docker容器技术能够隔离资源、文件、网络等, 底层原理正是使用liunx的隔离机制, 主要是通过下面3种技术:
| 技术 | 隔离
|
namespace资源隔离
| namespace实现资源隔离; |
cgroups资源限制
| 实现资源限制, 主要是限制:
cpu使用率 内存使用率 网络IO等使用率
|
| overlay联合文件挂载系统 | 联合文件挂载系统
|
1.Namespace资源隔离
Linux 命名空间对全局操作系统资源进行了抽象,对于命名空间内的进程来说,他们拥有独立的资源实例,在命名空间内部的进程可以实现资源可见。
对于命名空间外部的进程,则不可见,实现了资源的隔离。
Namespace实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容.
对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有区别。
举例来说:现在有两个进程A,B。他们处于两个不同的 PID Namespace 下:ns1, ns2。在ns1下,A 进程的 PID 可以被设置为1,在 ns2 下,B 进程的 PID 也可以设置为1。但是它们两个并不会冲突,因为 Linux PID Namespace 对 PID 这个资源在进程 A,B 之间做了隔离。A 进程在 ns1下是不知道 B 进程在 ns2 下面的 PID 的。
这种环境隔离机制是实现容器技术的基础。因为在整个操作系统的视角下,一个容器表现出来的就是一个进程。
思考
| 隔离方向
|
1. 容器需要操作文件, 但是不能影响到宿主机
| 文件隔离, 如chroot
|
2. 通信和定位,容器必须有独立的IP/端口/路由
| 网络隔离
|
3. 网络之间需要通信
| 进程间通信隔离
|
4. 权限的问题
| 用户权限隔离
|
5. 容器中运行程序需要有自己进程号
| 需要与宿主机PID隔离
|
6. 容器需要有自己主机名和域名(容器可以看成伪虚拟机)
| 主机名隔离
|
linux正好提供以上6种隔离机制, 在这6种隔离机制下,容器应运而生.
liunx6种隔离机制
linux6种隔离机制
namespace
| 隔离内容
|
UTS
| 主机名和域名的隔离: 每个容器都有自己的主机名和域名,在网络上可以视为一个节点,而非宿主机上的一个进程 容器内部可以自定义自己主机名和域名,不会对宿主机和其它容器够成影响; docker常用镜像名来命名主机名
|
IPC
| 信号量,消息队列和共享内存:
1. 实现容器和宿主机通信隔离;
2. 容器和容器间通信隔离; |
PID
| 进程隔离:
1. 两个不同namespace下可以有相同的PID;
2. 内核为所有的PID维护一个树状结构,根节点是init(systemd);
3. 父进程会对子namespace下的进程进行重新标号,并维护一个对应关系;
4. 父节点可以看到子节点东西,并通过信号等方式对子节点的进程产生影响,但是子节点却不能看到父节点namespace下的任何东西.
|
Network
| 网络设备,网络栈,端口等
|
Mount
| 挂载点(文件系统隔离)
|
User
| 用户和用户组
|
|
|
通过/proc文件查看已存在的Namespace
在3.8内核开始,用户可以在/proc/$pid/ns文件下看到本进程所属的Namespace的文件信息。例如PID为2704进程的情况如下图所示:
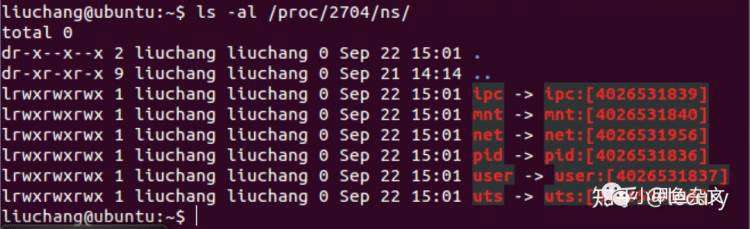 其中 4026531839 表明是Namespace的ID,如果两个进程的Namespace ID相同表明两个进程同处于一个命名空间中。
其中 4026531839 表明是Namespace的ID,如果两个进程的Namespace ID相同表明两个进程同处于一个命名空间中。
1. PID namespace:
1. 每个PID namespace中的第一个进程“PID 1”,都会像传统linux的init进程一样
拥有特权,起特殊作用;
2. 一个namespace中进程,不能通过kill或ptrace影响父节点或者兄弟节点的进程,
因为其他节点的PID在这个namespace中没有任何意义;
3. 如果你的新PID namespace下重新挂载/proc文件系统,会发现其下只显示同属于
一个PID namespace中其他进程;
PID挂载:
* docker就是使用mount挂载到该namespace下面的 /proc中,
因此在docker中使用ps, 就只能看到该namespaces下的进程
并不是宿主机的所有进程.
