最近批量刷数据的时候,由于集群资源紧张,需要控制一些 map 的数量,本文从底层代码触发,带大家了解一下 MR 是如何让切分 map 数的。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sq l语句转换为 MapReduce 任务进行运行。当运行一个 hql 语句的时候,map 数是如何计算出来的呢?有哪些方法可以调整 map 数呢?
本文测试集群版本:cdh-4.3.0
hive 默认的 input format在 cdh-4.3.0 的 hive 中查看 hive.input.format 值(为什么是hive.input.format?):
hive> set hive.input.format;hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
可以看到默认值为 CombineHiveInputFormat,如果你使用的是 IDH 的hive,则默认值为:
hive> set hive.input.format;hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
CombineHiveInputFormat 类继承自 HiveInputFormat,而 HiveInputFormat 实现了 org.apache.hadoop.mapred.InputFormat 接口,关于 InputFormat 的分析,可以参考Hadoop深入学习:InputFormat组件.
InputFormat 接口功能简单来说,InputFormat 主要用于描述输入数据的格式,提供了以下两个功能:
1)、数据切分,按照某个策略将输入数据且分成若干个 split,以便确定 Map Task 的个数即 Mapper 的个数,在 MapReduce 框架中,一个 split 就意味着需要一个 Map Task;
2)、为 Mapper 提供输入数据,即给定一个 split(使用其中的 RecordReader 对象)将之解析为一个个的 key/value 键值对。
该类接口定义如下:
public interface InputFormat{public InputSplit[] getSplits(JobConf job,int numSplits) throws IOException;public RecordReader getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException;}
其中,getSplit() 方法主要用于切分数据,每一份数据由,split 只是在逻辑上对数据分片,并不会在磁盘上将数据切分成 split 物理分片,实际上数据在 HDFS 上还是以 block 为基本单位来存储数据的。InputSplit 只记录了 Mapper 要处理的数据的元数据信息,如起始位置、长度和所在的节点。
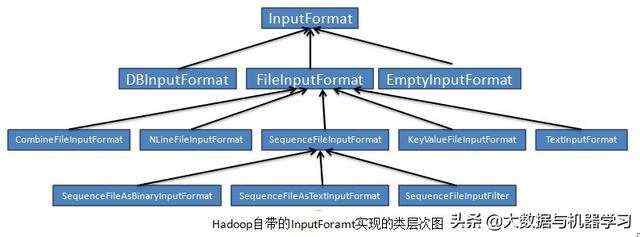
MapReduce 自带了一些 InputFormat 的实现类:
hive 中有一些 InputFormat 的实现类,如:
AvroContainerInputFormatRCFileBlockMergeInputFormatRCFileInputFormatFlatFileInputFormatOneNullRowInputFormatReworkMapredInputFormatSymbolicInputFormatSymlinkTextInputFormatHiveInputFormat
HiveInputFormat 的子类有:
HiveInputFormat以 HiveInputFormat 为例,看看其getSplit()方法逻辑:
for (Path dir : dirs) {PartitionDesc part = getPartitionDescFromPath(pathToPartitionInfo, dir);// create a new InputFormat instance if this is the first time to see this// classClass inputFormatClass = part.getInputFileFormatClass();InputFormat inputFormat = getInputFormatFromCache(inputFormatClass, job);Utilities.copyTableJobPropertiesToConf(part.getTableDesc(), newjob);// Make filter pushdown information available to getSplits.ArrayList aliases =mrwork.getPathToAliases().get(dir.toUri().toString());if ((aliases != null) && (aliases.size() == 1)) {Operator op = mrwork.getAliasToWork().get(aliases.get(0));if ((op != null) && (op instanceof TableScanOperator)) {TableScanOperator tableScan = (TableScanOperator) op;pushFilters(newjob, tableScan);}}FileInputFormat.setInputPaths(newjob, dir);newjob.setInputFormat(inputFormat.getClass());InputSplit[] iss = inputFormat.getSplits(newjob, numSplits / dirs.length);for (InputSplit is : iss) {result.add(new HiveInputSplit(is, inputFormatClass.getName()));}}
上面代码主要过程是:
遍历每个输入目录,然后获得 PartitionDesc 对象,从该对象调用 getInputFileFormatClass 方法得到实际的 InputFormat 类,并调用其 getSplits(newjob, numSplits / dirs.length) 方法。
按照上面代码逻辑,似乎 hive 中每一个表都应该有一个 InputFormat 实现类。在 hive 中运行下面代码,可以查看建表语句:
