较&#xff0c;都认为新插入的元素比上一个元素小&#xff0c;于是二叉树存储时&#xff0c;会存在根的左侧&#xff0c;读取时就是倒序序排列的。
Map接口
值得注意的是Map没有继承Collection接口&#xff0c;Map接口是提供key到value的映射。一个Map中不能包含相同的key&#xff0c;每个key只能映射一个value。即是一一映射&#xff0c;Map接口提供3种集合的视图&#xff0c;Map的内容可以被当作一组key集合&#xff0c;一组value集合&#xff0c;或者一组key-value映射。
Map接口的实现类主要是包括HashMap和TreeMap等。
HaspMap
添加数据使用put(key, value)&#xff0c;取出数据使用get(key)&#xff0c; HashMap是允许null&#xff0c;即null value和null key。但是将HashMap视为Collection时(values()方法可返回Collection)&#xff0c;其迭代子操作时间开销和HashMap的容量成比例。因此&#xff0c;如果迭代操作的性能相当重要的话&#xff0c;不要将HashMap的初始化容量设得过高&#xff0c;或者load factor过低。
举例&#xff1a;
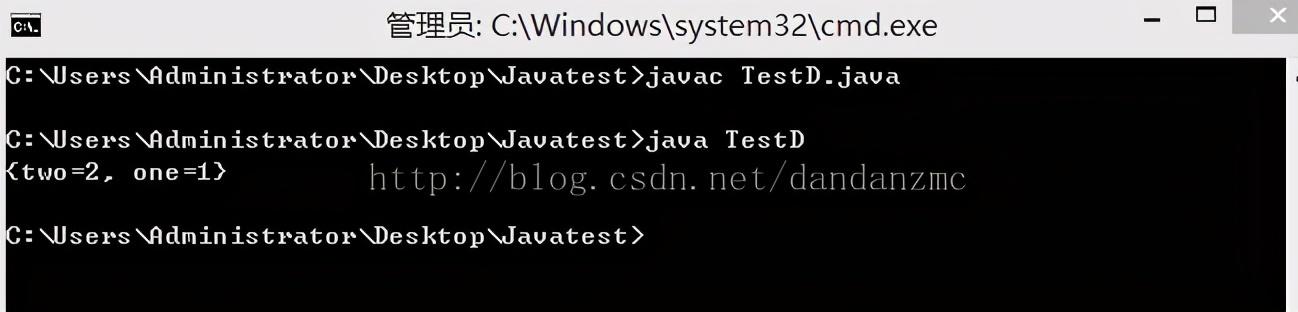
import java.util.*;public class TestD{public static void main(String[] args){Map M&#61;new HashMap ();M.put("one",new String("1"));M.put("two",new String("2"));System.out.println(M);}}
结果&#xff1a;
ConcurrentHashMap
并发下使用的线程安全的 HashMap 的替代品&#xff0c;基于JDK1.7源码。
数据存储结构&#xff0c;HashMap为Entry。
static final class HashEntry { final int hash; final K key; volatile V value; volatile HashEntry next;}
// ConcurrentHashMap 采用了分段锁(Segment)技术&#xff0c;每个分段锁维护着几个桶(HashEntry)&#xff0c;多个线程可以同时访问不同分段锁上的桶&#xff0c;Segment[]代替了table[]。final Segment[] segments;//Segment核心类继承自重入锁ReentrantLock。static final class Segment extends ReentrantLock implements Serializable { // ConcurrentHashMap默认并发级别是16&#xff0c;因为有16个Segmen。 // 默认并发级别为16static final int DEFAULT_CONCURRENCY_LEVEL &#61; 16;
总结
Java容器实际上只有三种:Map , List, Set;但每种接口都有不同的实现版本.它们的区别可以归纳为由什么在背后支持它们.也就是说,你使用的接口是由什么样的数据结构实现的.
List的选择:
比如:ArrayList和LinkedList都实现了List接口.因此无论选择哪一个,基本操作都一样.但ArrayList是由数组提供底层支持.而LinkedList是由双向链表实现的.所以,如果要经常向List里插入或删除数据,LinkedList会比较好.否则应该用速度更快的ArrayList。
Set的选择
HashSet总是比TreeSet 性能要好.而后者存在的理由就是它可以维持元素的排序状态.所以,如果需要一个排好序的Set时,才应该用TreeSet。
Map选择:
同上,尽量选择HashMap。
其实每一个牵扯到底层得面试题都都不是很难&#xff0c;但是也不能掉以轻心&#xff0c;如果平时没有注意这个地方得知识&#xff0c;那你在面试的时候一定会让你吃亏&#xff0c;这就是开发这一行得魅力&#xff0c;享受这一行得刺激把













 京公网安备 11010802041100号
京公网安备 11010802041100号