先介绍下我们的druid集群配置
Overload 1台
Coordinator 1台
Middle manager 3台
Broker 3台
Historical一共12台,其中cold 6台,hot 6台
druid版本:0.10, 0.9之后即可支持Kafka indexing service
目前的druid主要用来做批量灌入,包括天级,小时级,五分钟级
由于这个五分钟是一个小时前的五分钟,实时性不能满足需求,无法指导广告主实时投放
需要引入分钟级的实时数据,即广告主在投放一分钟之后就能看到投放的展现点击等指标数据,从而指导广告主投放
业务维度字段主要有
uid campaign_id plan_id mid posid
指标字段主要有
impressions clicks installs revenue
由于transqulity有数据丢失风险,所以我们拟采用kafka indexing service
1.打开druid的extensions目录,这个插件已经自带
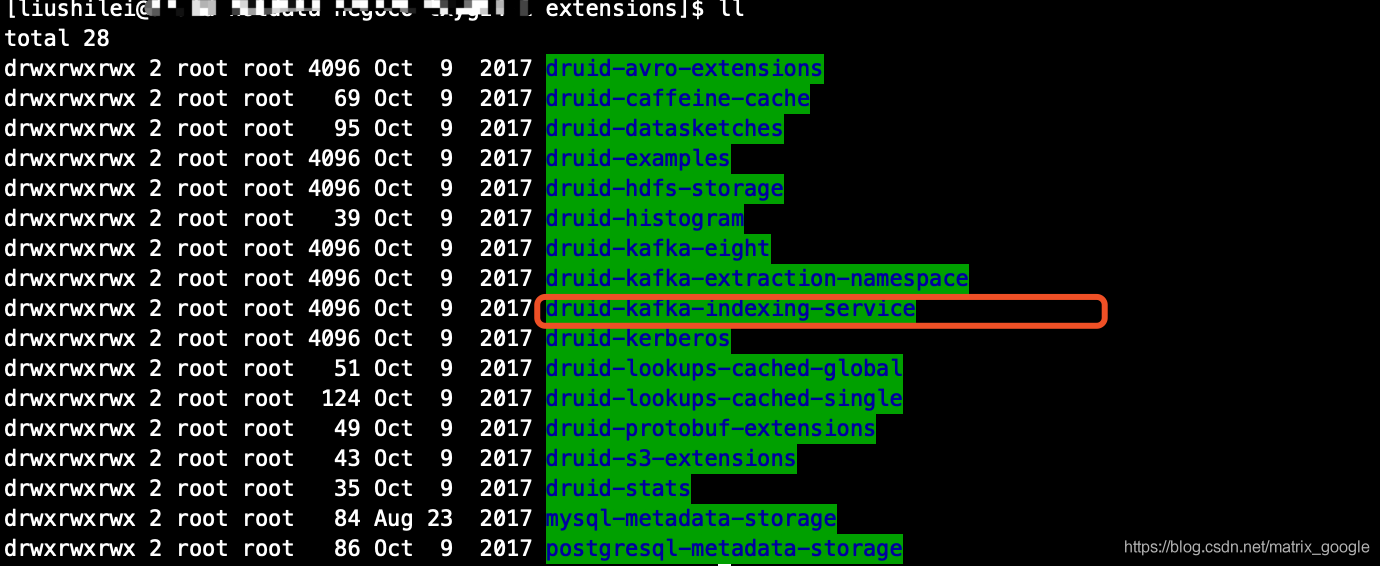
2.在overload和middleManager上配置loadList,注意overload节点和middleManager节点都要配置,其他节点不需要
名称千万不能写错 "druid-kafka-indexing-service"

3.重启overload和middleManager
关闭服务
ps -ef |grep druid
kill -9 pid
打开服务
nohup java `cat conf/druid/overlord/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/overlord:lib/*" io.druid.cli.Main server overlord > /new_orion/druid/druid_start_log/ip/overlord/overlord.out &
把这行命令存成一个脚本,每次打开服务用这个脚本
4.配置supervisor.json
灌库用的tsv文件,下面给出一个json范例
{
"type": "kafka",
"dataSchema": {
"dataSource": "realtime_detail_min",
"parser": {
"type": "string",
"parseSpec": {
"format": "tsv",
"delimiter": "\t",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"columns": [
"timestamp",
"pkgname",
"country",
"impressions",
"clicks"
],
"dimensionsSpec": {
"dimensions": [
"pkgname",
"country"
],
"dimensionExclusions": []
}
}
},
"metricsSpec": [
{
"type": "longSum",
"name": "impressions",
"fieldName": "impressions"
},
{
"type": "longSum",
"name": "clicks",
"fieldName": "clicks"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "MINUTE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 5000000
},
"ioConfig": {
"topic": "druid_detail_time_minute",
"consumerProperties": {
"bootstrap.servers": "ip:9092",
"group.id": "consumer_druid"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT1H"
}
}
注意:
1.如果用的tsv或者csv文件,一定要设置columns,灌数字段顺序要和这个完全一致
2.segmentGranularity表示落盘成数据段的单位,这个一般不要设置太小,一个小时或者一天
queryGranularity表示查询的最小维度
3.maxRowsPerSegment 表示一个segment最大数据行数,taskDuration表示多久持久化一次数据
比如我想一个小时落盘一次数据,但是一个小时我们能生成800万行数据,那就把maxRowsPerSegment赋值为1000万
4.taskCount replicas这两个字段也很重要,参照官网,如果阅读英文费劲,可以参考阿里云官网
5.启动superviosr
curl -X POST -H 'Content-Type: application/json' -d @supervisor-spec.jsonhttp://localhost:8090/druid/indexer/v1/supervisor
6.访问overload控制台如下

点击status查看所有分区的消费进度


注意在启动supervisor消费之前,一定要保证overload机器和middleManager节点一定能访问kafka
我们还有一套阿里云的druid, 但我们的kafka是腾讯的,用阿里云的druid消费腾讯的kafka
一切正常就是不消费,lag一直在堆积,后来阿里云同学说你们买的druid只能访问你们买的其他几台内网地址,如果想要访问外网地址,需要配置vpn,然后我问为啥latesetOffset一直增加呢,回答overload节点能访问kafka,但是middleManager真正做消费的访问不到,所以不确定overload和middleManager能否访问kafka的情况下,就在这些机器上装个单机版的kafka,用命令行消费一下
./kafka-console-consumer --bootstrap-serverckafka.com:6170 --group consumer_druid --topic druid_detail_time_minute
注意执行这条命令不需要配置和启动kafka,进入bin目录直接执行即可
附上下载kafka的命令
wgethttp://labfile.oss.aliyuncs.com/courses/859/kafka_2.10-0.10.2.1.tgz
7.在coordinator页面观察数据是否正确生成
一定要设置rules,数据才能正常展示








 京公网安备 11010802041100号
京公网安备 11010802041100号