如今在万物互联(IoT)兴起的推动下,时间序列数据(衡量事物随时间变化的数据)应用和场景激增,是增长最快的数据类型之一,比如监控指标数据,传感器数据,日志,财务分析等等;时间序列数据具有特定的特征,例如通常以时间顺序形式出现,数据只能附加,并且查询总是在一个时间间隔内进行。虽然关系数据库可以存储这些数据,但是它们在处理这些数据时效率低下,因为它们缺乏优化,例如按时间间隔存储和检索数据。在这个时序数据库项目列表页有超 50种方案,比如 Apache Kudu/Cassandra,ClickHouse, Druid, EasticSearch, HBase, InfluxDB,Prometheus,TimescaleDB,Amazon Redshift/Timestream(预览),Google BigQuery,Facebook Scuba 等等;
很多上规模的客户在时序数据的摄入(Ingest)、分析和成本方面都会遇到很多挑战,本文我们先尝试理解下时序数据的特殊性和数据库选型问题。
关系数据库(OLTP)的出现是为了解决交易事务问题,比如电商订单,支付等场景,也就是数据表的事务更新,比如转账交易,用户从一个账号转出,而在另外一个账户入账;这对应数据库两行甚至两个字段的更新;由于任何两个账号之间都可能发生转账,因此这些记录在磁盘上随机分布;再让我们看看时序数据的场景:
虚拟机/容器/应用监控数据:系统通常会收集不同服务器、容器或应用的度量值,比如 CPU 利用率,可用内存,可用磁盘,网络传输字节总量,每秒请求数等等,每个指标都关联相关的时间戳,服务器 ID,和一组描述所收集内容的属性;
{ “name”: “server.requestCount”, “status”: “200”, “endpoint”: “api”, “nf.app”: “fooserver”, “nf.cluster”: “fooserver-main”, “nf.stack”: “main”, “nf.region”: “us-east-1”, “nf.zone”: “us-east-1c”, “nf.node”: “i-12345678” }
传感器数据:每个设备可以在每个时间段报告多个传感器读数;例如对于空气和环境质量检测,可能包含,温度、湿度、气压、有害物质、颗粒物等等的测量值;每组数据都与时间戳、唯一设备ID相关联,并且可能有其他元数据。
证券行情数据:用时间戳的信息流表示,包含证券代码,当前价格,价格变化等等
车队/资产管理:数据包含车辆/资产ID,时间戳,GPS 坐标,及可能的元数据
以上所有的场景,数据集都是连续的测量值,不断产生“新数据”插入到数据库,虽然由于网络延迟,可能存在数据到达后端的时候,比数据生成标记的时间戳要晚很多,不过这种情况属于异常情况,发生频率比较少;
对比来看,OLTP事务处理的数据写入和时序数据的写入有很大差异:
| OLTP事务写入 | 时序数据写入 |
|---|---|
| 主要是更新 | 主要是插入 |
| 数据随机分布 | 热点集中在最新的时间段数据 |
| 通常是基于主键的事务操作 | 除了时间戳之外,还关联其他主键比如服务器ID,设备ID,账号ID,设备ID等等 |
时序数据堆积非常迅速,而通常关系数据库无法很好的扩展,因此,大多数开发人员选择时序数据库倾向于扩展性更好的 NoSQL 方案。
摘自 TimescaleDB 团队对 PostgreSQL 插入性能测试,可以看出数据插入吞吐量随着表数据量的增加而下降,该测试基于 PostgreSQL 9.6.2 版本,SSD 磁盘,8 vCPU 存储优化云主机,客户端每次插入一行数据,包含12列:时间戳,随机主ID和10个其他指标数据);PostrgreSQL 开始以 15K每秒的速度插入,但随后在 50M 行后开始明显下降,性能变化差异巨大,有时仅仅 100次每秒插入性能;
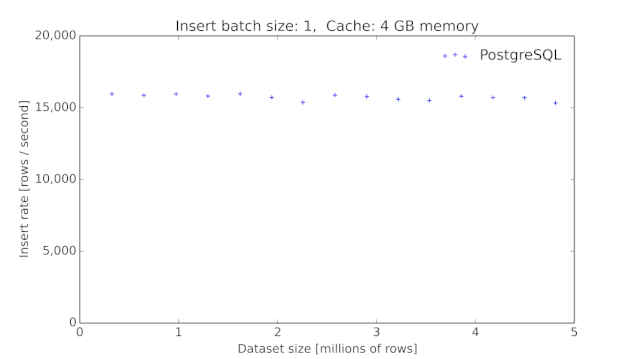
