- HBase简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具
- 主键:Row Key
主键是用来检索记录的主键,访问hbase table中的行,只有三种方式
通过单个row key访问
通过row key的range
全表扫描
- 列族:Column Family
列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型
- 时间戳:timestamp
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引
- HBASE基础知识
物理存储
Table 在行的方向上分割为多个HRegion,一个region由[startkey,endkey)表示,每个HRegion分散在不同的RegionServer中
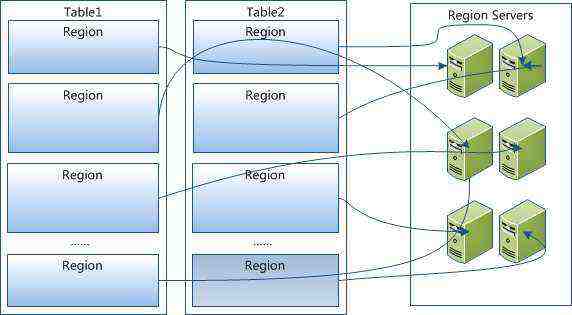
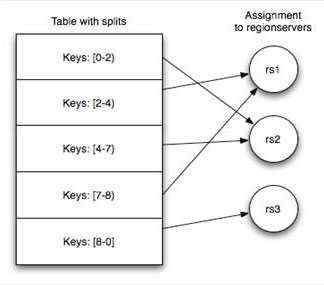
架构体系
- i. Client 包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
- ii. Zookeeper
- 保证任何时候,集群中只有一个running master
- 存贮所有Region 的寻址入口
- 实时监控Region Server 的状态,将Region server 的上线和下线信息,实时通知给Master
- 存储Hbase 的schema,包括有哪些table,每个table 有哪些column family
- iii. Master 可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
- 为Region server 分配region
- 负责region server 的负载均衡
- 发现失效的region server 并重新分配其上的region
HBase中有两张特殊的Table,-ROOT-和.META.
-ROOT- :记录了.META.表的Region信息,-ROOT-只有一个region
.META. :记录了用户创建的表的Region信息,.META.可以有多个regoin
Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问
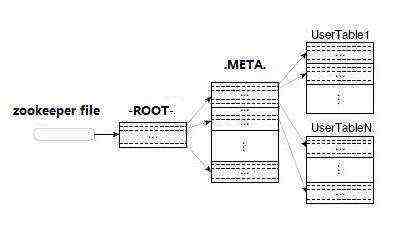
- Region Server
1、维护Master 分配给它的region,处理对这些region 的IO 请求
2、负责切分在运行过程中变得过大的region
可以看出,client 访问hbase 上数据的过程并不需要master 参与,寻址访问先zookeeper再regionserver,数据读写访问regioneserver。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
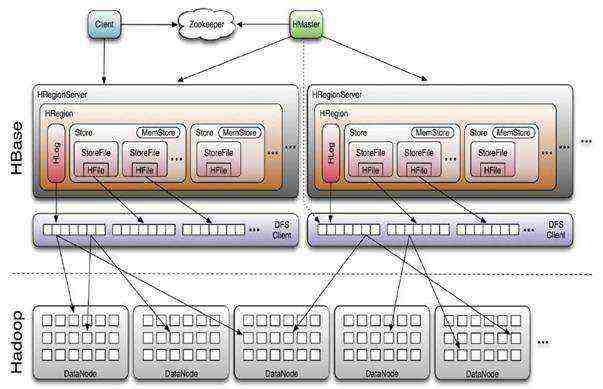
- Hbase表存储结构:

- HBASE Shell的DDL操作
|
名称
|
命令表达式
|
|
创建表
|
create ‘表名称‘, ‘列族名称1‘,‘列族名称2‘,‘列族名称N‘
|
|
添加记录
|
put ‘表名称‘, ‘行名称‘, ‘列名称:‘, ‘值‘
|
|
查看记录
|
get ‘表名称‘, ‘行名称‘
|
|
查看表中的记录总数
|
count ‘表名称‘
|
|
删除记录
|
delete ‘表名‘ ,‘行名称‘ , ‘列名称‘
|
|
删除一张表
|
先要屏蔽该表,才能对该表进行删除,第一步 disable ‘表名称‘ 第二步 drop ‘表名称‘
|
|
查看所有记录
|
scan "表名称"
|
|
查看某个表某个列中所有数据
|
scan "表名称" , {COLUMNS=>‘列族名称:列名称‘}
|
|
更新记录
|
就是重写一遍进行覆盖
|
1、 创建表
>create ‘users‘,‘user_id‘,‘address‘,‘info‘
表users,有三个列族user_id,address,info
2、 列出全部表
>list
3、 得到表的描述
>describe ‘users‘
4、 创建表
>create ‘users_tmp‘,‘user_id‘,‘address‘,‘info‘
5、 删除表
>disable ‘users_tmp‘
>drop ‘users_tmp‘
- HBASE Shell的DML操作
1、 添加记录
put ‘users‘,‘xiaoming‘,‘info:age‘,‘24‘;
put ‘users‘,‘xiaoming‘,‘info:birthday‘,‘1987-06-17‘;
put ‘users‘,‘xiaoming‘,‘info:company‘,‘alibaba‘;
2、 获取一条记录
1.取得一个id的所有数据
>get ‘users‘,‘xiaoming‘
2.获取一个id,一个列族的所有数据
>get ‘users‘,‘xiaoming‘,‘info‘
3.获取一个id,一个列族中一个列的
所有数据
get ‘users‘,‘xiaoming‘,‘info:age‘
3、 更新记录
>put ‘users‘,‘xiaoming‘,‘info:age‘ ,‘29‘
>get ‘users‘,‘xiaoming‘,‘info:age‘
>put ‘users‘,‘xiaoming‘,‘info:age‘ ,‘30‘
>get ‘users‘,‘xiaoming‘,‘info:age‘
4、 获取单元格数据的版本数据
>get ‘users‘,‘xiaoming‘,{COLUMN=>‘info:age‘,VERSIOnS=>1}
>get ‘users‘,‘xiaoming‘,{COLUMN=>‘info:age‘,VERSIOnS=>2}
>get ‘users‘,‘xiaoming‘,{COLUMN=>‘info:age‘,VERSIOnS=>3}
5、 获取单元格数据的某个版本数据
