之前老有朋友跟我说有没有Docker+其他技术完整得执行流程啊,体验一下做项目得感觉是什么样,但是说实话,我实在是无能为力,虽然公司内部确实用到了Docker得相关内容,但是你要说让我摘出来,那真的是有点为难我了,实在是没那个精力,我也就没有去做这件事
但是,最近刚好家里在读大学的小侄子(纯辈分大),他有一个实验项目,需要用到Docker,这一天,这不是现成得实例 啊,这里就给大家完整得展示一下,有需要的朋友也可以对比着实际操作一下
实验目的
Understanding the concept of message passing
Trying to follow up the procedure of a message broker that handles message from many tenants Repeating what others have done in the past sheds the light on your future
实验步骤
已安装docker,系统是Ubuntu
安装docker-compose
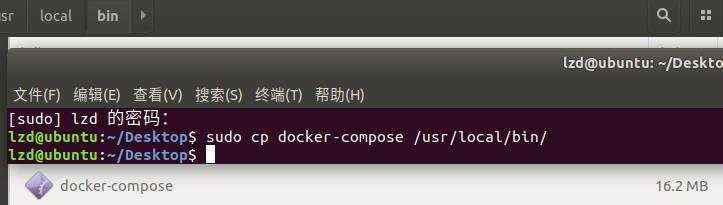
1. 下载最新版本 (v1.24.0) docker-compose
$ sudo curl -L "http://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname-s)-$(uname -m)" -o /usr/local/bin/docker-compose
ps:网速真心慢,建议直接从github(链接:https://github.com/docker/machine/releases/download/v0.16.1/docker- machine-Linux-x86_64)下载,把文件名改成docker-compose,再移动到/usr/local/bin/下。为什么这样做,你可以百度下curl -o 的作用。
注意 : 使用curl,url应该以http,不是https。使用https可能会超出时间或拒绝连接

2. 给已下载的docker-compose文件执行权限
$ sudo chmod +x /usr/local/bin/docker-compose
3. Install command completion for the bash and zsh shell.
$ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
4. 检查docker-compose版本

$ docker-compose --versiondocker-compose version 1.24.0, build 0aa59064
安装docker-maceine
提示: 你可以按照官网的步骤使用curl下载docker文件,但网速太慢。建议和我一样(和下载docker-compose 建议一样)从github下载,并改名成docker-machine。移动到/tmp下。
官网shell:
$ base=https://github.com/docker/machine/releases/download/v0.16.0 &&curl -L $base/docker-machine-$(uname -s)-$(uname -m) >/tmp/docker-machine && sudo install /tmp/docker-machine /usr/local/bin/docker-machine
但是年轻人没有性格怎么可以,我的步骤如下:
1. 从github下载docker-machine所需文件
文件链接:https://github.com/docker/machine/releases/download/v0.16.1/docker-machine-Linux- x86_64
2. 文件改名成docker-machine,并移动到/tmp文件夹下
3. 安装docker-machine
$ sudo install /tmp/docker-machine /usr/local/bin/docker-machine
4. 查看docker-machine版本

$ docker-machine version
1. 虽然也可以直接安装deb包,但毕竟懒,添加源可以保持更新
$ sed -i '$adeb http://download.virtualbox.org/virtualbox/debian xenial contrib'/etc/apt/sources.list
2. 为apt-secure导入公钥