这通常由关系数据库的特性决定的,关系数据库在磁盘上利用数据页来保存数据,比如 8KB大小单位,基于数据页,数据库系统构建数据结构比如 B+树,来快速索引和访问数据,利用索引,SQL 查询比如通过身份证ID 可以快速定位到磁盘上的数据,避免扫描整个数据表;如果整个索引比较小,可以全部放入内存操作,那性能非常好,但如果如果内存无法容纳所有的 B+树,更新树的一个随机部分,可能会导致严重影响性能的磁盘 I/O 操作,数据库系统需要从磁盘读取数据页到内存,在内存中更新,再写回磁盘;因此由于数据库系统以数据页为单位访问磁盘,哪怕很小的数据更新,都可能导致比如 8KB 大小的内存和磁盘的多次数据交换;
新型的 NoSQL 数据库比如 LevelDB、Cassandra,InfluxDB 等,为了避免低效的基于磁盘的 B+树索引数据结构(双倍的磁盘 I/O操作),引入了一种新型基于磁盘的 LSM(Log-Structure Merge)树结构,有效降低维护一个实时索引树的代价,提高了数据插入和删除效率,比较适合插入多于查询的场景比如历史记录表,日志表或时序数据;LSM 的优化逻辑是,减少碎片小数据写入操作,仅仅执行较大数据集及磁盘追加写入;与 B+数”就地“写入不一样,LSM 树将最近的更新包括删除操作排入内存队列(Sorted String Table-SSTable),当数据量足够大的时候,批量写回磁盘,这样就降低了磁盘 I/O 的成本;但 LSM 也引入一些弊端:
更多内存需求:与 B+树不一样,LSM 树没有一个全局的排序树,因此基于个 Key 值进行一次查询变得复杂,首先,要检查内存中的 SSTable 是否有该 Key的最新值,否则还需要查询磁盘上的数据来定位到最新的 Key对应的数值;为了避免过多的磁盘 I/O 操作,所有的 SSTable的索引需要保存在内存中,这又增加了内存的需求;
二级索引不支持:由于缺乏全局顺序,因此 LSM 树结构不支持二级索引;不同的系统做了一些变通,比如冗余复制一份数据但以不同的顺序存储,或者将主键构建为多个值的”串接“,等等;
InfluxDB 是由 InfluxData 创建的,一个定制的、开源、 NoSQL 架构的时序数据库解决方案,基于 Go 语言开发,提供了一个类似 SQL 的查询语言 InfluxQL,同时也提供了一个定制的查询语言 Flux,从官方文档来解读这两者的差异,InfluxQL主要提供用户类似 SQL 的语法和InfluxDB进行交互,而 Flux 更加强大,基于函数语言范式,提供更强大的数据分析能力:
InfluxQL 查询语句样例:
> SELECT "level description"::field,"location"::tag,"water_level"::field FROM "h2o_feet"name: h2o_feet--------------time level description location water_level2015-08-18T00:00:00Z below 3 feet santa_monica 2.0642015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12[...]2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.0662015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
Flux 查询样例,其中的 NOAA 数据集可以从这里下载:
from(bucket: “NOAA”) |> range(start: 2015-08-01T00:00:00Z, stop: 2015-10-01T00:00:00Z) |> filter(fn: (r) => r._measurement == "h2o_feet" and r._field == "water_level") |> aggregateWindow(every: 1mo, fn: mean)
在 InfluxDB 中任何一个度量值都包含一个时间戳,以及相关联的若干属性和标签(tag),属性表达真正的度量值并且只能是 floats,ints,strings 和布尔值类型;标签表达度量的元数据,标签数据都会被索引,而且不可更改。InfluxDB 非常容易上手,因为系统自动帮助用户创建表 Schema 和索引,但同时又有很多限制,比如无法创建额外的索引,一旦创建就无法更新标签值;