4. root namespace可以看到所有的进程, 并且递归包含所有子节点的进程;
5. 在外部监控Docker中运行程序的方法,就是监控daemon所在的PID namespace下
的进程及其子进程.
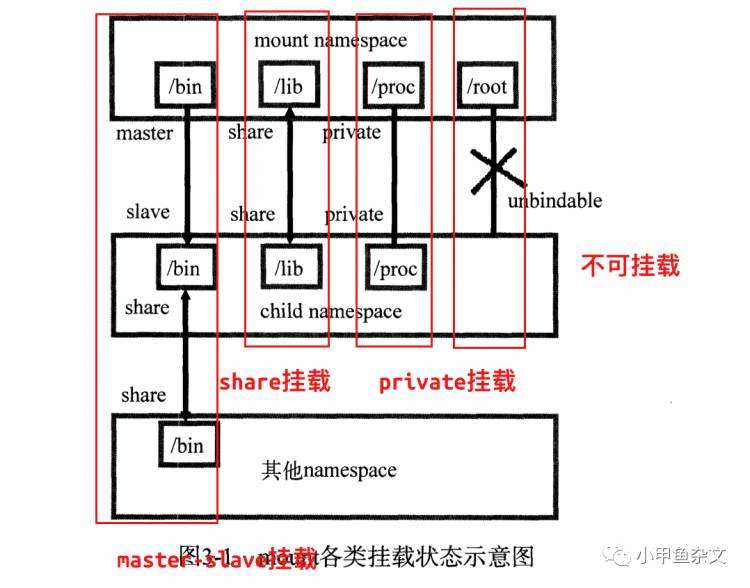
2. mount namespace:
mount既可以挂载进程,也可以挂载文件系统, 使在docker中只能看到自己docker中文件.下图是mount文件系统常用的挂载方式
3. network namespace:
network namespce主要提供关于网络资源的隔离,包括网络设备,IPv4/IPv6协议栈,
IP路由表、防火墙、/proc/net目录、/sys/class/net目录、套接字(socker)等,一个物理的网络设备最多存在于一个network namespace下,可以通过创建veth pair(虚拟网络设备对:有两端类似于管道)在不同的namespace下创建管道, 以达到通信的目的.
下图是docker网络架构图
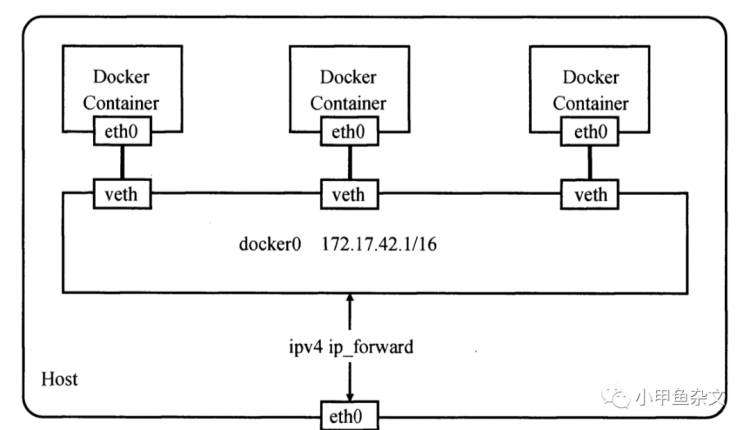
下面的eth0为宿主机物理网卡,当docker-daemon进程创建后,会创建一个docker0,
当docker-daemon创建容器时, 首先init进程会在docker0上创建一个veth,并绑定到docker0上,另一端会在新建的namespace(创建的容器)下创建eth0, 在veth <-->
eth0打通之前会通过pipe(管道)进行交互,直到建立连接.
