作者:傻孩纸黄国帅哟 | 来源:互联网 | 2023-07-18 18:14
flink源码学习:http:www.cnblogs.combethunebtjp9168274.htmlflinkonyarn执行任务的两种方式1.yarn-session.sh
flink源码学习:
http://www.cnblogs.com/bethunebtj/p/9168274.html
flink on yarn 执行任务的两种方式
1.yarn-session.sh(开辟资源)+flink run(提交任务)
1.在yarn中起一个守护进程,用于启动多个job,即一个application master 管理多个job
2.启动命令:
./yarn-session.sh -n 4 -jm 1024 -tm 5120 -s 5 -nm yarn-session-jobs -d
参数说明:
(1) -n : 指定number of task manager,指定taskmanager个数
(2) -jm: jobmanager所占用的内存数,单位为MB
(3) -tm: 指定每个taskmanager所占用的内存,单位为MB
(4) -s: 指定每个taskmanager可使用的cpu核数
(5) -nm: 指定Application的名称
(6) -d : 后台启动,session启动后,进程关闭
3.流程说明:
(1) 启动session 后,yarn首先会分配一个Container,用于启动APP master和jobmanager, 所占用内存为-jm指定的内存大小,cpu为1核
(2) 没有启动job之前,jobmanager是不会启动taskmanager的(jobmanager会根据job的并行度,即所占用的slots,来动态的分配taskmanager)
(3) 提交任务到APP master
./flink run -p 3 -yid application_id -d -c com.kn.rt.Test01 ~/jar/dw-1.0-SNAPSHOT.jar
用于启动一个job到指定的APP master中
参数说明:
#1.-p:指定任务的并行度,如果你在程序代码中指定了并行度的话,那么此处的并行度参数不起作用
#2.-yid:指定任务提交到哪一个application—id,默认是提交到本节点最新提交的一个application
#3.-c: job的主入口 + jar path
> 注:job参数要写在-c之前,不然指定参数不起作用...
1.2 flink run -m yarn-cluster(开辟资源+提交任务)
1.启动单个job,即单job单session,实现资源的完全隔离
2.启动job的脚本跟yarn-session 中有差异 ,通过指定 -m yarn-cluster,参数较session都带有-y
./flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 3076 -ys 3 -ynm yarn-cluster-1 -yqu root.default -c com.kn.rt.Test01 ~/jar/dw-1.0-SNAPSHOT.jar
参数说明:
#1.-m :yarn-cluster,代表启动单session提交单一job
#2.-yn:taskmanager个数
#3.-yjm:jobmanager的内存占用
#4.-ytm:每个taskmanager的内存占用
#5.-ys: 每个taskmanager可使用的CPU核数
#6.-ynm:application 名称
#7.-yqu:指定job的队列名称
#8.-c: 程序主入口+ jar path
1.3.flink on yarn设置参数注意事项
1.资源都统一有yarn来统一管理,配置-jm -tm -s时,要小于container配置的最大内存、最大CPU核数
1.4.flink-conf.yaml (flink on yarn 配置文件)
env.java.home: /usr/local/jdk1.8.0_181
recovery.mode: zookeeper
recovery.zookeeper.quorum: hadoop-bd1:2181,hadoop-bd2:2181,hadoop-bd3:2181
recovery.zookeeper.path.root: /data/dw/flink
recovery.zookeeper.path.namespace: /cluster_yarn
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://hadoop-bd1:8020/flink/dw/checkpoints
recovery.zookeeper.storageDir: hdfs://hadoop-bd1:8020/flink/dw/recovery
#taskmanager.network.numberOfBuffers: 64000
fs.hdfs.hadoopconf: /etc/hadoop/conf
taskmanager.heap.size: 1024m
taskmanager.network.memory.fraction: 0.1
taskmanager.network.memory.min: 64mb
taskmanager.network.memory.max: 1gb
flink 状态管理及容错
2.1 容错 checkpoint savepoint 机制
在程序中开启checkpoint机制
//开启checkpoint,并且设置消息消费机制为exactly_once,保证计算结果的准确性
env.enableCheckpointing(10000, CheckpointingMode.EXACTLY_ONCE)
//设置backend的文件存放方式:本地文件 or hdfs(常用)
// env.setStateBackend(new FsStateBackend("file:///data/www/check_point"))
env.setStateBackend(new FsStateBackend("hdfs://10.1.0.4:8020/user/mp")) //checkpoint文件保留到hdfs
// 设置checkpoint在cancel任务时,保留checkpoint文件
env.getCheckpointConfig.enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//设置checkpoint文件的保存版本最多为2
