作者:吴佳云怡婷志贤 | 来源:互联网 | 2023-08-27 14:53
原文链接:
PV 是Page Views的缩写,即页面浏览量,用户每一次对网站中的每个网页访问均被记录一次。注意,访客每刷新一次页面,pv就增加一次。
我们目前的数据是:

其中的数据我们会得到标注

根据标注我们进行代码筛选,编写MapReduce
分析:我们先根据标注的表中有一个"省份"的字段,依据"省份"编写map。
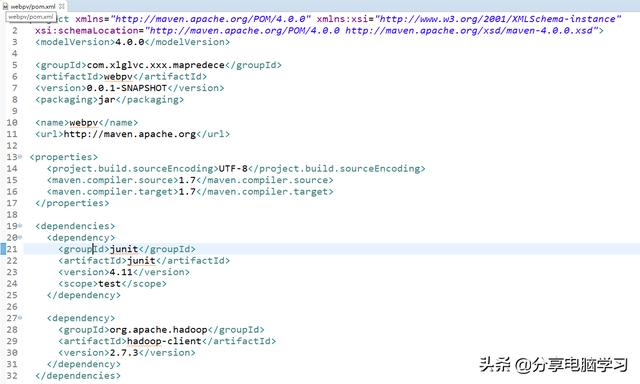
首先我们创建Maven项目