TimescaleDB 是底层基于关系数据库 PostgreSQL,针对时序数据特性进行改良,提升了数据插入性能,因此原生完整支持 SQL 语法,因此对于熟悉关系数据库技术的人而言,没有任何学习曲线,同时可以利用 PG 的很多工具支持数据备份恢复,高可用等特性:在 TimescaleDB 中,每一条数据都拥有一个时间戳,关联任意多个其他字段,可以是 PG 支持的任意数据类型,同时用户可以基于某个字段或者组合字段构建索引,如果要保存元数据,可以利用外键创建一个新的元数据表。因此你需要预先设计你的表结构及索引。
-- Information about each 15-min period for each location-- over the past 3 hours, ordered by time and temperatureSELECT time_bucket('15 minutes', time) AS fifteen_min, location, COUNT(*), MAX(temperature) AS max_temp, MAX(humidity) AS max_hum FROM conditions WHERE time > NOW() - interval '3 hours' GROUP BY fifteen_min, location ORDER BY fifteen_min DESC, max_temp DESC;
时序数据库的选择考虑的点很多,主要包括:
数据模型
查询语言
可靠性
性能
开发者和工具链生态
运维支撑
商业和社区支持
数据库是基于特定场景优化的,选择什么样的数据模型,以及如何存储,决定了后续你可以如何操作这些数据。如上的两个典型时序数据库就是完全不同的数据模型,一个延续了关系数据库数据模型,一种是如 InfluxDB ,自定义数据模型。
关系数据库的数据模型大家都很熟悉,用在时序数据上,如 TimescaleDB 下图的数据结构,每一条时序数据存储一行,优势是(1)支持宽表还有窄表,根据时序数据字段和元数据数量(2)自定义索引加速查询(3)度量数据和元数据分离存储在不同的表中(4)数据值类型校验或者利用 JSON blob 存储 Schemaless 数据;缺点是事先要规划表结构和索引:
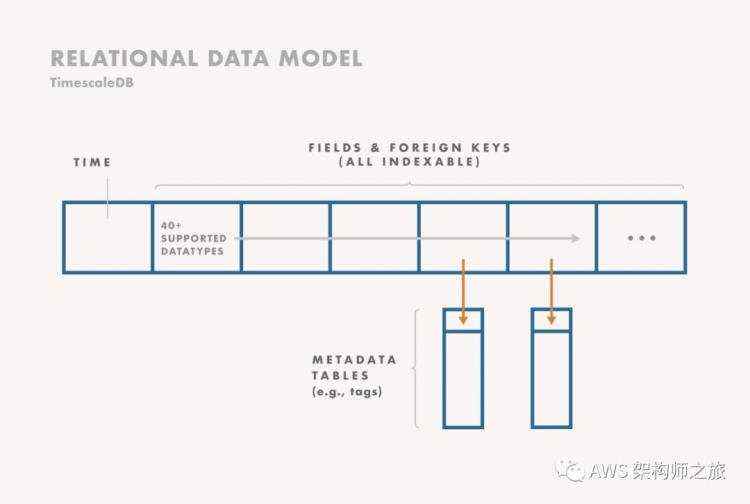
(图片来自 https://dwz.cn/KCEmDmVY)
而 InfluxDB 的数据模型是自定义的,一个度量包含一个时间戳,和若干标签(自动索引,无法更新)、若干字段(度量值),如果时序数据完全切合该结构,使用起来非常方便;虽然看起来不需要定义数据结构,但本质上它自动根据数据创建了 Schema,所以不属于 Schemaless 数据库;另外如果有需要额外索引,或在连续值字段比如数值型字段创建索引都是不支持的;
比如 temperature,machine=unit42,type=assembly internal=32,external=100 1434055562000000035 其中度量是 temperature, 元数据即标签数据是 machine=unit42,type=assembly,度量值有,internal=32,external=100;一个 InfluxDB 的数据库是包含用户,数据保留策略(数据保留多久,自动清除过期数据;以及集群模式下需要几份复制)以及具体的度量条目;同样的数据保留策略,度量和标签数据归属于一个时序数据集(series); InfluexDB 的持久化策略和关系数据库类似,基于 WAL 日志,同时保留近期数据在内存中以 TSM 格式存储,TSM 基于 LSM 树结构,所以兼顾到数据持久化到磁盘以及近期数据查询的性能(缓存在内存);
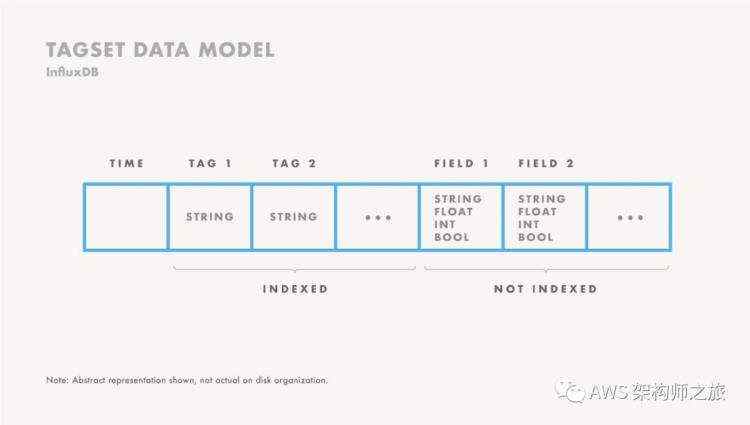 (图片来自 https://dwz.cn/KCEmDmVY)
(图片来自 https://dwz.cn/KCEmDmVY)
