参考资料:
- https://davidlovezoe.club/wordpress/archives/1122#BPF%E7%A4%BE%E5%8C%BA%E5%92%8C%E7%94%9F%E6%80%81
- 《A thorough introduction to eBPF》
- https://davidlovezoe.club/wordpress/archives/874
- https://davidlovezoe.club/wordpress/archives/988
- 极客时间《eBPF核心技术与实战》
- https://zhuanlan.zhihu.com/p/44922656
- https://www.ebpf.top/post/ebpf-overview-part-3/
- 《BPF之巅-洞悉linux系统和应用性能》
在学习eBPF基础之前的基础
gcc、llvm、clang等是什么?编译器分为三个:
frontEnd :词法和语法分析,将源代码转换为抽象语法树Optimizer: 在前端的基础上,对中间代码进行优化backEnd:将优化后的中间代码转化为各自平台的机器码GCC、llvm、clang
GCC: GNU Compiler Collection,GNU编译器套装,是一套由 GNU 开发的编程语言编译器,最先支持C语言,后来演进可处理 C++、Fortran、Pascal、Objective-C、Java等语言
llvm:Low Level Virtual Machine, 可用作多种编译器的后端使用(能够让程序语言的编译器优化、链接优化等),支持任何编程语言的静态和动态编译,可以使用它编写自己的编译器
LLVM的命名最早源自于底层虚拟机(
Low Level Virtual Machine)的首字母缩写,由于这个项目的范围并不局限于创建一个虚拟机,这个缩写导致了广泛的疑惑。LLVM开始成长之后,成为众多编译工具及低端工具技术的统称,使得这个名字变得更不贴切,开发者因而决定放弃这个缩写的意涵,现今LLVM已单纯成为一个品牌,适用于LLVM下的所有项目
clang:clang是llvm的前端,可以用来编译c、c++、ObjectiveC等语言,其以llvm作为后端支持,高效易用,并且与IDE有很好的结合
.elf对象文件处于程序编译的什么阶段?可执行与可链接格式 (英语:Executable and Linkable Format,缩写 ELF,此前的写法是 Extensible Linking Format),常被称为 ELF格式,在计算中,是一种用于可执行文件、目标代码、共享库和核心转储(core dump)的标准文件格式。
编译:
高级语言 -> 汇编语言 -> 机器语言 : 高级语言最终变为机器语言这样的过程可以统称为编译,具体的方法基本有两种:编译型和解释型
据此也可分为两大类:一种是编译型语言,例如C,C++,Java,另一种是解释型语言,例如Python、Ruby、MATLAB 、Javascript
四个步骤:
预处理(Preprocessing)
编译(Compilation)
汇编(Assembly)
链接(Linking)