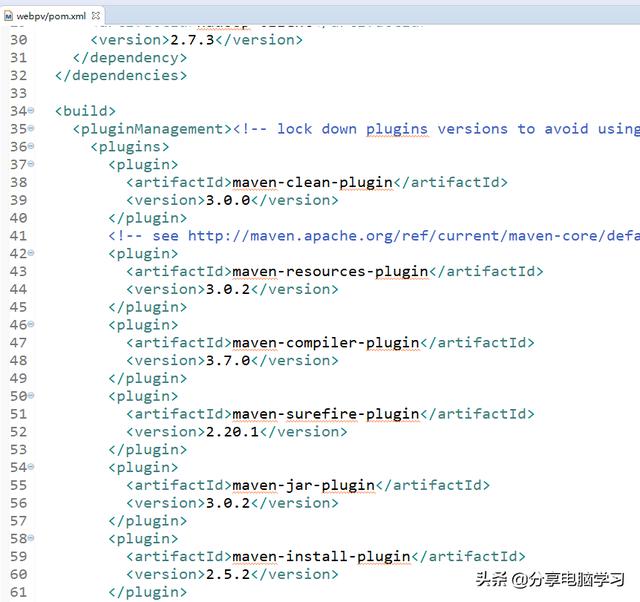
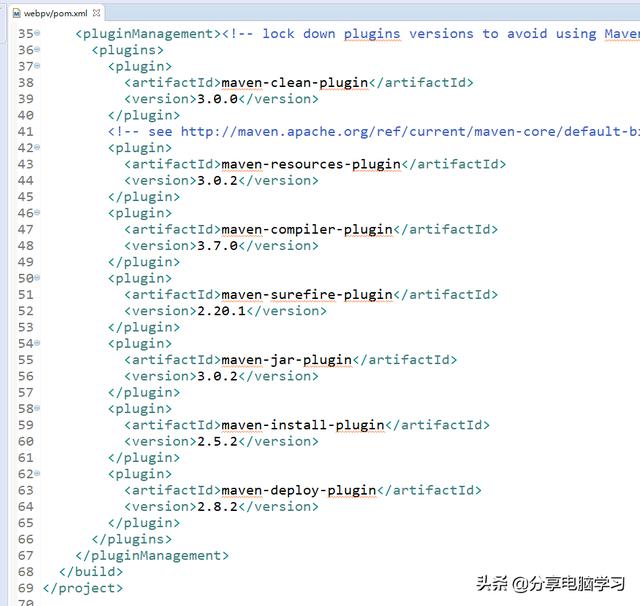
填写pom信息
创建Map类
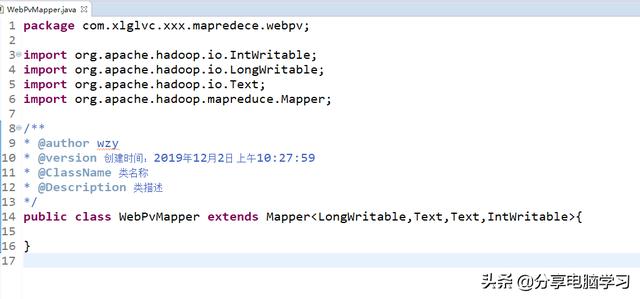
基本结构如下:
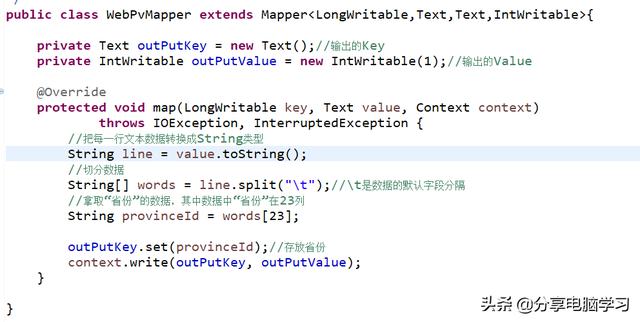
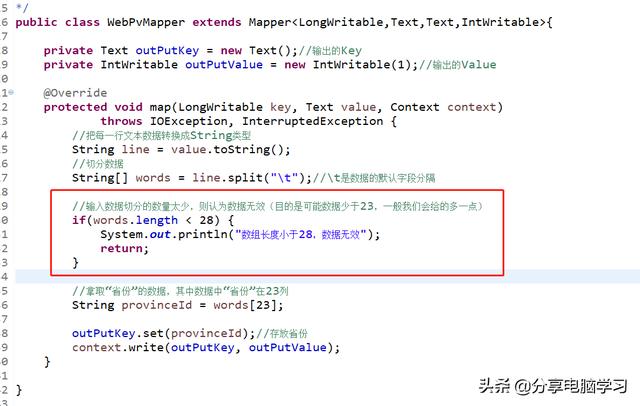
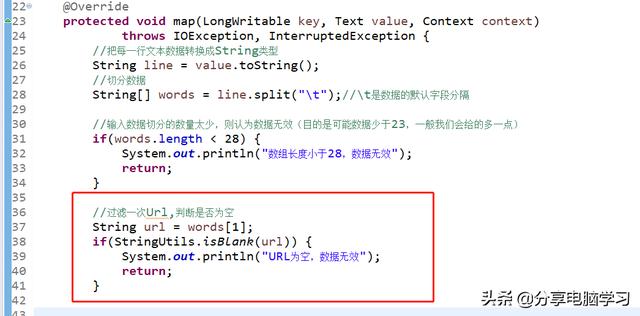
我们需要对原数据进行筛选
长度筛选
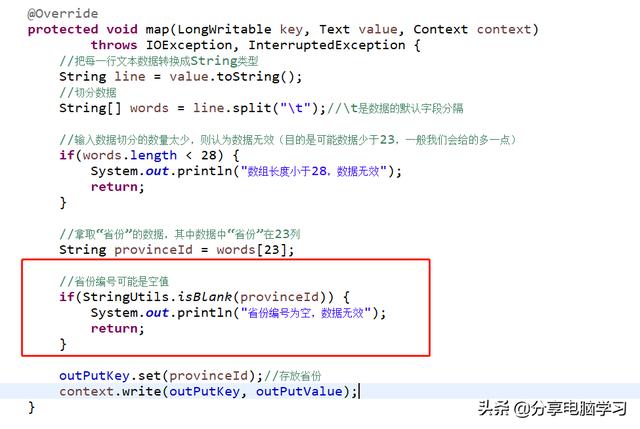
省份编号是空值
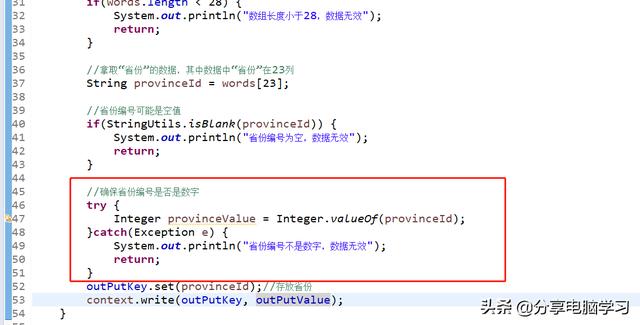
确保数字编号是否是数字
筛选URL是否为空值
创建Reduce类
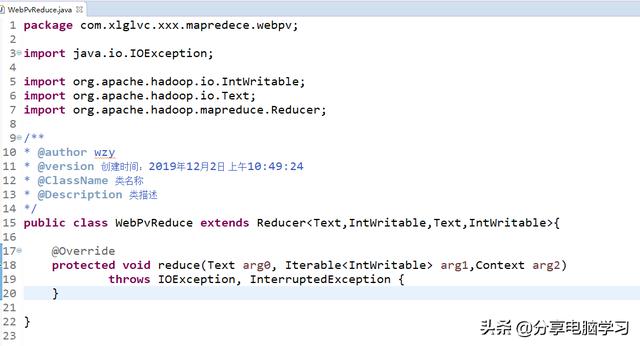
编写内容
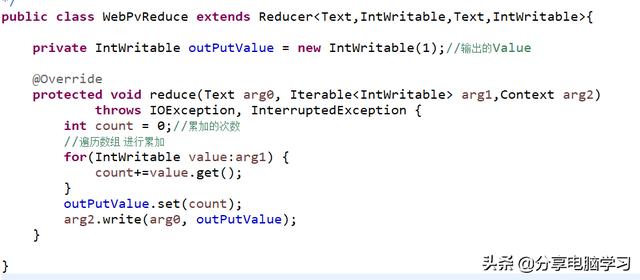
创建运行类
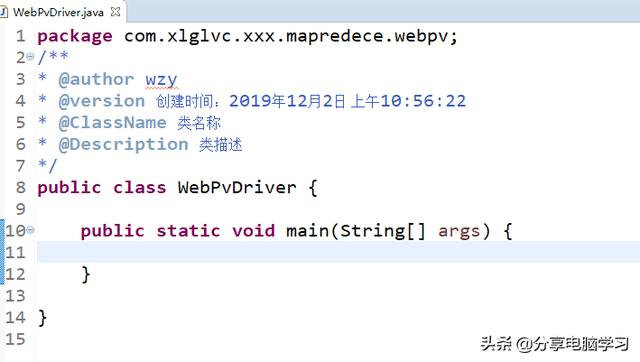
编写程序内容
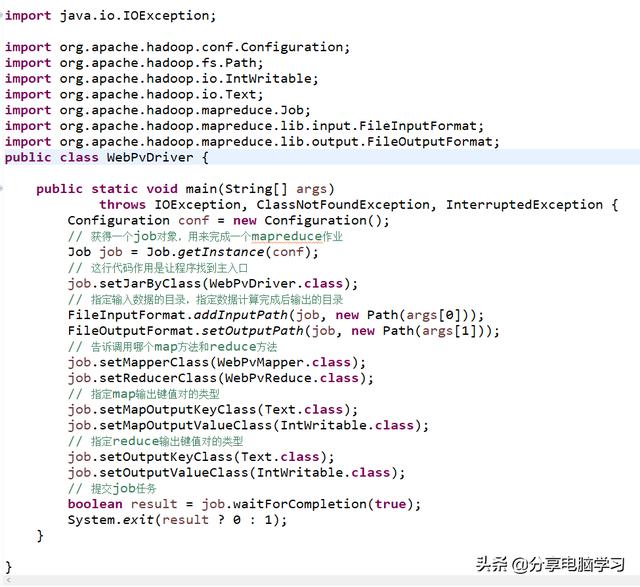
准备数据源文件和Jar包

