作者:小呀小-儿郎 | 来源:互联网 | 2023-09-16 14:43
Java对象的复制三种方式概述在实际编程过程中,我们常常要遇到这种情况:有一个对象A,在某一时刻A中已经包含了一些有效值,此时可能会需要一个和A完全相同新对象B,并且此后对B任何改
Java对象的复制三种方式
概述
在实际编程过程中,我们常常要遇到这种情况:有一个对象A,在某一时刻A中已经包含了一些有效值,此时可能 会需要一个和A完全相同新对象B,并且此后对B任何改动都不会影响到A中的值,也就是说,A与B是两个独立的对象,但B的初始值是由A对象确定的。例如下面程序展示的情况:
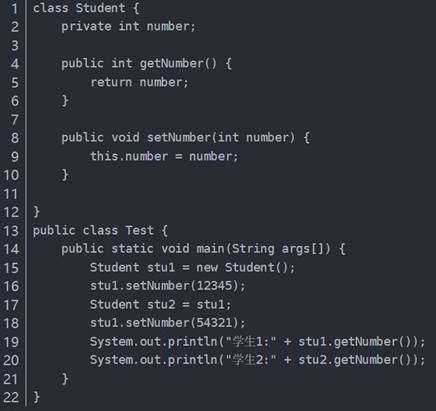
结果:

为什么改变学生2的学号,学生1的学号也发生了变化呢?
原因出在(stu2 = stu1) 这一句。该语句的作用是将stu1的引用赋值给stu2,
这样,stu1和stu2指向内存堆中同一个对象。如图:
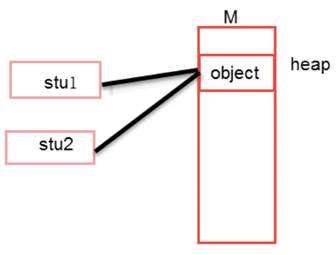
那么,怎么能干干净净清清楚楚地复制一个对象呢。在 Java语言中,用简单的赋值语句是不能满足这种需求的。要满足这种需求有很多途径,
(1)将A对象的值分别通过set方法加入B对象中;
(2)通过重写java.lang.Object类中的方法clone();
(3)通过org.apache.commons中的工具类BeanUtils和PropertyUtils进行对象复制;
(4)通过序列化实现对象的复制。
2.将A对象的值分别通过set方法加入B对象中
对属性逐个赋值,本实例为了演示简单就设置了一个属性:

我们发现,属性少对属性逐个赋值还挺方便,但是属性多时,就需要一直get、set了,非常麻烦。
3.重写java.lang.Object类中的方法clone()
先介绍一下两种不同的克隆方法,浅克隆(ShallowClone)和深克隆(DeepClone)。
在Java语言中,数据类型分为值类型(基本数据类型)和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制,下面将对两者进行详细介绍。
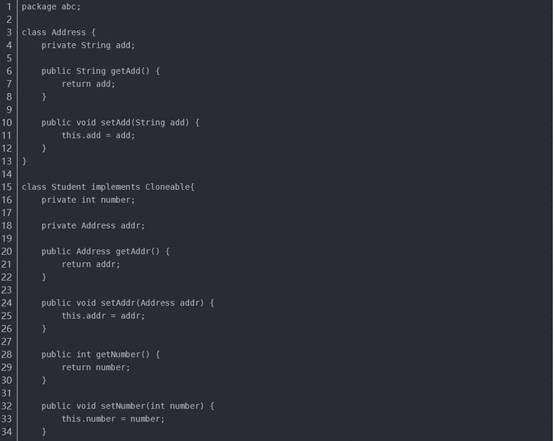
3.1浅克隆
一般步骤:
1.被复制的类需要实现Clonenable接口(不实现的话在调用clone方法会抛出CloneNotSupportedException异常), 该接口为标记接口(不含任何方法)
2.覆盖clone()方法,访问修饰符设为public。方法中调用super.clone()方法得到需要的复制对象。(native为本地方法)
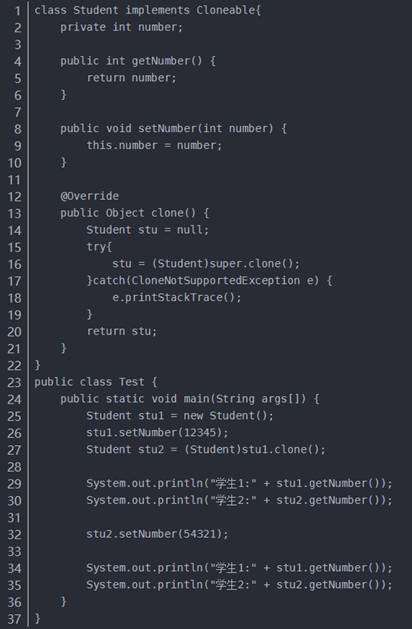

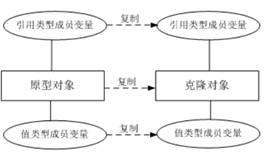
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。
简单来说,在浅克隆中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
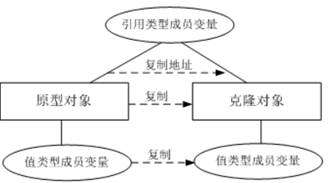
在Java语言中,通过覆盖Object类的clone()方法可以实现浅克隆
3.2深克隆
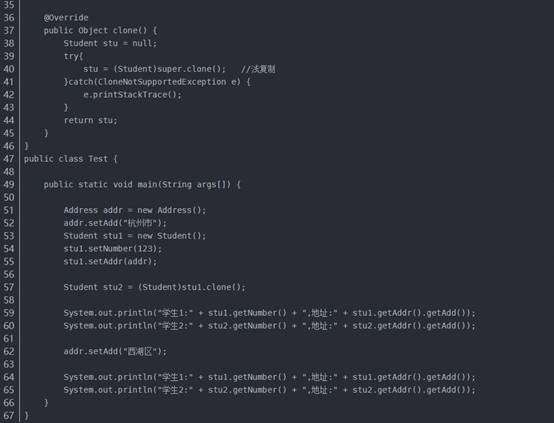