.so文件:动态链接库,也称为共享库, 不能直接运行
BPF基础和技术储备监控内容:监控内核空间运行的数据(数据包), 抓取和过滤符合特定规则的网络包
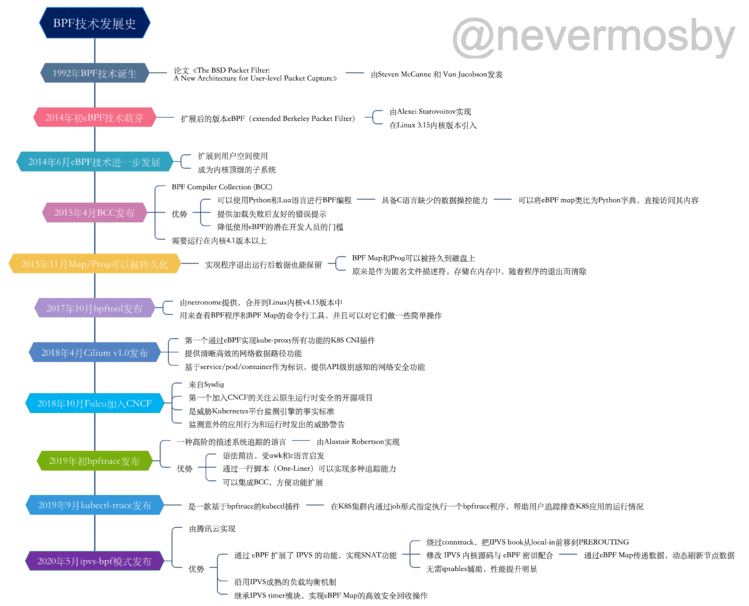
发展历程:

发展原因:
Brendan Gregg,他在2017年的linux.conf.au大会上的演讲提到「内核虚拟机eBPF」,表示,“超能力终于来到了Linux操作系统“
因此,Alexei Starovoitov为了更好地利用的现代硬件,提出了扩展型BPF(eBPF)设计。eBPF虚拟机更类似于现代的处理器,允许eBPF指令映射到更贴近硬件的ISA以获得更好的性能
详细完整的历程:
Berkeley Packet Filter 伯克利包过滤器,在伯克利大学诞生,为BSD操作系统而开发,后来一直沿用
原始的BPF是设计用来抓取和过滤符合特定规则的网络包, 过滤器是通过程序实现的(用户定义过滤器表达式),并在基于寄存器的虚拟机上运行,使得包过滤直接在内核中执行,避免向用户态复制
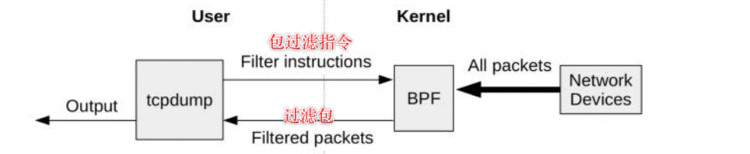
基本原理是BPF提供了一种在内核事件和用户程序事件发生时,安全注入代码的机制(运行一小段程序的机制), 这样就让非内核开发人员也可以对内核进行监控和控制
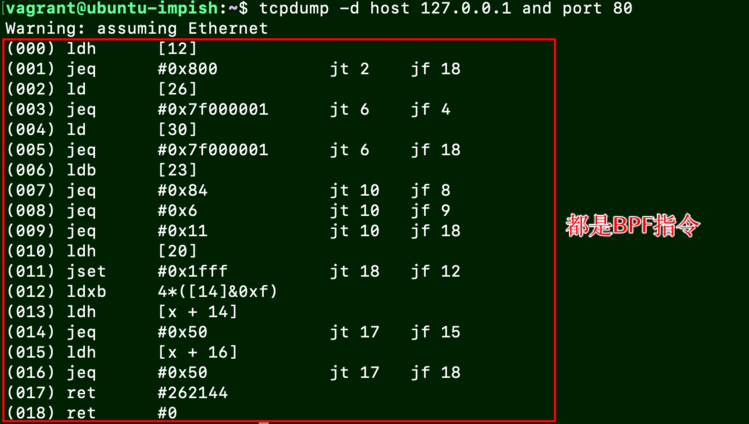
著名的
tcpdump就是基于此实现:
extend Berkeley Packet Filter 拓展BPF, 它演进成为了一套通用执行引擎
BPF的功能升级版,Alexei Starovoitov为了更好地利用的现代硬件,提出了扩展型BPF(eBPF)设计
eBPF的基本架构在于:借助即时编译器JIT,在内核中运行了一个执行引擎(因为编译后直接在cpu上运行,所以相比虚拟机可能执行引擎更为合适),被验证安全的eBPF指令最终都会被内核执行
- 老版本的
Berkeley Packet Filter目前称为cBPF:classic BPF,目前基本废弃,新的Linux内核只运行eBPF, 内核会将cBPF透明的转换为eBPF- 特别的,当前
cBPF和eBPF都统称为BPF了,或者说提到BPF不做特殊说明就是eBPF,BPF应该看作是一个技术名词而不是单纯的缩写(或者说包过滤器了)
二者比较

速度更快
更贴近硬件的指令集架构ISA,特别是适应64位寄存器以及提升使用的寄存器数量(从2个提升到10个),这样有助于即时编译提高性能;此外eBPF的指令仍然运行在内核中, 不需要向用户态复制数据(也是BPF拥有的),提高了事件处理效率。
对于某些网络过滤器微基准测试上显示,
eBPF在x86-64架构上的速度比旧的经典BPF(cBPF)实现最高快四倍,大多数都在1.5倍
支持使用一些受限的系统调用
BPF_CALL指令,可以更廉价地调用内核函数拓展性
功能从包过滤拓展到更多(跟踪过滤、链路追踪、可观测)
2014年的daedfb22451d这次代码提交中,eBPF虚拟机直接暴露给了用户空间来调用(或者说运行用户空间代码)
eBPF怎样感知代码?