启动Hadoop
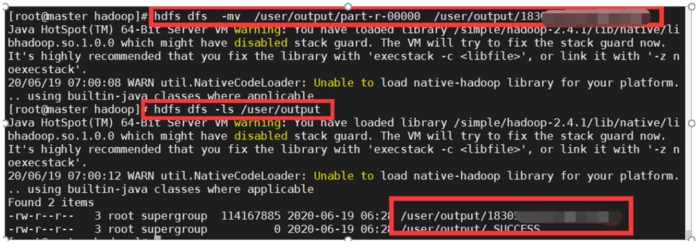
我们将数据上传到HDFS中

我们查看下数据,发现数据已经上传了

我们执行我们的jar包
yarn jar /data/webpv/webpv.jar com.xlglvc.xxx.mapredece.webpv.WebPvDriver /webpv/data1 /webpvoutput

执行成功
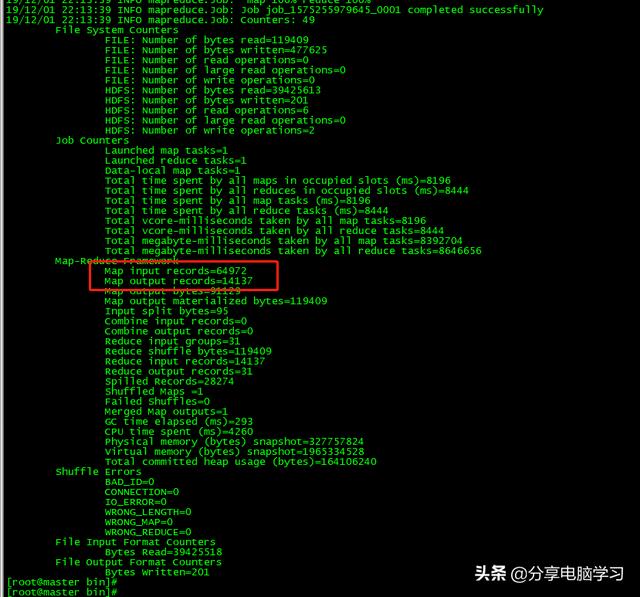
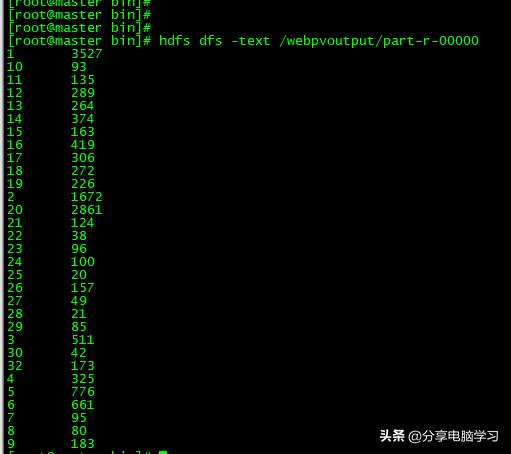
我们查看生成的数据,已经生成了,我们查看下最终数据

这样我们就知道每个省份最终访问的次数了,了解到那个省份访问的最多了










 京公网安备 11010802041100号
京公网安备 11010802041100号