
本文转载自:华为云社区
86万张表迁移的优化历程问题背景:2019年12月份的时候DRS项目组接到了一个线上问题:XX客户将mysql数据库从友商迁移至华为云的时候性能很慢,而且出现报错。运维同学定位发现用户的某几个实例存在大约2000个库,86万张表,而出错的原因是查询源库数据库超时。和开发同学联系后得到了第一个解决方案:增大和源库的socketTimeout值,保证查询不超时。然而,运维同学在后续保障的过程中发现……
01
86万张表迁移的优化历程
2019年12月份的时候DRS项目组接到了一个线上问题:XX客户将mysql数据库从友商迁移至华为云的时候性能很慢,而且出现报错。运维同学定位发现用户的某几个实例存在大约2000个库,86万张表,而出错的原因是查询源库数据库超时。和开发同学联系后得到了第一个解决方案:增大和源库的socketTimeout值,保证查询不超时。然而,运维同学在后续保障的过程中发现超时问题得以解决但是性能无法保证,而且容易出现OOM问题。客户要求在一天内要完成割接,然而我们目前的迁移时间远超24个小时,由于项目的进度问题,留给DRS的时间只剩一个周末。
02
问题定位过程
饭要一口口吃,问题也得一个个定位,回到最初的超时问题,我们首先找到了出现超时的sql语句:
SELECT TRIGGER_NAME FROM information_schema.TRIGGERS WHERE TRIGGER_SCHEMA = '****';
这个sql用于查询每个库下面的所有触发器(其他对象的查询sql也有这个问题),我们发现这个sql执行了超过5分钟,这个结果令我们很意外。因为理论上而言只查询一个库下面的所有触发器,怎么会这么慢呢?explain这个sql我们发现:

Extra中表示Scanned all databases!!!这意味着虽然我们只是在查询一个库下面的触发器,但是其实它会扫描所有库对应的frm文件。DEBUG了一下mysql的源码,我们发现虽然只是查询了一个库下面的trigger,但是由于information_schema.triggers表里面并不是一张物理表,导致每次查询都会去打开所有的frm文件,我们知道frm文件是用来存放mysql元数据信息的物理文件,对于用户这个表数量,可想而知这个会对用户的源库IO造成多大的影响,即使有buffer pool也扛不住这么多表的缓存。更关键的是,用户有2000个库,也就是说单就查询trigger这一个对象,我们就需要耗费2000*5=10000分钟的时间,迁移性能可想而知。
有了上面的结果,其实采取的优化方式很简单了。首先,我们根据对象的类型来区分查询所有对象的方式,对于表,我们可以使用逐库查询,因为查询表的操作不会Scanned all databases;对于其他对象,我们使用只查询一次的sql:
SELECT TRIGGER_SCHEMA, TRIGGER_NAME FROM information_schema.TRIGGERS WHERE TRIGGER_SCHEMA NOT in('mysql','information_schema','sys', 'performance_schema');
这样我们的查询时间大大缩短!
然而,现实是残酷的,虽然我们缩短了从源库查询对象列表的时间,但是导出对象到回放对象的性能还是不够出色,不能满足用户的12小时时间限制,此外偶发的OOM问题也随之没有解决。
03
OOM问题
用MAT分析了heap堆存储后发现,heap里面存在大量的DbSqlData类的对象,正是大量的这种对象导致堆内存溢出。结合我们的架构可以发现,我们在导出表结构的时候会先把所有对象结构分类型存储在ehcache中,然后在读取的时候又会把数据按类型导出到内存中。针对用户的场景,我们可以计算出(用户的表结构平均占用堆内存4000Byte)86万张表总共需要3.44G,而我们的永久代内存只配置了2G,OOM问题可想而知。
if [ -z "$REPLICATOR_HEAP_SIZE" ]; then
REPLICATOR_HEAP_SIZE="-Xms3072m -Xmx3072m -XX:NewRatio=3 -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m"
fi
其实这一切的问题来源都是因为我们按对象类型对ehcache进行存取,这种方式不是流式进行的,很有可能发生OOM问题。因此,解决的思路就是我们按照单个对象的粒度进行存取,并且使用内存控制的方式控制读到堆内的对象数目,保证流式结构的回放,如何进行流式结构的回放将会在下面介绍。
04
性能问题
为了满足客户的迁移时间需求,我们统计了各个阶段DRS内核的工作时间,大致分为下面几个阶段:
这三个阶段的执行顺序是串行执行的,其中查询对象列表花了共计1个小时,导出对象结构共计10个小时,回放共计8个小时,总计19个小时。这个结果远远超出了客户的预期,为了解决这个问题,我们对整个迁移流程进行了重新梳理,发现有以下2个改进点:
1.查询对象列表的同时可以将已查询对象列表的结构导出2.导出对象结构可以由单线程导出演进为多线程并发导出按照上述优化流程,假定查询对象列表时间为A,单线程导出结构所需时间为B,根据CPU核数/IO线程比我们设定导出结构的线程数为8,在源库性能足够的情形下,查询对象列表+导出对象结构的时间应该等于
CostTime(hour)=max(A, B/8) —— 约等于2
这样我们的总时间为2 + 8 = 10小时,满足客户的需求!
有了上面的分析,结合OOM问题和查询时间优化的思路,我们有了以下的设计:
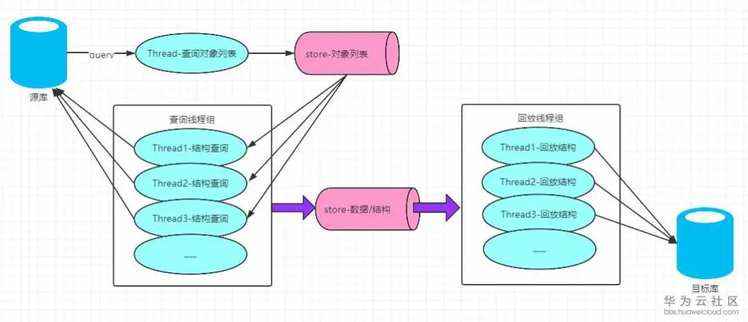
上面图略去了数据的回放模型,主要突出了结构的回放,同时在两个store中加入了内存控制,防止出现OOM问题。
05
优化结果
在通宵达旦的开发和验证后,我们终于构建了以上的框架,并且成功将86万张表的总时长优化到了10小时以内,更为可喜的是整个流程中的full gc次数为0,最终客户的需求得以实现,技术人员也从中学习到了新的知识。
优化是无止境的,其实上述的架构还存在优化空间,比如以下的两点:
1.结构的导入和数据的回放可以并行执行,针对用户表多数据少的场景,统计发现表结构的导入花了4个小时而数据的导入也只花了4个小时,这一个阶段可以优化(DRS已经做了这个优化,会在后续的博客中给大家科普实现方式)2.结构的导出和结构回放是否可以并行执行,他们之间的限制关系是什么?如果有小伙伴对我们的架构有看法也可以积极留言,我们会去认真观摩!

↓点击







 京公网安备 11010802041100号
京公网安备 11010802041100号