eBPF的指定的代码路径中,当代码路径被遍历到时,任何附加的eBPF代码都会被执行能够做什么?
网络数据包/流量的过滤转发
通过编写程序实现对网络数据包/流量的过滤分发,甚至是修改socket的设置
实例:
- XDP这个项目就是专门使用eBPF来执行高性能数据包处理,方法是在收到数据包之后,立即在网络栈的最低层执行eBPF程式
- seccomp BPF实现了限制一个进程的系统调用方法的使用
调试内核/性能分析
程序可以添加跟踪点、kprobes和perf事件; 对于实时运行的系统,可以不重新编译内核而实现编写和测试新的调试代码
甚至可以使用
eBPF通过「用户空间静态定义的跟踪点」来调试用户空间程序
如果允许用户空间代码在内核中运行,eBPF如何保证安全性?
eBPF分为两个阶段的检查: eBPF程序之前 eBPF终止时不包含任何可能导致内核锁定的循环逻辑(就是不能有循环),通过程序控制流图CFG来实现eBPF程序,每执行完一次指令就在指令执行之前和之后检查虚拟机的状态,确保寄存器和堆栈状态的有效性,禁止越界跳转和越界数据访问eBPF验证器会智能的检测出已经检查过程序的子集,从而裁剪分支跳过模拟验证的过程CAP_SYS_ADMIN特权加载eBPF程序的时候就会进入安全模式,安全模式下会确保内核地址不会泄露给没有特权的用户,并且指针不能写入到内存eBPF程序类型**(后面将介绍)来限制可以从eBPF程序调用哪些内核函数以及可以访问哪些数据结构BPF虚拟机的内部架构
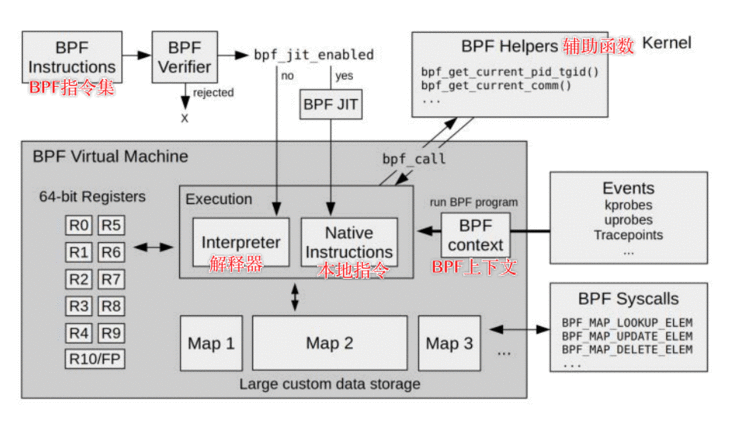
下面就是整个eBPF程序的工作流程图:
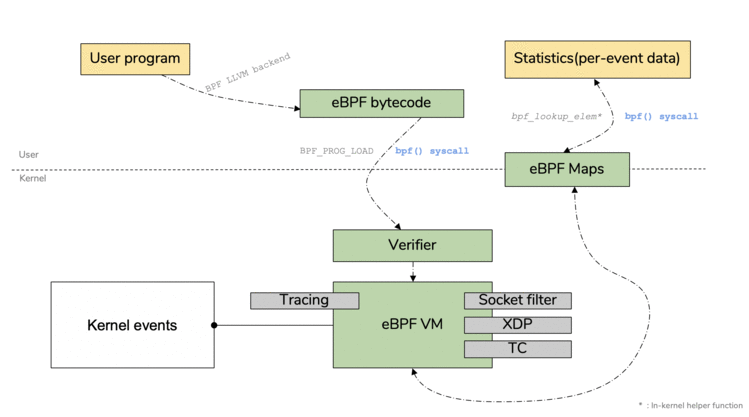
或者是这张图:
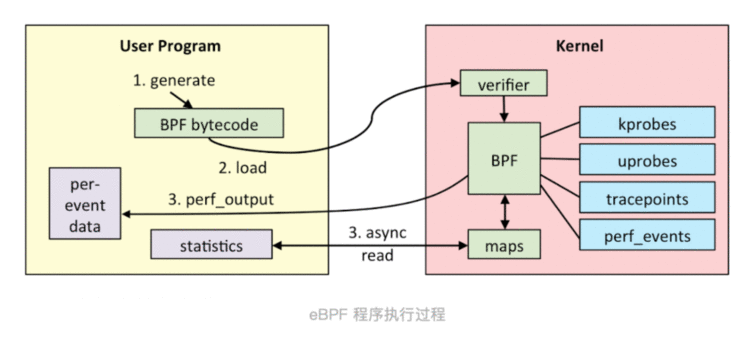
整体的流程可以总结为:
llvm将程序编译为eBPF字节码bpf系统调用交给内核(也叫load加载)插桩是什么?
具体的事件源:
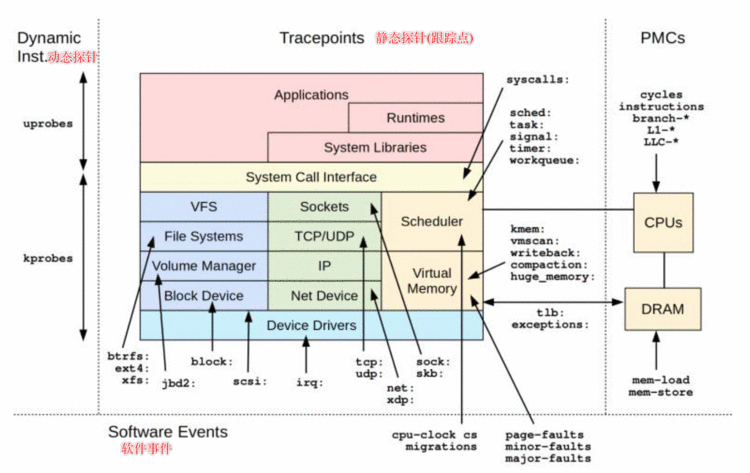
具体类型?
动态插桩:对正在运行的软件插入观测点的能力;如果软件未启动,那么动态插桩的开销为0;具体插桩的位置可以是软件栈中所有函数中任一个
与debugger调试器的区别?