hive> show create table info;OKCREATE TABLE info(statist_date string,statistics_date string,inner_code string,office_no string,window_no string,ticket_no string,id_kind string,id_no string,id_name string,area_center_code string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ';'LINES TERMINATED BY ''STORED AS INPUTFORMAT'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION'hdfs://node:8020/user/hive/warehouse/info'TBLPROPERTIES ('numPartitions'='0','numFiles'='1','transient_lastDdlTime'='1378245263','numRows'='0','totalSize'='301240320','rawDataSize'='0')Time taken: 0.497 seconds
从上面可以看到 info 表的 INPUTFORMAT 为org.apache.hadoop.mapred.TextInputFormat,TextInputFormat 继承自FileInputFormat。FileInputFormat 是一个抽象类,它最重要的功能是为各种 InputFormat 提供统一的 getSplits()方法,该方法最核心的是文件切分算法和 Host 选择算法。
算法如下:
long length = file.getLen();long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);long blockSize = file.getBlockSize();long splitSize = computeSplitSize(goalSize, minSize, blockSize);long bytesRemaining = length;while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {String[] splitHosts = getSplitHosts(blkLocations,length-bytesRemaining, splitSize, clusterMap);splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts));bytesRemaining -= splitSize;}
华丽的分割线:以下摘抄自Hadoop深入学习:InputFormat组件
1)文件切分算法
文件切分算法主要用于确定InputSplit的个数以及每个InputSplit对应的数据段,FileInputSplit以文件为单位切分生成InputSplit。有三个属性值来确定InputSplit的个数:
- goalSize:该值由 totalSize/numSplits 来确定 InputSplit 的长度,它是根据用户的期望的 InputSplit 个数计算出来的;numSplits 为用户设定的 Map Task 的个数,默认为1。
- minSize:由配置参数 mapred.min.split.size(或者 mapreduce.input.fileinputformat.split.minsize)决定的 InputForma t的最小长度,默认为1。
- blockSize:HDFS 中的文件存储块block的大小,默认为64MB。
- numSplits=mapred.map.tasks 或者 mapreduce.job.maps
这三个参数决定一个 InputFormat 分片的最终的长度,计算方法如下:
splitSize = max{minSize,min{goalSize,blockSize}}
计算出了分片的长度后,也就确定了 InputFormat 的数目。
2)host 选择算法
InputFormat 的切分方案确定后,接下来就是要确定每一个 InputSplit 的元数据信息。InputSplit 元数据通常包括四部分,其意义为:
- file 标识 InputSplit 分片所在的文件;
- InputSplit 分片在文件中的的起始位置;
- InputSplit 分片的长度;
- 分片所在的 host 节点的列表。
InputSplit 的 host 列表的算作策略直接影响到运行作业的本地性。
我们知道,由于大文件存储在 HDFS上的 block 可能会遍布整个 Hadoop 集群,而一个 InputSplit 分片的划分算法可能会导致一个 split 分片对应多个不在同一个节点上的 blocks,这就会使得在 Map Task 执行过程中会涉及到读其他节点上的属于该 Task 的 block 中的数据,从而不能实现数据本地性,而造成更多的网络传输开销。
一个 InputSplit 分片对应的 blocks 可能位于多个数据节点地上,但是基于任务调度的效率,通常情况下,不会把一个分片涉及的所有的节点信息都加到其host列表中,而是选择包含该分片的数据总量的最大的前几个节点,作为任务调度时判断是否具有本地性的主要凭证。
FileInputFormat 使用了一个启发式的 host 选择算法:首先按照 rack 机架包含的数据量对 rack 排序,然后再在 rack 内部按照每个 node 节点包含的数据量对 node 排序,最后选取前 N 个(N 为 block 的副本数),node 的 host 作为 InputSplit 分片的 host 列表。当任务地调度 Task 作业时,只要将 Task 调度给 host 列表上的节点,就可以认为该 Task 满足了本地性。
从上面的信息我们可以知道,当 InputSplit 分片的大小大于 block 的大小时,Map Task 并不能完全满足数据的本地性,总有一本分的数据要通过网络从远程节点上读数据,故为了提高 Map Task 的数据本地性,减少网络传输的开销,应尽量是 InputFormat 的大小和 HDFS 的 block 块大小相同。
CombineHiveInputFormatgetSplits(JobConf job, int numSplits) 代码运行过程如下:
init(job);CombineFileInputFormatShim combine = ShimLoader.getHadoopShims().getCombineFileInputFormat();ShimLoader.loadShims(HADOOP_SHIM_CLASSES, HadoopShims.class);Hadoop23ShimsHadoopShimsSecure.getCombineFileInputFormat()
CombineFileInputFormatShim 继承了org.apache.hadoop.mapred.lib.CombineFileInputFormat,CombineFileInputFormatShim 的 getSplits 方法代码如下:
public InputSplitShim[] getSplits(JobConf job, int numSplits) throws IOException {long minSize = job.getLong("mapred.min.split.size



 京公网安备 11010802041100号
京公网安备 11010802041100号