$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
3. 通过apt安装VirtualBox
$ sudo apt-get update$ sudo apt-get install virtualbox-6.0
这里可能会有安装包冲突问题
lzd@ubuntu:~$ sudo apt-get install virtualbox-6.0正在读取软件包列表... 完成正在分析软件包的依赖关系树正在读取状态信息... 完成有一些软件包无法被安装。如果您用的是 unstable 发行版,这也许是因为系统无法达到您要求的状态造成的。该版本中可能会有一些您需要的软件包尚未被创建或是它们已被从新到(Incoming)目录移出。下列信息可能会对解决问题有所帮助:下列软件包有未满足的依赖关系:virtualbox-6.0 : 依赖: libcurl3 (>= 7.16.2) 但是它将不会被安装依赖: libpng12-0 (>= 1.2.13-4) 但无法安装它依赖: libvpx3 (>= 1.5.0) 但无法安装它推荐: libsdl-ttf2.0-0 但是它将不会被安装E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破坏了软件包间的依赖关系。
解决方案
如遇到此问题,使用 aptitude 代替 apt-get 安装 virtualbox-6.0
$ sudo aptitude install virtualbox-6.
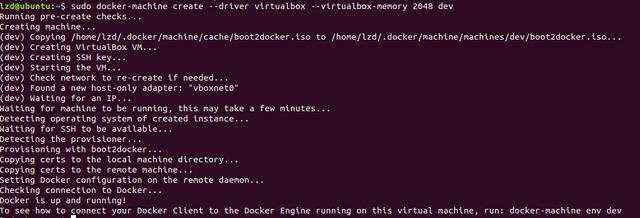
$ docker-machine create --driver virtualbox --virtualbox-memory 2048 dev
发现执行这步不行,会出现下面这个问题
lzd@ubuntu:~$ docker-machine create --driver virtualbox --virtualbox-memory 2048 devRunning pre-create checks...Error with pre-create check: "VBoxManage not found. Make sure VirtualBox is installed and VBoxManage is in the path"
解决方案
@Dreampie, @Aaqib041 can you install the virtualbox : sudo apt-get install virtualboxthen run this command:docker-machine create --driver virtualbox default
按照这个方法执行完后,成功创建 dev VM
1. 安装sbt
安装sbt前,先安装jdk将下载的压缩包解压到/usr/local/目录下
tar -zxvf sbt-1.2.8.tgz -C /usr/local/sbt
在/usr/local/sbt/目录下创建sbt文件
$ cd /usr/local/sbt$ vim sbt
在sbt文件中写入以下内容
#!/bin/bashBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled - XX:MaxPermSize=256M"java $SBT_OPTS -jar /usr/local/sbt/bin/sbt-launch.jar "$@"
注意sbt-launch.jar的目录是否正确修改sbt文件的权限
$ chmod u+x sbt
配置sbt环境变量
$ vim /etc/profile
在最后一行添加一些内容
export PATH=/usr/local/sbt/bin:$PATH
然后运行使文件生效
$ source /etc/profile
修改sbt路径下的sbtconfig.txt文件
$ vim /usr/local/sbt/conf/sbtconfig.txt
添加以下内容
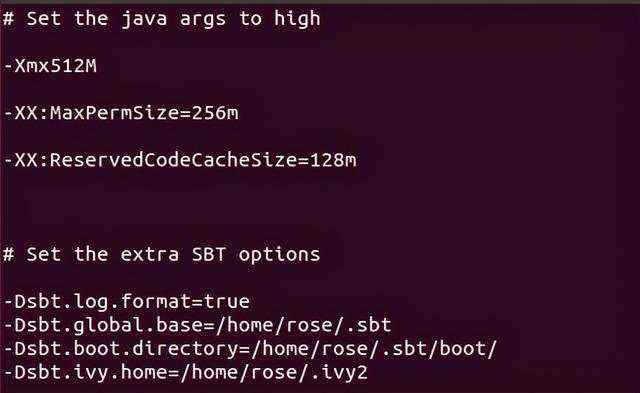
-Dsbt.global.base=/home/rose/.sbt-Dsbt.boot.directory=/home/rose/.sbt/boot/-Dsbt.ivy.home=/home/rose/.ivy2
检查sbt是否安装成功(这里需要联网,会下载东西)
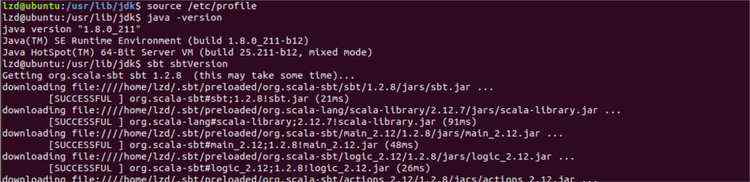
$ sbt sbt-verison
2. 使用sbt构建项目
首先需要为项目设置sbt目录结构(遗憾的是,sbt它不提供引导项目的命令),这里使用脚本设置目录结构。
shell代码如下:
脚本文件命名为 sbt-init.sh ,使用脚本创建sbt项目 3. 新建文件assembly.sbt 4. 新建配置文件build.sbt 6. 在项目src/main/scala/com/example/spark目录下新建DirectKafkaWordCount.scala文件写入 7. 运行sbt语句&#xff0c;得到文件 1. 使用 dev Docker客户端 2. 使用docker-compose.yml文件配置docker-compose 写入如下配置信息 执行docker-compose.yml文件启动所有容器 这将启动kafka然后spark并将我们记录到spark容器shell中。--rm标志使得在运行后docker-compose删除相应的spark容器 3. 配置 kafka 容器 进入 kafka 容器 在kafka里添加topic word-count 检查此topic是否加入 4. 配置 spark 容器新开一个终端 进入 spark 容器 执行以下语句 ps:这里要指定 driver-memory 大小&#xff0c;要不然使用默认值 4G。 试验中就会报错。错误如下&#xff1a; 启动 zookeeper 查看 zookeeper 运行结果 Service status Create the input topic Create the output topic Describe them 结果如下#!/bin/bashif [ -z "$1" ] ; thenecho &#39;Project name is empty&#39; exit 1fiPROJECT_NAME&#61;"$1" SCALA_VERSION&#61;"${2-2.11.8}" SCALATEST_VERSION&#61;"${3-2.2.6}"mkdir $PROJECT_NAME cd $PROJECT_NAMEcat > build.sbt <sudo ./sbt-init.sh exampleaddSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.13.0")name :&#61; "direct_kafka_word_count" scalaVersion :&#61; "2.10.5"val sparkVersion &#61; "1.5.1"libraryDependencies &#43;&#43;&#61; Seq("org.apache.spark" %% "spark-core" % sparkVersion % "provided", "org.apache.spark" %% "spark-streaming" % sparkVersion % "provided", ("org.apache.spark" %% "spark-streaming-kafka" % sparkVersion) exclude("org.spark-project.spark", "unused"))assemblyJarName in assembly :&#61; name.value &#43; ".jar"package com.example.sparkimport kafka.serializer.StringDecoderimport org.apache.spark.{TaskContext, SparkConf}import org.apache.spark.streaming.kafka.{OffsetRange, HasOffsetRanges, KafkaUtils} import org.apache.spark.streaming.