动态插桩有两种探针:
内核态插桩kprobes
可以对任意内核函数进行插桩,还可以对内部指令进行插桩,可以在实时生产环境中使用无需重启系统或内核
kretprobes: 对内核函数返回时进行插桩以获取返回值;两者配合可以用来计算函数执行时间
上层追踪器/前端的使用
BCC : attach_kprobe()和attach_kretprobe()bpftrace: kprobe和kretprobe探针类型BCC的kprobe支持函数开始以及某一偏移量放置探针,而bpftrace只支持函数开始位置插桩用户态插桩uprobes
kprobes,但是是对用户态程序BCC : attach_uprobe()和attach_uretprobe()bpftrace: uprobe和uretprobe探针类型BCC的uprobe支持函数开始以及某一偏移量放置探针,而bpftrace只支持函数开始位置插桩
缺点:
为了解决动态插桩的问题,出现了静态插桩,静态插桩会将稳定的事件名字编码到软件代码中,由开发者维护
具体有两种:
tracepoint(内核跟踪点)
kprobes, 因为前者更加稳定<子系统>:<事件名>BCC : TRACEPOINT_PROBE()bpftrace&#xff1a;跟踪点探针类型BPF_RAW_TRACEPOINT: 避免一些没必要的参数传递&#xff0c;提高性能 (比kprobes稳定&#xff0c;因为其探针函数名是稳定的&#xff0c;参数可能是不稳定的)USDT(用户态静态定义跟踪插桩技术 user-level statically defined tracing)
用户空间版的跟踪点机制
依赖于外部系统跟踪器唤起&#xff0c;如果没有&#xff0c;应用中的USDT也不会做任何事 (不用担心写在源代码中的探针会带来性能开销&#xff0c;如果外部没启用&#xff0c;那么该代码会被直接跳过)
上层追踪器/前端的使用
BCC : USDT().enable_probe()bpftrace&#xff1a;USDT探针类型动态USDT:
USDT直接编译到二进制文件中&#xff0c;而对于动态编译型语言(运行时编译&#xff0c;例如java/jvm)&#xff0c;动态USDT就起作用了JVM 已经内置在C&#43;&#43;代码库中许多动态USDT探针, 包括GC、类加载等&#xff1b;但是java这种依靠JIT即时编译的方式难以使用动态USDT&#xff08;因为动态USDT是一个动态链接库&#xff0c;需要提前编译好、带一个包含了探针描述的notes的ELF文件&#xff09;
缺点&#xff1a;增加维护成本&#xff0c;数量一般较少
动态插桩、静态插桩的基本原理将在后续介绍
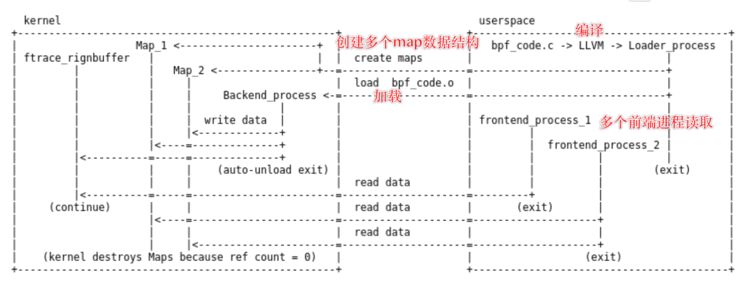
map又称为映射&#xff0c;BPF程序可以利用其进行存储
核心职责&#xff1a;存储eBPF运行时状态即用户程序与运行在内核的eBPF程序交互载体