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
2.2 在hdfs中查看checkpoint文件信息
(1)hdfs dfs -ls /user/mp #每一次启动一个任务,都会随机生成一个jobid
(2)根据jobid查看当前checkpoint版本信息
/user/mp/ea69f28ec72647727d7b4284ae494589
(3)查看check文件
/user/mp/ea69f28ec72647727d7b4284ae494589/chk-2035 (用于恢复job的checkpoint路径)
/user/mp/ea69f28ec72647727d7b4284ae494589/shared
/user/mp/ea69f28ec72647727d7b4284ae494589/taskowned
(4)其中chk-2035 存有_metadata
2.3 根据checkpoint文件恢复job
bin/flink run -s -yid <指定applicationid> -yjm -ytm -ys -d -c
(1)从指定的checkpoint版本恢复job
(2)提交任务到指定的application
(3)可以重新调整 jm tm slots 参数...
2.4 手动触发保存savepoint
(1)savepoint也可以保存在hdfs中
(2)bin/flink savepoint -yid
(3)eg:bin/flink savepoint ea69f28ec72647727d7b4284ae494589 hdfs:///user/mp/savepoint -yid application_1557217934896_0105
(4)查看hdfs的savepoint文件:/user/mp/savepoint/savepoint-ea69f2-c740c68b737c,其中带有_metadata文件,用于恢复job
bin/flink run -d -s -yid -yjm -ytm -c
eg:bin/flink run -d -s hdfs:///user/mp/savepoint/savepoint-ea69f2-c740c68b737c -yid application_1557217934896_0105 -c com.kn.rt.KafkaWordCount /data/www/check_point/flink-checkpoint-1.0-SNAPSHOT.jar
往往在新起一个job时,需要迭代计算外部存储的数据作为初始化
实现CheckPointedFunction接口类,实现initializeState接口,即可初始化state数据
继承RichSinkFunction 方法的同时,通过with 关键字继承CheckpointedFunction
class MySink extends RichSinkFunction[Tuple2[String,Long]] with CheckpointedFunction{
private var conn: COnnection= _
private var ps: Statement = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
try {
val prop = new Properties
try
prop.load(classOf[MysqlSink].getClassLoader.getResourceAsStream("db.properties"))
catch {
case e: IOException =>
e.printStackTrace()
}
val msyql_driver = prop.get("mysql_driver").asInstanceOf[String]
val msyql_url = prop.get("mysql_url").asInstanceOf[String]
val msyql_user = prop.get("mysql_user").asInstanceOf[String]
val msyql_passwd = prop.get("mysql_passwd").asInstanceOf[String]
Class.forName(msyql_driver)
cOnn= DriverManager.getConnection(msyql_url, msyql_user, msyql_passwd)
ps = conn.createStatement()
} catch {
case e: Exception =>
// logger.error("jdbc exception:{}",e);
e.printStackTrace()
}
}
override def invoke(value: (String, Long), context: SinkFunction.Context[_]): Unit = {
super.invoke(value, context)
ps.execute("insert into result1(word,num) values ('" + value._1 + "'," + value._2 + ")")
}
override def close(): Unit = {
super.close()
if (ps != null){
ps.close()
}
if (conn != null){
conn.close()
}
}
//初始化state数据,该方法在首次初始化时调用,或者在恢复前一个快照的时候执行
override def initializeState(context: FunctionInitializationContext): Unit = {
val state = context.getKeyedStateStore.getState(new ValueStateDescriptor[Tuple2[String,Long]]("wordCount",
TypeInformation.of(new TypeHint[Tuple2[String,Long]](){})))
}
//该方法在每次执行快照的时候执行
override def snapshotState(context: FunctionSnapshotContext): Unit = ???
