实现一个文件的搜索功能,通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来。
数据分类:
结构化数据: 指具有固定格式或有限长度的数据,如数据库等;
非结构化数据: 指不定长或无固定格式的数据, 如邮件、word 文档中的数据等;
全文检索原理:相当于字典,分为目录和正文两部分,查询的时候通过先查目录,然后通过目录上标注的页数去正文页查找需要的内容。
将文件中的内容提取出来, 将文字拆封成一个一个的词(分词), 将这些词组成索引(字典中的目录), 搜索的时候先搜索索引,通过索引找文档,这种先建立索引,再对索引进行搜索的过程就叫全文检索;
分词: 去掉停用词(a, an, the ,的, 地, 得, 啊, 嗯 ,呵呵),因为搜索的时候搜索这些词没有意义,将句子拆分成词,去掉标点符号和空格;
优点: 搜索速度快
缺点: 因为创建的索引需要占用磁盘空间,所以这个算法会使用掉更多的磁盘空间,这是用空间换时间,对比顺序扫描法效率更高;
Lucene实现全文检索:
Lucene 是 apache 软件基金会 4 jakarta 项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是apache下的一个开放源代码的全文检索引擎工具包,通过它可以实现全文检索。
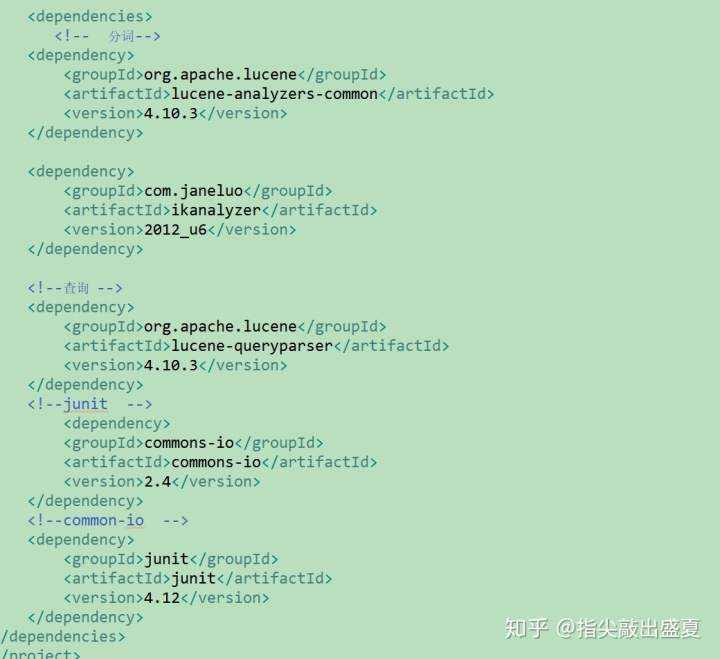
Lucene包:
lucene-core-4.10.3.jar 核心包
lucene-analyzers-common-4.10.3.jar 分词包
lucene-queryparser-4.10.3.jar 查询包
再配置文件中引入相应依赖:
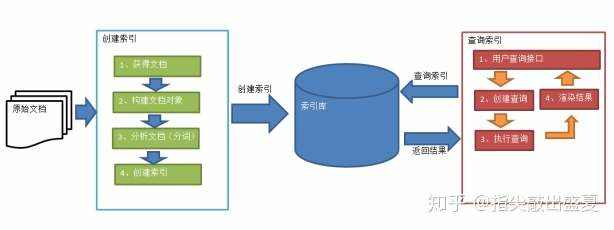
索引和检索流程图:
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:获得原始文档à创建文档对象à分析文档à创建索引
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面à创建查询à执行搜索,从索引库搜索à渲染搜索结果
原始文档:是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
本案例要获取磁盘上文件的内容,可以通过文件流来读取文本文件的内容,对于pdf、doc、xls等文件可通过第三方提供的解析工具读取文件内容,比如Apache POI读取doc和xls的文件内容。
创建索引
索引结构:域名:词
索引作用:它里面有指针指向这个词来源的文档
中文分词器(重点)
IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
1、添加pom依赖
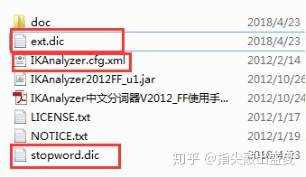
2、配置IKAnalyzer.cfg.xml和ext.dic(UTF-8)、stopword.dic(UTF-8)
3、修改分词器:Analyzer analyzer = new IKAnalyzer();
IKAnalyzer.cfg.xml:
扩展词典:ext.dic(按需定义)
停用词词典:stopword.dic
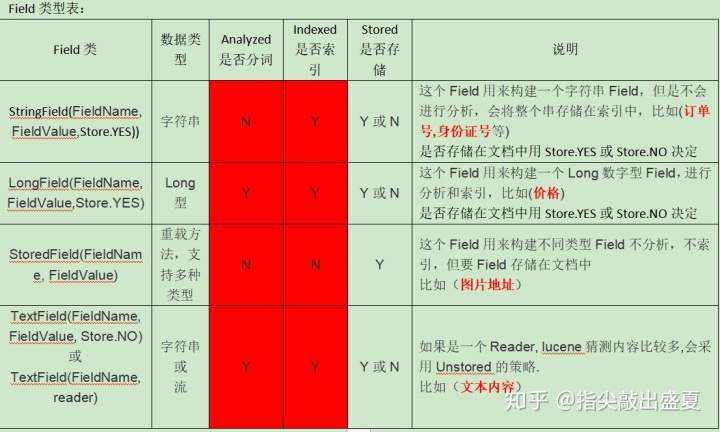
4. Field的详细介绍(难点)
分词:是否对域的内容进行分词处理。比如:订单号、身份证号不需要分词
是否索引:将Field分析后的词进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
注意:lucene底层的算法,钱数是要分词的,因为要根据价钱进行对比索引库的维护:
文档的删除
文档的添加
文档的修改
索引库的查询(重点):
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
未完















 京公网安备 11010802041100号
京公网安备 11010802041100号