运行在内核的eBPF程序收集目标状态存储在map中&#xff0c;随后用户程序再从映射中读取这些状态
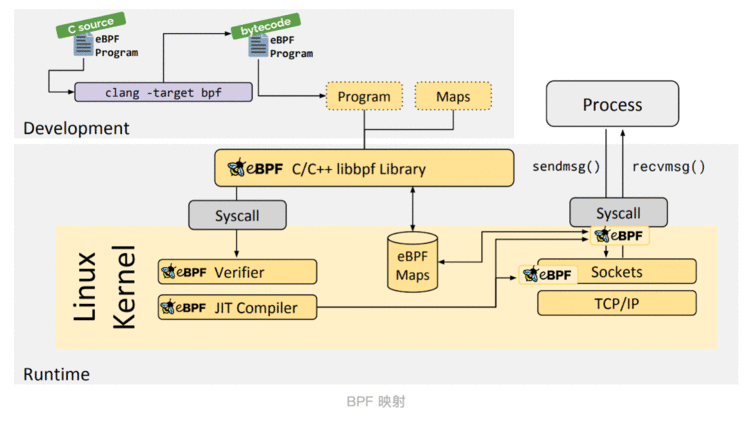
保证安全性就意味着限制&#xff0c;所以eBPF并不是万能的
具体的限制包括&#xff1a;
eBPF程序栈最大只有512字节&#xff0c;需要更大的存储要借助映射存储具体内核版本要求和函数功能支持见&#xff1a;https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
eBPF程序编写的整体的组织架构&#xff1a;
eBPF 程序可以更加复杂&#xff1a;多个后端可以由一个&#xff08;或单独的多个&#xff09;加载器进程加载&#xff0c;写入多个数据结构&#xff0c;然后由多个前端进程读取&#xff0c;所有这些都可以发生在一个跨越多个进程的用户 eBPF 应用程序中。
llvm、BCC、bpftrace、IOVisor层次架构与比较与之相关的知名工具包括&#xff1a;
层级一&#xff1a;llvm
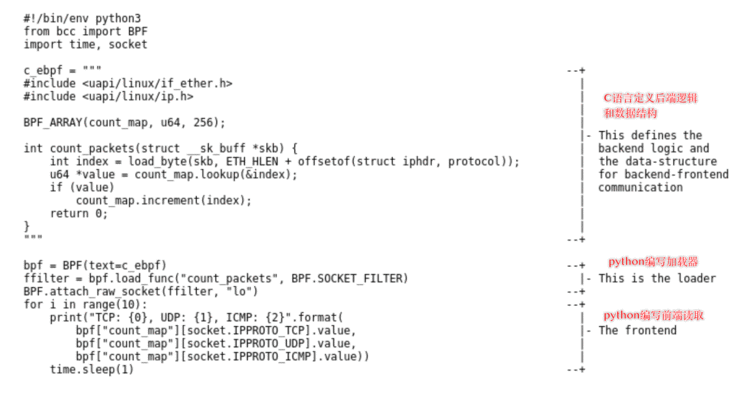
一个编译器&#xff0c;帮助高级语言(c、GO、Rust)的子集被编译成为eBPF字节码程序&#xff1b;将“”受限的C语言“”(符合eBPF验证规范的)编译为ELF对象文件&#xff0c;随后即可通过bpf等系统调用实现加载到内核中&#xff1b;受限的c语言的引入带来的好处是更加容易用高级语言编写&#xff0c;带来的坏处在于加载器程序的复杂性变高(需要解析ELF对象)
层级二&#xff1a;BCC
一个BPF工具链集合&#xff08;libbcc、libbpf的前身&#xff09;, 解决了上述整体四个组织架构之间的整合关系&#xff0c;尽量实现自动化和标准化&#xff0c;其本身组成分为两个部分&#xff1a;
BCC-tools&#xff1a;这是一个不断增长的基于 eBPF 且经过测试的程序集&#xff0c;提供了使用的例子和手册(基于BCC开发的成熟工具)重新定义了组织结构&#xff0c;eBPF 程序组件在BCC组织方式如下&#xff1a;
后端和数据结构&#xff1a;用 “受限制的C语言” 编写(本身也依赖于llvm/clang进行编译成eBPF程序)。可以在单独的文件中&#xff0c;或直接作为多行字符串存储在加载器/前端的脚本中&#xff0c;以方便使用(很多方便的宏定义)。参见&#xff1a;语言参考
加载器和前端&#xff1a;可用非常简单的高级python/lua脚本编写
例如python的BPF(text&#61;&#39;BPF_program&#39;))即可加载BPF字节码到内核, 详细参见&#xff1a;语言参考
层级三&#xff1a;bpftrace