}
3. flink资源管理
3.1 flink 先了解以下几个概念
3.1.1 JobManager
(1)jobmanager 主要是负责接收客户端的job,调度job,协调checkpoint等
(2)无论是standalone 还是flink on yarn 模式都会启动jobmanager 和taskmanager
3.1.2 TaskManager
(1)TaskManager执行具体的Task,也就是具体做事的
(2)taskmanager 对资源进行了隔离,引入了slot的概念
(3)taskmanager 和 Jobmanager通讯采用actor的机制
3.1.3 job
(1)client 提交的任务
3.1.4 task及subtask
(1)先介绍什么是subtask?每个算子的一个并行化实例就是一个subtask,多个subtask可以通过chain操作合成一个task,再作为一个整体task来调度执行,(task采用单独的线程,即链式操作中的执行是串行的)
(2)solt是一个jvm进程,一个solt中可以执行多个task(线程) ,同一个jvm中的task,可以共享TCP和心跳信息,减少网络传输,共享一些数据结构,在一定程度上减少task的消耗
(3)同一个job的不同task的subtask才能共享slot
3.1.5 slot 及 shared slot
(1)slots代表着TaskManager的一个固定的资源子集,一个taskmanager有3个solts,那么每个solt平分1/3的托管内存
(2)将资源solt化,意味着来自不同job的task不会为了内存而竞争,每个task拥有一定内存的储备;需要注意的是,slot只是隔离了内存,但没有隔离cpu
(3)尽可能地让多个task共享一个slot (SlotSharingGroup)
3.2 flink 资源分配与并行度管理(runtime)
[外链图片转存失败(img-2fO7ute0-1562289945279)(https://ci.apache.org/projects/flink/flink-docs-release-1.4/fig/tasks_chains.svg)]
(1)如上图:我们的数据流操作为source(p=2) -> map(p=2) -> keyby、window、apply(p=2) -> sink (p=1)
(2)source、map等非密集型操作,其并行度为2,所以我们可以将source和map链在一起,tm会在2个solt中分别启用task1: source[1]-> map[1]; task2: source[2] -> map[2]
(3)keyby、window、apply等密集型操作,并行度为2,需要做shuffle操作,涉及到slot间数据共享,会在上面的2个solt中分别启用 task3: keyby[1] 和task4: keyby[2] 两个task
(4)sink操作,并行度为1,那么只需要solt1中启用task5: sink[1] 即可,数据汇总做sink操作
(5)那么slot1中含有整个数据pipeline,solt1中有3个task:task1,task3,task5 ;slot2:task2 task4
(6)合理设置算子并行度
3.2.1 并行度
(1)slot是静态的概念,是指taskmanager具有的并发执行能力
(2)parallelism是动态的概念,是指程序运行时实际使用的并发能力,并行度不能大于可用solt数
(3)设置parallelism有多中方式,优先级为api>env>p>file
(4)Flink 集群所需的taskslots数与job中最高的并行度一致
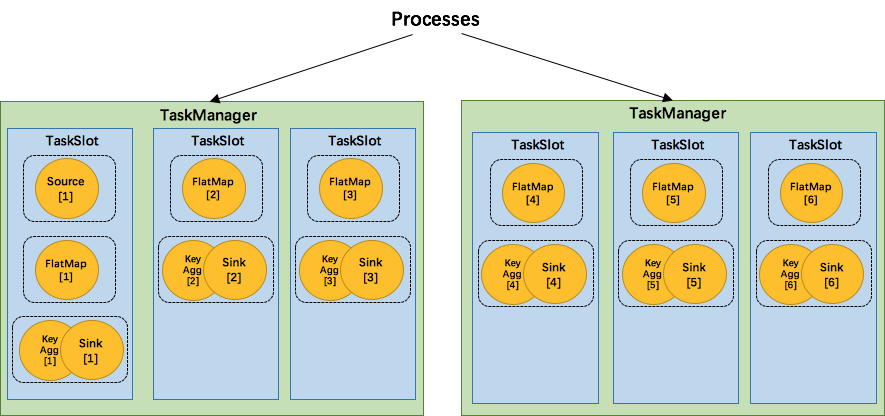
备注:(这个task slot运行图,跟上图中的任务分配不一致仅供理解…)











 京公网安备 11010802041100号
京公网安备 11010802041100号