作者:12sadad | 来源:互联网 | 2024-11-30 10:51
本文详细介绍了ZooKeeper作为分布式服务协调框架的核心功能与应用场景,包括其数据一致性解决方案、数据结构特点、监听通知机制及选举机制等,帮助开发者更好地理解和应用ZooKeeper。
一、ZooKeeper概述
ZooKeeper是一个高效且可靠的分布式服务协调框架,旨在解决分布式环境中的数据一致性问题。它通过提供一系列的基础服务,如数据发布/订阅、负载均衡、命名服务、配置管理、分布式锁及集群管理等功能,极大地简化了分布式系统的构建。
二、ZooKeeper的优势
ZooKeeper的设计确保了以下几点优势:
- 更新请求的顺序性:保证来自同一客户端的更新请求按照发送顺序执行。
- 数据更新的原子性:每次数据更新操作要么完全成功,要么彻底失败。
- 全局一致的数据视图:无论客户端连接到哪个服务器,都能获得一致的数据视图。
- 实时性:在一定的时间范围内,客户端能够读取到最新的数据。
三、ZooKeeper的数据模型
ZooKeeper的数据模型类似于Unix文件系统,整体结构可以视为一棵树,每个节点称为ZNode。每个ZNode默认可以存储1MB的数据,并且可以通过唯一的路径进行标识。ZNode支持四种类型:
- PERSISTENT(持久节点):创建后除非手动删除,否则不会因客户端与服务端的断开而消失。
- PERSISTENT_SEQUENTIAL(持久顺序节点):除了具有持久节点的特点外,还会自动生成顺序编号。
- EPHEMERAL(临时节点):当客户端与服务端的连接中断时,该节点会被自动删除。
- EPHEMERAL_SEQUENTIAL(临时顺序节点):结合了临时节点和顺序节点的特点,在连接中断时被删除,同时拥有自增的序列号。
四、监听机制
ZooKeeper的监听机制基于观察者模式,允许客户端设置Watcher来监控特定ZNode的变化。当监控的ZNode发生数据变更、子节点变更或创建/删除时,ZooKeeper会通知相应的客户端。需要注意的是,每个Watcher只能触发一次,若需持续监控,则需在收到通知后重新设置Watcher。
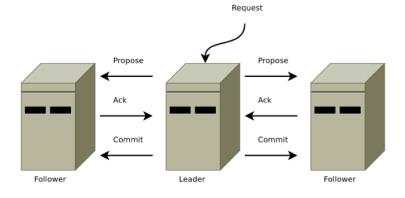
五、选举机制
在集群模式下,ZooKeeper通过内部选举机制选出一个Leader节点,其余节点作为Follower。选举过程遵循“半数可用”原则,即超过半数的节点必须可用才能形成有效的集群,因此建议集群规模设置为奇数,以提高容错能力。在运行过程中,如果Leader节点长时间无法与其他节点通信,集群将重新进行选举,以保证服务的连续性和可用性。
六、快速入门
安装ZooKeeper非常简单,首先从官方网站下载最新版本的ZooKeeper压缩包,解压后将/conf目录下的zoo_sample.cfg文件复制并重命名为zoo.cfg。编辑zoo.cfg文件,设置dataDir参数指向数据存储目录。启动ZooKeeper服务时,进入/bin目录,根据操作系统选择相应的启动脚本(如Windows系统下使用zkServer.cmd)。启动成功后,可以通过命令行工具或图形界面工具(如ZooInspector)对ZooKeeper进行管理和操作。








 京公网安备 11010802041100号
京公网安备 11010802041100号