在某些用例中&#xff0c;BCC 仍然过于底层&#xff0c;例如在事件响应中检查系统时&#xff0c;时间至关重要&#xff0c;需要快速做出决定&#xff0c;而编写 python/“限制性 C” 会花费太多时间&#xff0c;因此 BPFtrace 建立在 BCC 之上&#xff0c;通过特定领域语言&#xff08;受 AWK 和C启发实现的一种自定义的高级语言&#xff09;提供更高级别的抽象&#xff0c;根据声明帖&#xff0c;该语言类似于 DTrace 语言实现&#xff0c;也被称为 DTrace 2.0&#xff0c;并提供了良好的介绍和例子。
例如&#xff1a;这个单行 shell 程序统计了每个用户进程系统调用的次数&#xff08;访问内置变量、map 函数 和count()文档获取更多信息&#xff09;
bpftrace -e &#39;tracepoint:raw_syscalls:sys_enter {&#64;[pid, comm] &#61; count();}&#39;
局限性&#xff1a;上层的封装抽象会受限于特殊的功能需求&#xff0c;在某些场景下很难直接用一个bpftrace命令实现&#xff0c;所以还是需要BCC工具
BCC与bpftrace适用场景对比&#xff1a;
BCC: 开发复杂的脚本和作为后台进程使用bpftrace&#xff1a;编写强大的单行程序、短小的脚本使用
层级四&#xff1a;云环境中的eBPF-IOVisor
IOVisor 是 Linux 基金会的一个合作项目&#xff0c;基于本系列文章中介绍的 eBPF 虚拟机和工具。它使用了一些非常高层次的热门概念&#xff0c;如 “通用输入/输出”&#xff0c;专注于向云/数据中心开发人员和用户提供 eBPF 技术。其重新定义了概念&#xff0c;更加模块化、组件化&#xff1a;
eBPF虚拟机成为 “IO Visor 运行时引擎”IO Visor 编译器后端”eBPF程序被重新命名为 “IO 模块” &#xff0c;例如&#xff1a;实现包过滤器的特定 eBPF 程序称为 “IO 数据平面模块/组件”等等IOVisor 项目创建了 Hover 框架&#xff0c;也被称为 “IO 模块管理器”&#xff0c;专门用于管理eBPF程序/IO模块的用户空间的后台服务程序, 目标是类似于Docker daemon发布/获取镜像的方式, 能够将IO模块推送和拉取到云端&#xff0c;分发和部署到多台主机BPF运行时模块组成&#xff1f;JIT即时编译器&#xff1a;将BPF指令动态的转换为本地化指令verifer验证器&#xff1a;用于eBPF程序指令的安全检查, 保护内核安全eBPF可观测性方向基础eBPF可观测性的术语目前eBPF应用领域分别是网络、可观测性、安全。对于可观测性有以下术语解释&#xff1a;