4. user namespace:
user namespce主要隔离安全相关的标识符(identifier)和属性(attribute),包括用户ID和用户组ID、root目录、key(指密钥)以及特殊权限.通俗的讲:一个普通用户的进程通过clone()创建的新进程在新user-namespace下可以拥有不同的用户和用户组.这意味着一个进程在容器外属于一个没有特殊权限的普通用户,但是它创建的容器进程中确实一个拥有所有权限的超级用户.
namespace映射图:
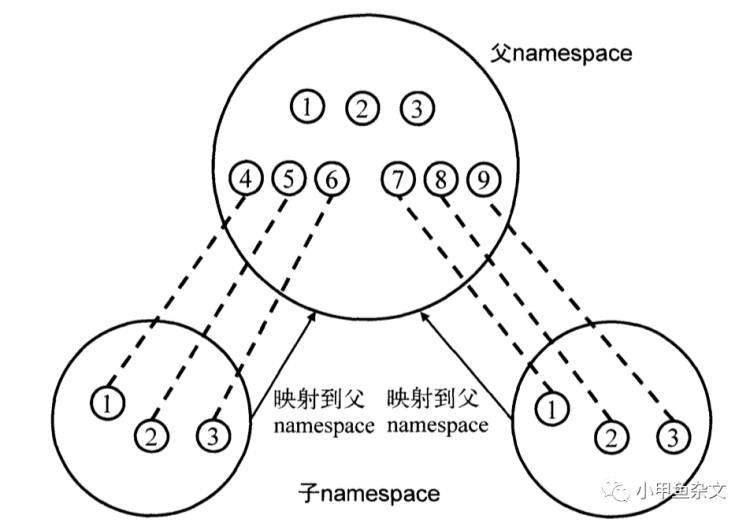
假设上图中1为 init进程, 在父namespace下, 这个进程可能是普通进程(4、7)但是到了子namespace下就变成了超级进程(1-init)
user-namespace被创建后, 第一个进程被赋予了该namespace中所有的权限,这样该init进程就可以完成所必要的初始化工作,而不会因权限不足出现错误.
docker中init通常为bash进程
5. IPC namespace:
进程间通信涉及的IPC资源包括常见的信号量、消息队列和共享内存.申请IPC资源就申请了一个全局唯一的32位ID, 所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统.在同一个IPC namespace下进程彼此可见, 不同IPC namespace下进程彼此不可见.
目前使用IPC namespace机制的系统不多,其中比较有名的有PostgreSQL, Docker当前也使用IPC namespace实现了容器与宿主机、容器与容器之间的隔离.
6. UTS namespace:
UTS namespace提供了主机名和域名的隔离,这样每个Docker容器就可以拥有独立的主机名和域名, 在网络上可以视为一个独立的节点, 而非宿主机上的一个进程. Docker中, 每个镜像基本都以自身提供的服务名称来命名镜像的hostname,且不会对宿主机产生任何影响, 其原理就是运用了UTS namespace技术.
将来还可能支持的隔离技术:
7.Cgroup Namespace
Cgroup是对进程的cgroup视图虚拟化。 每个 cgroup 命名空间都有自己的一组 cgroup 根目录。Linux 4.6开始支持。
cgroup 命名空间提供的虚拟化有多种用途:
8.Time Namespace
虚拟化两个系统时钟,用于隔离时间。 linux 5.7内核开始支持.
到此为止,Linux Namespace 的隔离机制就全部介绍完了。它是容器技术中「隔离机制」的基础。其实对于这些隔离机制来说,如果想理解透彻,还是要仔细琢磨 Namespace 的概念。这个概念在很多编程语言中都有出现。如果从最简单的字面意思上来理解的话,它就是一个名字空间。不同空间中可以有同一个标识,但是同一个空间中不能出现两个同样的标识。而上面所提到的 PID,Hostname,UID/GID 等等其实本质上都是一种名字的隔离,只有 Network 的部分比较特殊。尤其是在理解 Mount 隔离机制的时候,一定不要忘记一点:我们所做的一切操作都是在宿主机的文件系统上的,隔离的仅仅只是挂载点的记录而已。
Linux Namespace 的隔离,说到底还是一个逻辑上的概念,它不能切断任何进程和操作系统的链接,所以再怎么隔离是也不彻底的。不同容器或者说进程依赖的都是操作系统的资源,稍有不慎,一些操作还是会影响宿主机系统的。










 京公网安备 11010802041100号
京公网安备 11010802041100号