〉get ‘users‘,‘xiaoming‘,{COLUMN=>‘info:age‘,TIMESTAMP=>1364874937056}
6、 全表扫描
>scan ‘users‘
- HBASE的Java_API(一)
11. import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.jruby.RubyProcess;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* Created by Administrator on 2017/3/13.
*/
public class Application {
private Configuration cOnf= null;
@Before
public void init(){
cOnf= HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop4:2181,hadoop5:2181,hadoop6:2181");
}
@Test
public void testDrop() throws IOException {
HBaseAdmin admin=new HBaseAdmin(conf);
admin.disableTable("account");
admin.deleteTable("account");
admin.close();
}
@Test
public void testPut() throws IOException {
HTable table=new HTable(conf,"book");
Put put =new Put(Bytes.toBytes("book0005"));
put.add(Bytes.toBytes("dock1"),Bytes.toBytes("info"),Bytes.toBytes("liuyan"));
table.put(put);
table.close();
}
@Test
public void testGet() throws IOException {
HTable table =new HTable(conf,"book");
Get get=new Get(Bytes.toBytes("book0001"));
get.addColumn(Bytes.toBytes("dock1"),Bytes.toBytes("info"));
get.addColumn(Bytes.toBytes("dock1"),Bytes.toBytes("isbn"));
Result result=table.get(get);
for (KeyValue kv: result.list()) {
String family =new String( kv.getFamily());
System.out.print(family);
String clum=new String(kv.getQualifier());
System.out.print(clum);
System.out.print(new String(kv.getValue()));
}
}
@Test
public void testDel() throws IOException {
HTable table=new HTable(conf,"book");
Delete delete=new Delete(Bytes.toBytes("book0001"));
delete.deleteColumn(Bytes.toBytes("dock1"),Bytes.toBytes("info"));
table.delete(delete);
table.close();
}
@Test
public void testScan() throws IOException {
HTablePool pool=new HTablePool(conf,10);
HTableInterface hTableInterface=pool.getTable("book");
Scan scan=new Scan(Bytes.toBytes("book0001"),Bytes.toBytes("book0005"));
scan.addFamily(Bytes.toBytes("dock1"));
ResultScanner results= hTableInterface.getScanner(scan);
for (Result t : results){
byte[]value=t.getValue(Bytes.toBytes("dock1"),Bytes.toBytes("isbn"));
System.out.print(new String(value));
}
}
public static void main(String[] args) throws IOException {
Configuration cOnf= HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop4:2181,hadoop5:2181,hadoop6:2181");
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
} catch (IOException e) {
e.printStackTrace();
}
HTableDescriptor td = new HTableDescriptor(TableName.valueOf("htable"));
HColumnDescriptor cd = new HColumnDescriptor("info");
cd.setMaxVersions(10);
td.addFamily(cd);
admin.createTable(td);
admin.close();
// System.out.print("11111111111");
}
}
hbase 学习笔记







 京公网安备 11010802041100号
京公网安备 11010802041100号