trace、snoop: 基于事件的跟踪&#xff0c;记录追踪系统发生的一系列事件sampling、profiling: 通过获取全部观测信息的子集&#xff08;定时采样&#xff09;来描绘大值的图像&#xff1b; 采样工具的优点在于性能开销比跟踪工具小&#xff0c;缺点就在于可能会遗漏部分关键事件observability&#xff1a;通过全面观测来理解一个系统&#xff0c;只要可以实现此目标就可归为此类&#xff1b;上面两种和固定计数器工具都包括在其内&#xff0c;但是不包括基准(benchmark)测量工具libbcc、libbpf的理解&#xff1f;基于这两个基础库分别实现了&#xff1a;BCC、bpftrace, libbpf目前已经是内核代码的一部分
eBPF与传统的性能分析工具的不同点&#xff1f;eBPF是在内核层面使用非常低的损耗实现观测&#xff0c;这与传统的用户态性能分析工具有着本质区别, &#xff1a;
eBPF同时具备高效率eBPF同时具备生产环境安全性特点eBPF已经在内核中&#xff0c;可以直接在生产环境中使用&#xff0c;无需添加新的内核组件为什么效率高&#xff1f;
举个例子&#xff0c;需要追踪当前内核I/O尺寸分布的数据&#xff0c;区别就在于&#xff1a;&#xff08;将工作都移植到到了内核中&#xff0c;减少内核、用户态之间数据复制量&#xff09;
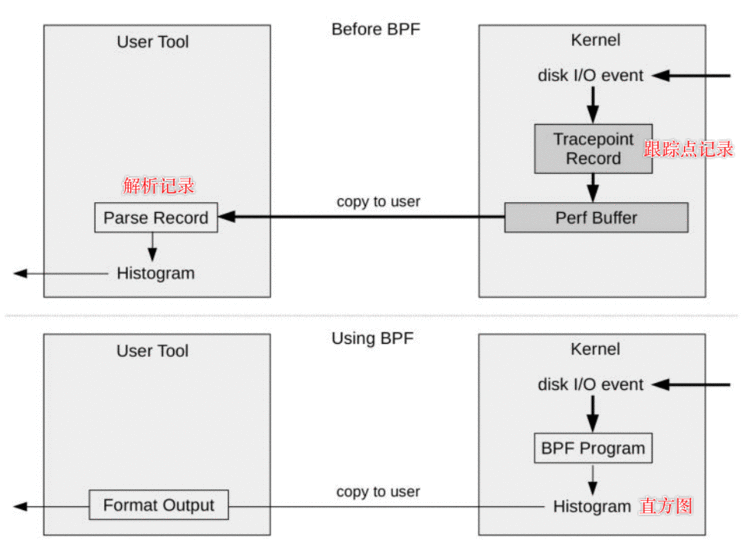
BPF&#xff1a;对于每个事件都需要向缓冲区中写一条记录到perf buffer, 然后用户程序周期性拷贝所有缓冲区数据到用户态生成直方图BPF: 对于每次事件&#xff0c;运行BPF程序&#xff0c;只获取字节字段&#xff0c;保存在自定义的Map映射数据结构中, 用户空间一次性读取BPF直方图映射表并输出结果效率提升显著&#xff0c;以至于工具的额外开销减小到可以在生产环境下直接使用
为什么安全&#xff1f;
BPF采用的验证器和受限的调用更加正规和安全相比于内核模块&#xff08;tracepoint、kprobes这些内核模块已经出现很多年了&#xff09;&#xff1a;
eBPF程序CO-RE一次编译到处运行&#xff0c;BPF指令集、映射表结构、辅助函数等相关基础设施都是稳定的ABI;(当然也包括不稳定的因素&#xff0c;例如kprobes&#xff0c;但是也有对应的解决方案)BPF程序的能力所以适用场景也有所区别:
BPF跟踪工具进一步分析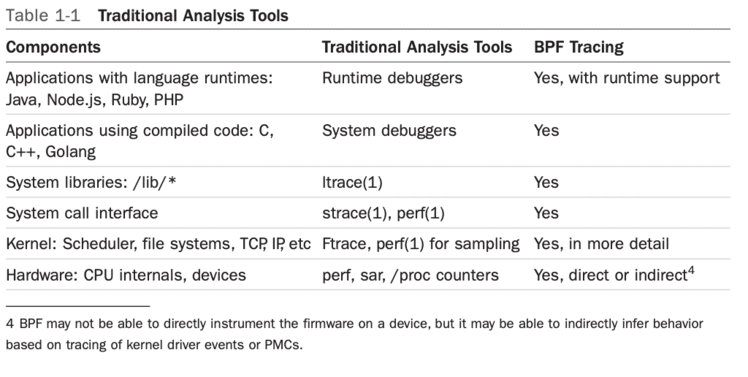
stack-trace)BPF的支持&#xff1a;
ORC的调用栈回溯信息一个惯例&#xff1a;
RBP中(x86_64)RBP的值指向的位置&#43;固定偏移量(&#43;8)追溯过程&#xff1a;


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有