{Seconds, StreamingContext}object DirectKafkaWordCount {def main(args: Array[String]): Unit &#61; { if (args.length <2) {System.err.println(s"""|Usage: DirectKafkaWordCount | is a list of one or more Kafka brokers| is a list of one or more kafka topics to consume from| """.stripMargin)System.exit(1)}val Array(brokers, topics) &#61; args// Create context with 10 second batch intervalval sparkConf &#61; new SparkConf().setAppName("DirectKafkaWordCount") val ssc &#61; new StreamingContext(sparkConf, Seconds(10))// Create direct kafka stream with brokers and topics val topicsSet &#61; topics.split(",").toSetval kafkaParams &#61; Map[String, String]("metadata.broker.list" -> brokers) val messages &#61; KafkaUtils.createDirectStream[String, String, StringDecoder,StringDecoder](ssc, kafkaParams, topicsSet)// Get the lines, split them into words, count the words and print val lines &#61; messages.map(_._2)val words &#61; lines.flatMap(_.split(" "))val wordCounts &#61; words.map(x &#61;> (x, 1L)).reduceByKey(_ &#43; _) wordCounts.print()// Start the computation ssc.start() ssc.awaitTermination()}}sbt assembly4. 配置容器
$ eval "$(docker-machine env dev)"$ mkdir -p /home/lzd/myDocker-6/$ cd /home/lzd/myDocker-6/$ touch docker-compose.yml$ chmod &#43;rwx docker-compose.ymlkafka:image: antlypls/kafka-legacy environment:· KAFKA&#61;localhost:9092· ZOOKEEPER&#61;localhost:2181 expose:- "2181"- "9092"spark:image: antlypls/spark:1.5.1 command: bashvolumes:· ./target/scala-2.10:/app links:- kafkadocker-compose run --rm spark$ docker-compose run --rm sparkCreate a topic in a kafka broker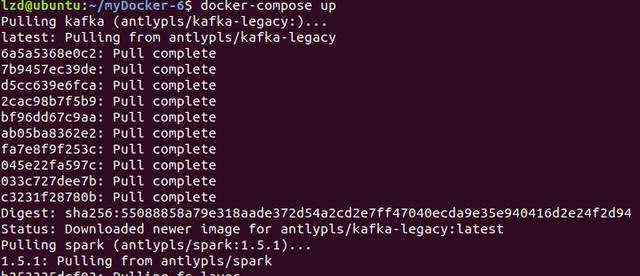
$ docker exec -it bash
$ kafka-topics.sh --create --zookeeper $ZOOKEEPER --replication-factor 1 -- partitions 2 --topic word-count
$ kafka-topics.sh --list --zookeeper $ZOOKEEPER$ kafka-topics.sh --describe --zookeeper $ZOOKEEPER --topic word-countdocker exec -it bashspark-submit --master yarn-client --driver-memory 1G --class com.example.spark.DirectKafkaWordCount app/direct_kafka_word_count.jar kafka:9092 word-countJava HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000d5550000, 715849728, 0) failed; error&#61;&#39;Cannot allocate memory&#39; (errno&#61;12)## There is insufficient memory for the Java Runtime Environment to continue.# Native memory allocation (mmap) failed to map 715849728 bytes for committing reserved memory.# An error report file with more information is saved as: # /hs_err_pid16414.log2. Kafka - Stream Word Count demo
1. 启动 zookeeper 和 broker
$ docker run -d --net&#61;host --name&#61;zookeeper -e ZOOKEEPER_CLIENT_PORT&#61;32181 confluentinc/cp-zookeeper:latest
docker logs zookeeper | grep -i binding- cd /kafka/docker/streamexport COMPOSE_PROJECT_NAME&#61;"stream-demo" docker-compose up -d
Creating network "streamdemo_default" with the default driver Creating streamdemo_zookeeper_1 ...Creating streamdemo_zookeeper_1 ... done Creating streamdemo_broker_1 ...Creating streamdemo_broker_1 ... donedocker-compose ps2. Create a topic
docker-compose exec broker bash kafka-topics --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic streams-plaintext-inputkafka-topics --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic streams-wordcount-output --config cleanup.policy&#61;compactkafka-topics --zookeeper zookeeper:2181 --describeTopic:streams-plaintext-inputConfigs:PartitionCount:1ReplicationFactor:1Topic: streams-plaintext-input Partition: 0Isr: 1Leader: 1Replicas: 1Topic:streams-wordcount-output PartitionCount:1Configs:cleanup.policy&#61;compactTopic: streams-wordcount-output Partition: 0ReplicationFactor:1Leader: 1Replicas:1 Isr: 1




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