| 时序数据库 | 数据模型 |
|---|---|
| TimescaleDB | SQL 数据模型 |
| Influx DB | 度量,标签(索引),度量值(字段) |
| Prometheus | 度量,标签(Labels) |
| Druid | 度量,标签(Labels) |
| Elasticsearch | 度量,标签(Labels) |

(图片来自 https://dwz.cn/KCEmDmVY)
通常时序数据库提供的查询接口两个极端,一端是 SQL,另外一个极端是 NoSQL(全新的查询分析方法),取折衷方案就是类 SQL 查询语言;对于绝大多数客户而言,原生 SQL 语言支持是比较合适的一种选择,SQL 有广泛的基础和生态工具支撑,采用和学习一个全新的查询语言需要团队衡量学习成本和收益。
| 时序数据库 | 支持的查询语言 |
|---|---|
| TimescaleDB | SQL |
| Influx DB | InfluxSQL 和 Flux |
| Prometheus | PromQL |
| Druid(4) | JSON style Query Language. |
| Elasticsearch | JSON style Query Language. |
对于一个数据库而言,可靠性意味着,你的数据不容丢失或者损坏。InfluxDB 是一个基于 GO 语言构建的全新的时序数据库引擎,早期版本底层存储支持可插拔的多种开源引擎 LevelDB,RocksDB,等等,但 2015年底,InfluxDB团队决定重写一个优化的存储引擎,支持数据压缩,列式存储,并引入了 Facebook 的 Gorilla 编码等特性,极大了减少了[存储开销](https://www.influxdata.com/blog/new-storage-engine-time-structured-merge-tree/)最多 98%的节约相对于 0.9.4版本引擎。InfluxDB 是一个无服务器架构的新式数据库系统,在生产级关键应用场景,还需要经过时间和规模的长期考验。InfluxDB 的所有工具都是从头开始构建,比如开源版本一开始支持数据库复制和高可用,不过很快就被移到企业版,开源版不再可用,它的备份工具支持全量备份和按时间点恢复,但增量备份需要很多手工操作。
相对而言,TimescaleDB 只是扩展了 PostgreSQL 数据库,并没有重复造轮子,该数据库经历了 25年多的社区发展和实际案例应用,被验证可用在高可靠要求的应用程序场景,围绕 PG 的生态和工具集也是非常丰富。
TSDB 时序数据库的测试可以借助于开源工具比如
https://github.com/timescale/tsbs
https://github.com/influxdata/influxdb-comparisons
网上也有不少性能对比测试的结果 比如:https://severalnines.com/database-blog/which-time-series-database-better-timescaledb-vs-influxdb
| 时序数据库 | 性能(单节点写入,参考值) | 参考文档 |
|---|---|---|
| TimescaleDB | 300k~2.5M/Second | https://dwz.cn/KCEmDmVY |
| Influx DB | 470K/second | https://www.influxdata.com/blog/influxdb-vs-cassandra-time-series/ |
| Prometheus | 200K/second | https://fabxc.org/tsdb/ |
| Druid | 200~800K/second | http://static.druid.io/docs/druid.pdf |
| Elasticsearch | 458K/second | https://dwz.cn/G3ep4Sf8 |







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有