作者:rert | 来源:互联网 | 2023-08-17 12:10
1、yarn cluster 模式部署介绍
mr和spark都可以基于yarn模式部署,flink也不例外,生产中很多也基于yarn模式部署。
flink的yarn模式部署也分为两种方式,一种是yarn-session,一种是yarn-per-job。大致如下图:
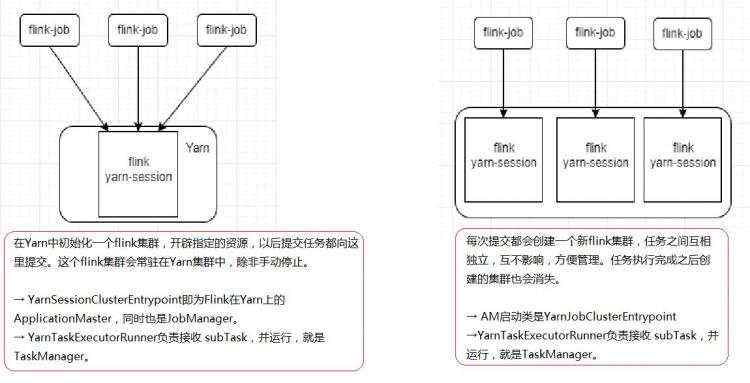
2、flink session HA模式
需要先启动集群,然后在提交作业,接着会向yarn申请一块资源空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交。
适合场景:
当作业很少并且都较小,能快速执行完成时,可以使用。否则一般不会使用该模式。
这种模式,不需要做任何配置,直接将任务提价到yarn集群上面去,我们需要提前启动hdfs以及yarn集群即可。
两个进程:
运行yarn-session的主机上会运行FlinkYarnSessionCli和YarnSessionClusterEntrypoint两个进程。
在yarn-session提交的主机上必然运行FlinkYarnSessionCli,这个进场代表本节点可以命令方式提交job,而且可以不用指定-m参数。
YarnSessionClusterEntrypoint进场代表yarn-session集群入口,实际就是jobmanager节点,也是yarn的ApplicationMaster节点。
这两个进程可能会出现在同一节点上,也可能在不同的节点上。
1、配置
[root@hadoop01 flink-1.9.1]# vi ./conf/flink-conf.yaml
追加如下内容:
# flink yarn HA settings
high-availability: zookeeper
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181
high-availability.zookeeper.path.root: /flink_yarn
high-availability.cluster-id: /cluster_flink_yarn
high-availability.storageDir: hdfs://hadoop01:9000/flink_yarn/recovery
hadoop02 和 hadoop03分别做如上的配置。
2、启动flink session
先确保zookeeper、hdfs、yarn是启动okay。
[root@hadoop01 flink-1.9.1]# yarn-session.sh -n 3 -jm 1024 -tm 1024
...................................
2020-04-14 11:52:59,248 INFO org.apache.flink.shaded.curator.org.apache.curator.framework.state.ConnectionStateManager - State change: CONNECTED
2020-04-14 11:52:59,753 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on hadoop02:41674 with leader id 04caacdd-23c6-4e79-acd5-6db3b1014be0.
JobManager Web Interface: http://hadoop02:8081 ##代表jobmanager启动到hadoop02
报错:
Diagnostics: Container [pid=9528,containerID=container_1586835850522_0001_03_000001] is running beyond virtual memory limits. Current usage: 316.1 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
解决方法:
在hadoop01、hadoop02、hadoop03中的yarn-site.xml中配置如下:
yarn.nodemanager.vmem-check-enabledfalse
3、环境检测
根据启动的信息可知,flink启动到咯hadoop02,则使用jps测试一下:
jps检测进程:
[root@hadoop02 flink-1.9.1]# jps
8992 DataNode
9985 YarnSessionClusterEntrypoint
web页面查看:http://hadoop02:8081
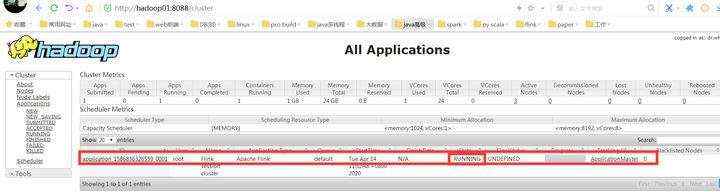
查看yarn的web控制台:http://hadoop01:8088
4、提交作业测试:
提交作业和standalone一样正常提交即可。
[root@hadoop02 flink-1.9.1]# flink run /usr/local/flink-1.9.1/examples/batch/WordCount.jar --input /home/words --output /home/out/fl01
Starting execution of program
Program execution finished
Job with JobID c3fd22587744bc54a6d69af6573a3183 has finished.
Job Runtime: 20642 ms
5、HA切换检测
杀死YarnSessionClusterEntrypoint服务,,看看还能不能在集群中找到该服务。
[root@hadoop02 flink-1.9.1]# jps
8992 DataNode
9985 YarnSessionClusterEntrypoint
8901 QuorumPeerMain
9096 SecondaryNameNode
9720 NodeManager
11210 Jps
#杀死进程造成异常退出
[root@hadoop02 flink-1.9.1]# kill -9 9985
当是HA时,,则一个挂掉后,则JM将会失败转移到另外的服务器上。如下是转移到hadoop01上。
[root@hadoop01 flink-1.9.1]# jps
9408 NameNode
12017 YarnSessionClusterEntrypoint
再次测试job:
[root@hadoop02 flink-1.9.1]# flink run /usr/local/flink-1.9.1/examples/batch/WordCount.jar --input /home/words --output /home/out/fl03
Starting execution of program
Program execution finished
Job with JobID 779689f706af7a9cb05e771a80e89128 has finished.
Job Runtime: 11462 ms
yarn session提交的作业,,在yarn的web平台中看不到。可以通过flink --list来查看。
6、如何停止运行的程序 通过cancel命令进行停止:
flink cancel -s hdfs:///flink/savepoints /savepoints-* -yid application_1586836326559_0002
或者通过 flink list 获得 jobId
flink list
flink cancel -s hdfs:///flink/savepoints/savepoint-* jobId
其中-s为可选操作
7、关闭jobmanager
直接将yarn-session停止掉:
yarn application -kill applicationId
3、flink-per-job模式
yarn session需要先启动一个集群,然后在提交作业。
但是Flink-per-job直接提交作业即可,不需要额外的去启动一个flink-session集群。直接提交作业,即可完成Flink作业。
适合场景:
作业多、且每个作业运行时长不定。生产推荐使用该模式运行作业。
1、直接使用flink run运行即可
[root@hadoop01 flink-1.9.1]# flink run -m yarn-cluster /usr/local/flink-1.9.1/examples/batch/WordCount.jar --input /home/words --output /home/out/fl05
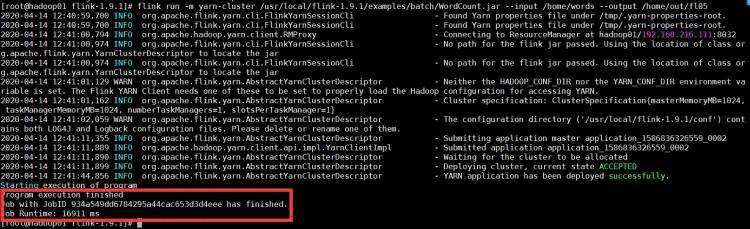
查看yarn的web平台:








 京公网安备 11010802041100号
京公网安备 11010802041100号