怎么两个学生的地址都改变了?
原因是浅复制只是复制了addr变量的引用,并没有真正的开辟另一块空间,将值复制后再将引用返回给新对象。
为了达到真正的复制对象,而不是纯粹引用复制。我们需要将Address类可复制化,并且修改clone方法,完整代码如下:
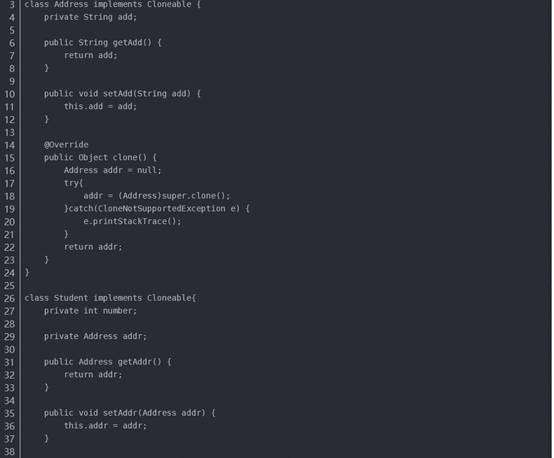
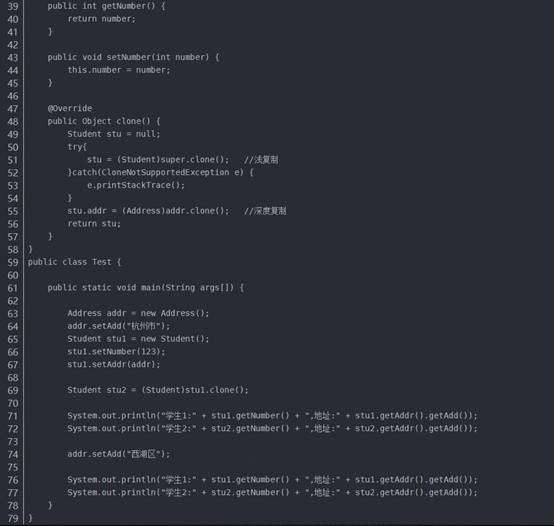
 在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。
简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
在Java语言中,如果需要实现深克隆,可以通过覆盖Object类的clone()方法实现,也可以通过序列化(Serialization)等方式来实现。
(如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。)
4.工具类BeanUtils和PropertyUtils进行对象复制

这种写法无论多少种属性都只需要一行代码搞定,很方便吧!除BeanUtils外还有一个名为PropertyUtils的工具类,它也提供copyProperties()方法,作用与BeanUtils的同名方法十分相似,主要的区别在于BeanUtils提供类型转换功能,即发现两个JavaBean的同名属性为不同类型时,在支持的数据类型范围内进行转换,而PropertyUtils不支持这个功能,但是速度会更快一些。在实际开发中,BeanUtils使用更普遍一点,犯错的风险更低一点。
5.通过序列化实现对象的复制
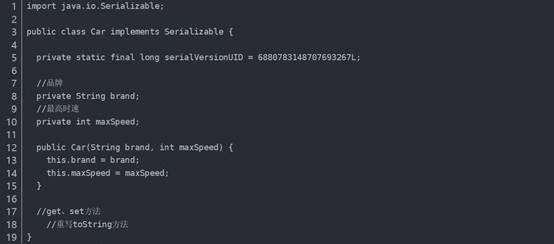
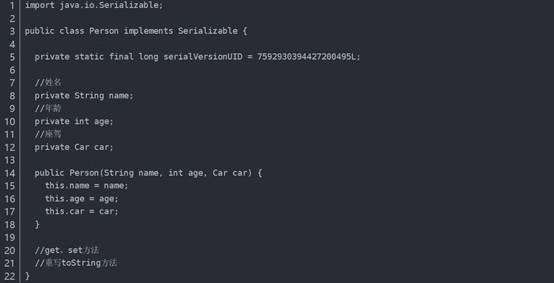
序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
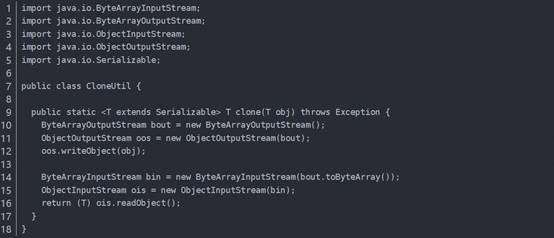
调用ByteArrayOutputStream或ByteArrayInputStream对象的close方法没有任何意义。这两个基于内存的流只要垃圾收集器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放。

修改克隆的Person对象person1关联的汽车对象的品牌属性,原来的Person对象person关联的汽车不会受到任何影响,因为在克隆Person对象时其关联的汽车对象也被克隆了。
基于序列化和反序列化实现的克隆不仅仅时深度克隆,更重要的是通过范型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译期完成的,不是在运行时抛出异常,这种方案明显优于使用Object类的clone方法克隆对象。






 京公网安备 11010802041100号
京公网安备 11010802041100号